시간코드 딥 스파이킹 신경망 손쉬운 학습과 강인한 성능
본 논문은 비누출 적분‑발화(Non‑leaky IF) 뉴런과 단일 스파이크 시간코딩을 이용해, 멤브레인 전위 시뮬레이션 없이 폐쇄형 입력‑출력 관계식을 도출하고 이를 기반으로 직접 학습 가능한 깊은 스파이킹 신경망(SpikingVGG16, Spiking‑GoogleNet)을 구축한다. CIFAR‑10과 ImageNet에서 DNN에 근접한 정확도를 달성했으며, 8·4·2비트 가중치 양자화와 무작위 잡음에 대한 강인성을 입증한다. 또한 위상‑도메인…
저자: Shibo Zhou, Xiaohua LI, Ying Chen
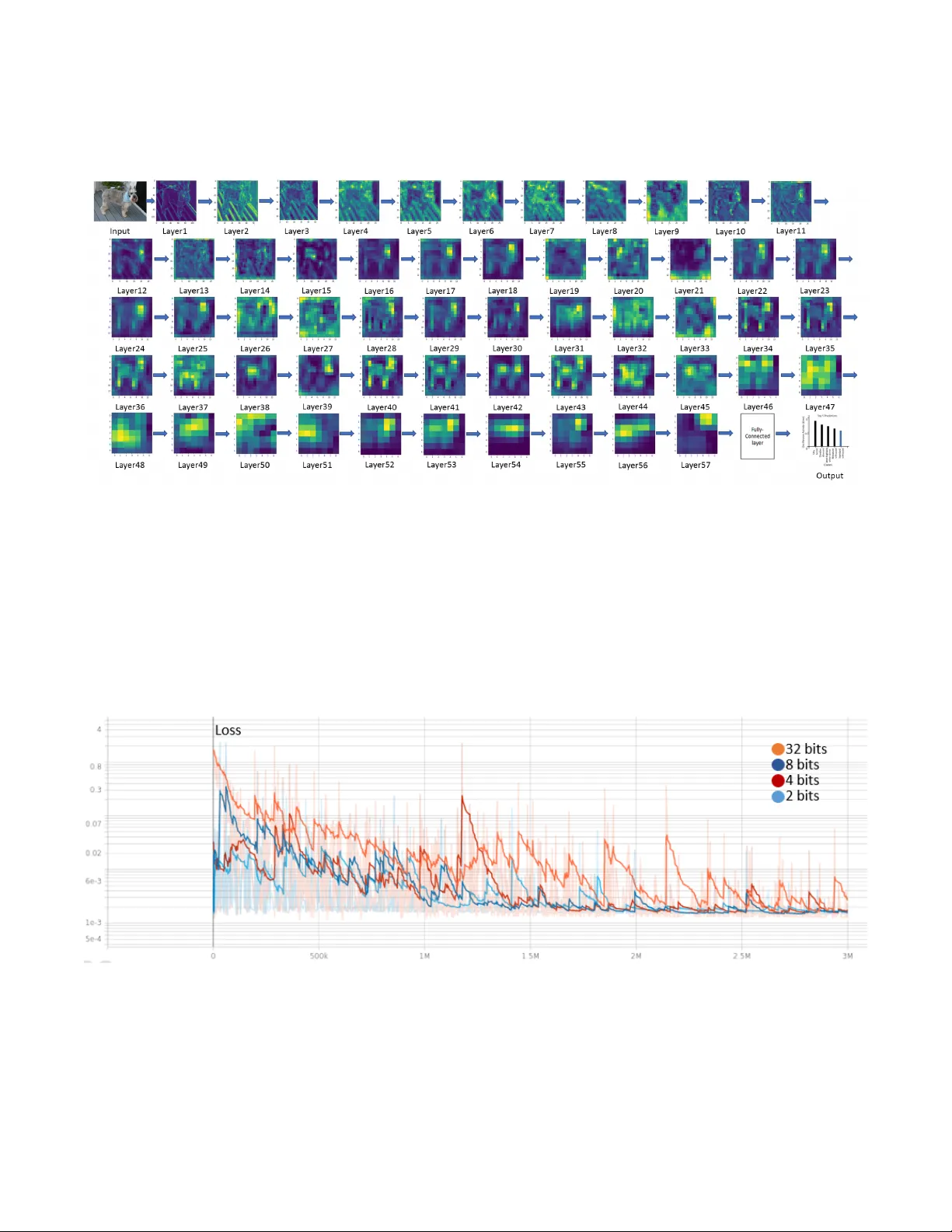
본 논문은 스파이킹 신경망(SNN)의 두 가지 근본적 한계—학습 난이도와 하드웨어 구현 시 견고성 부족—를 동시에 해결하는 통합 프레임워크를 제시한다. 먼저, 저자들은 적분‑발화(Integrate‑and‑Fire) 뉴런 모델을 일반적인 미분 방정식 형태로 기술하고, 입력 스파이크 시퀀스와 시냅스 가중치에 대한 폐쇄형 입력‑출력 관계식을 유도한다. 비누출 IF(Non‑leaky IF) 뉴런에 단일 스파이크 시간‑투‑첫‑스파이크(TTFS) 코딩을 적용하면, 출력 스파이크 시각 t_j가 식(4)와 같이 입력 시각 t_i와 가중치 w_ji의 지수함수 형태로 표현된다. 이 식은 DNN의 선형‑ReLU 연산과 구조적으로 동일하면서도, 스파이크 수를 1개로 제한해 에너지 효율을 극대화한다. 반면, 누설이 있는 LIF(LIF) 모델이나 레이트 코딩은 로그·람버트W·이차식 등 복잡한 비선형 함수를 포함해 무작위 가중치 초기화 시 정의역 오류가 빈번히 발생한다. 따라서 깊은 네트워크에서의 수렴이 불가능하거나, 변환 기반(SNN←DNN) 방법에서 요구되는 정규화·보정 절차가 필요해 학습 효율이 크게 저하된다. 저자들은 이러한 점을 체계적으로 실험·수식으로 검증하고, 비누출 IF·단일 스파이크 조합이 ‘직접‑학습(Direct‑Train)’에 가장 적합함을 증명한다.
