비트 중요도 기반 오류 정정: 베이즈 디코더와 반복 최적화 코드북 설계
본 논문은 비트별 중요도가 서로 다른 상황을 고려해, 전통적인 BER 대신 소스 심볼 차이를 측정하는 손실 함수를 도입한다. 베이즈 추정기를 활용한 최적 디코더와, 유전 알고리즘·힐클라이밍 등 반복적 탐색 기법으로 설계한 일반·선형 코드북을 제안한다. 실험 결과, 제안 방식은 동일 길이의 해밍(7,4) 코드보다 정수 평균오차와 제곱오차 지표에서 우수함을 보이며, ECC가 불가능한 경우에도 비트 중요도 기반 숫자 표현을 통해 평균 오류를 감소시킨…
저자: Chai Wah Wu
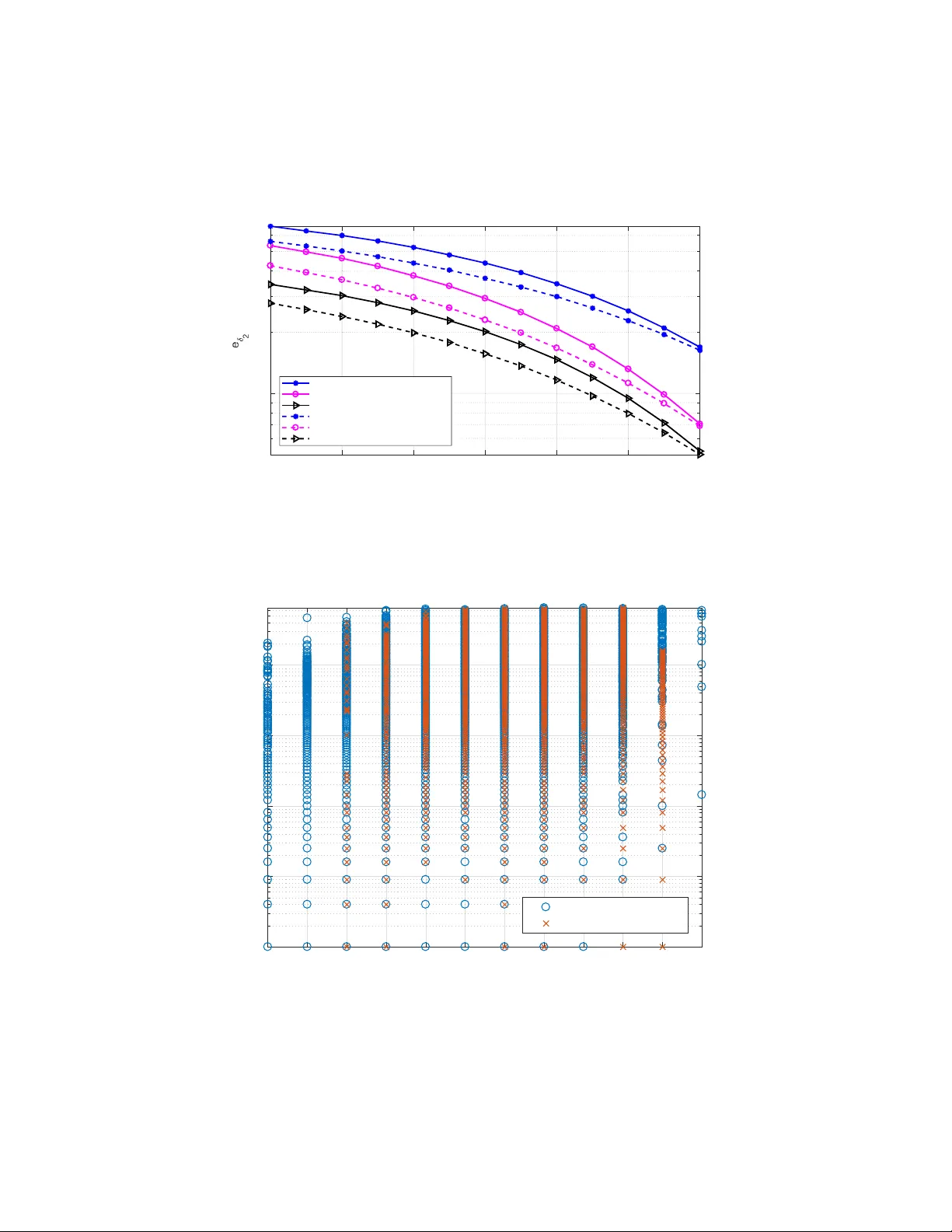
본 논문은 통신·저장 시스템에서 비트마다 중요도가 다르게 부여되는 현실적인 요구를 반영하여, 전통적인 비트 오류율(BER) 대신 소스 심볼 간 차이를 측정하는 손실 함수 δ(s,ŝ)를 도입한다. 저자는 먼저 정수 표현을 예시로, 가장 높은 비트가 오류를 일으킬 경우 전체 값에 미치는 영향을 강조한다. 이를 정량화하기 위해 δ₁=|bₖ(s)−bₖ(ŝ)|와 δ₂=(bₖ(s)−bₖ(ŝ))²와 같은 절대 차 및 제곱 차 손실을 정의한다.
