엣지 AI 가속기 병목 해소와 멘사 프레임워크
초록
본 논문은 구글 Edge TPU가 24개의 최신 엣지 신경망 모델을 실행할 때 발생하는 처리량·에너지·메모리 병목을 정밀 분석하고, 레이어 특성에 따라 최적화된 소형 가속기 3종을 조합해 동작하는 멘사(Mensa) 프레임워크를 제안한다. 멘사는 레이어별 스케줄링을 통해 평균 3배 이상의 에너지 효율과 처리량 향상을 달성한다.
상세 분석
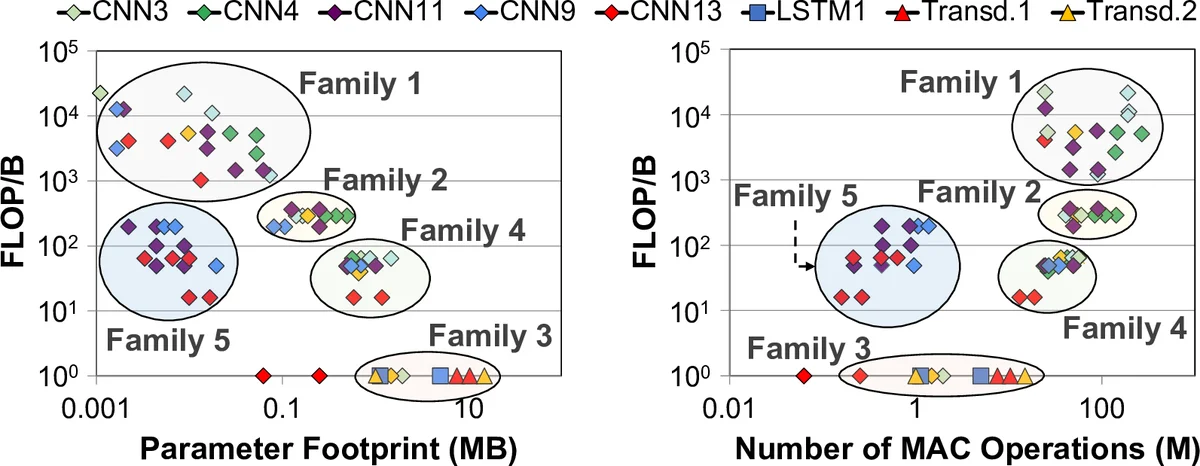
본 연구는 상용 Edge TPU(64×64 PE 배열, 대용량 SRAM 버퍼)를 대상으로 24개의 구글 엣지 전용 신경망 모델(CNN, LSTM, 트랜스듀서, RCNN)을 레이어 단위로 정밀 측정하였다. 분석 결과, TPU는 세 가지 근본적인 한계를 보였다. 첫째, 피크 연산량 대비 평균 24 % 수준으로 활용도가 현저히 낮았다. 특히 LSTM·트랜스듀서와 같은 시계열 레이어는 1 % 이하의 활용률을 기록했다. 이는 고정된 PE 배열과 고정 데이터 흐름이 레이어별 연산 강도·데이터 재사용 패턴에 맞추어 최적화되지 못했기 때문이다. 둘째, 이론적 TFLOP/J 대비 실제 에너지 효율은 평균 37 %에 불과했으며, 최악의 경우 34 % 수준에 머물렀다. 대형 온칩 버퍼가 정적·동적 전력의 절반 이상을 차지했음에도 불구하고, 파라미터 전체를 수용하지 못해 오프칩 메모리 접근이 빈번히 발생, 메모리 대역폭이 포화되면서 전력 손실이 가중되었다. 셋째, 메모리 서브시스템 자체가 주요 병목으로 작용했다. 레이어마다 FLOP/Byte 비율과 파라미터 크기가 크게 달라, 동일한 버퍼·대역폭 설계가 일부 레이어에는 과잉, 일부 레이어에는 부족한 비대칭 구조를 초래했다.
이러한 현상을 해소하기 위해 저자들은 “멘사”라는 이종 가속기 프레임워크를 설계하였다. 핵심 아이디어는 (1) 레이어 특성(계산 중심 vs 메모리 중심, 파라미터·활성화 재사용 패턴) 기반으로 레이어를 소수의 클러스터로 그룹화하고, (2) 각 클러스터에 최적화된 전용 가속기(Pascal, Pavlov, Jacquard)를 배치한 뒤, (3) 런타임 스케줄러가 레이어 간 의존성과 데이터 이동 비용을 고려해 최적의 가속기로 할당하는 것이다.
Pascal은 고연산량 컨볼루션 레이어에 적합하도록 대규모 PE 배열과 출력 고정 데이터 흐름을 유지하되, 버퍼 크기를 16배 축소하고 온칩 네트워크 트래픽을 최소화한다. Pavlov은 LSTM‑계열 레이어에 특화돼 시간축 파라미터 재사용을 극대화하고, 출력 활성화를 단계별 축소함으로써 오프칩 메모리 접근을 크게 감소시킨다. Jacquard는 파라미터 중심의 레이어(예: 완전 연결, depthwise)용으로 파라미터 버퍼를 32배 축소하고, 파라미터 재사용을 위한 데이터 흐름을 채택한다. 두 데이터 중심 가속기는 3D‑스택 메모리 로직 레이어에 배치해 작은 PE 배열을 사용함으로써 전력·면적 효율을 크게 높였다.
실험 결과, 멘사‑G(위 세 가속기 조합)는 전체 24개 모델에 대해 평균 에너지 소비를 66 % 절감하고, TFLOP/J 기준 3배, TFLOP/s 기준 3.1배의 향상을 달성했다. 또한, 최신 재구성형 가속기인 Eyeriss v2 대비도 에너지 효율 2.4배, 처리량 4.3배 개선되었다. 이러한 성과는 엣지 환경에서 다양한 모델·레이어 특성을 고려한 이종 가속기 설계가 기존의 일괄형 가속기보다 훨씬 효율적임을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기