학습 알고리즘은 폐쇄형 식(4)을 기반으로 추상화된 레이어 응답 모델을 소프트웨어에서 구현하고, 전통적인 역전파(back‑propagation)를 그대로 적용한다. 입력은 z⁰_i = e^{t⁰_i/τ} 형태로 변환되고, 각 레이어는 z^{l}_j = f(z^{l‑1}, w^{l}) 로 전파된다. 손실 함수는 (5)와 같이 목표 클래스에 대한 로그‑소프트맥스 손실, 가중치 합계 비용, L2 정규화를 결합한다. 이 구조 덕분에 멤브레인 전위 시뮬레이션 없이도 대규모 데이터셋에 대한 효율적인 학습이 가능해졌다.
하드웨어 구현 측면에서는 기존 전압‑도메인(VD) 적분 회로가 고이득 증폭기에 의존해 전력 소모가 크고 스케일링에 한계가 있다는 점을 지적한다. 이를 해결하기 위해 전압 제어 링 오실레이터(VCO)를 이용한 위상‑도메인(PD) 적분기를 설계한다. VCO는 입력 전압을 위상 변화로 변환하고, 위상 차이를 디지털 카운터와 XOR 게이트를 통해 스파이크 발생 조건으로 매핑한다. 이 구조는 디지털 CMOS 공정에서 저전압·소형화가 가능하며, 65 nm 공정 기준 1스파이크당 10 pJ 이하의 에너지 소모를 달성한다. 시뮬레이션 결과 기존 VD 기반 회로 대비 약 45 %의 에너지 절감 효과와, 가중치 양자화·시간 지터에 대한 내성을 확인하였다.
실험에서는 CIFAR‑10에서 기존 SNN 최고 기록을 넘어 94 % 이상의 정확도를 달성했으며, ImageNet에서는 동일 아키텍처 DNN 대비 1 % 이내의 정확도 격차를 기록했다. 또한 8·4·2비트 가중치 양자화와 가중치에 가우시안 잡음을 추가한 경우에도 성능 저하가 미미해, 저전력·저비용 neuromorphic 하드웨어 적용 가능성을 입증한다. 전체적으로 이 논문은 수학적 모델링, 알고리즘 설계, 회로 구현을 일관되게 연결함으로써, SNN이 실제 애플리케이션에서 DNN을 대체할 수 있는 실용적 경로를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기