다음으로 베이즈 추정 이론을 적용한다. 사후 확률 p(s|c′)와 손실 함수 L(s,ŝ) 사이의 기대 손실을 최소화하는 디코더를 설계한다. 손실이 0‑1이면 MAP 디코더, 제곱오차이면 평균값, 절대값이면 중앙값이 최적임을 보이며, δ₁·δ₂와 같은 비선형 손실에 대해서는 해당 손실을 그대로 사용한 베이즈 디코더가 최적임을 증명한다.
코드북 설계는 비선형 최적화 문제로 전환된다. 목표 함수 v=∑_{i≠j}δ(s_i,s_j)·p_c(Φ(s_i)|Φ(s_j))는 모든 심볼 쌍에 대해 평균 오류를 추정한다. AWGN 채널에서는 p_c∝exp(−d_H²/2σ²) 형태가 되므로, v는 Hamming 거리와 δ의 가중합으로 표현된다. 전통적인 선형 코드 설계(예: 해밍 코드)는 Hamming 거리만을 최적화하므로 δ 기반 목표와는 불일치한다.
저자는 유전 알고리즘(GA)과 힐클라이밍 등 AI 기반 탐색 기법을 사용해 코드북을 최적화한다. GA에서는 전체 코드북을 하나의 염색체로 보고, 1‑포인트 교차와 스와프 변이를 적용한다. 실험 결과, GA가 힐클라이밍보다 낮은 v 값을 얻었으며, 최적화된 코드북은 행(코드워드) 순열에 민감함을 보인다. 이는 비트 중요도 손실이 코드워드 간 Hamming 거리를 비선형적으로 가중하기 때문이다.
성능 평가는 (4,7) 비율의 블록 코드를 대상으로 한다. 최적화된 코드북과 베이즈 디코더, 소프트 디코딩, 하드 디코딩을 비교했으며, δ₁(절대 차)와 δ₂(제곱 차) 두 지표 모두에서 최적화된 코드북+베이즈 디코더 조합이 가장 낮은 오류를 기록했다. 특히, 해밍(7,4) 코드는 Hamming 거리 기준에서는 최적이지만, δ 기반 지표에서는 열등함을 확인했다. 소프트 디코딩이 하드 디코딩보다 우수하고, 베이즈 디코딩이 가장 좋은 결과를 보였다.
또한 ECC가 적용되지 못하는 경우를 위해, 비트 중요도를 반영한 새로운 숫자 표현 방식을 제안한다. 이 방식은 노이즈 크기가 크거나 채널 특성을 알기 어려운 저장 매체에서 전통적인 2진 표현보다 평균 정수 오차를 낮추는 효과를 보이며, 향후 비정형 저장 매체에 적용 가능성을 시사한다.
결론적으로, 논문은 “비트 중요도 기반 손실 함수 → 베이즈 최적 디코더 → 반복적 코드북 탐색”이라는 흐름을 통해 기존 BER 중심 설계와는 다른 새로운 오류 정정 패러다임을 제시한다. 이는 비트별 가중치를 고려한 통신·저장 시스템 설계에 중요한 통찰을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기