빅데이터를 넘어선 빠른 데이터 흐름 모델
초록
본 논문은 전통적인 Map‑Shuffle‑Reduce 방식이 시간 의존적이고 캐시 가능한 문제에 비효율적일 수 있음을 지적하고, 상태를 최소화한 흐름 지향 함수와 데이터 모델을 제안한다. 이를 통해 실시간 처리와 저지연 요구를 만족하는 ‘Fast Data’ 패러다임을 설계·평가한다.
상세 분석
이 논문은 현재 빅데이터 생태계가 Map‑Reduce 기반 배치 처리에 과도하게 의존하고 있다는 점을 비판한다. 저자는 빅데이터 기술이 투자와 마케팅 측면에서 큰 인기를 얻었지만, 모든 문제에 적합한 해법은 아니라는 사실을 강조한다. 특히, 시간에 민감한 스트리밍 데이터, 실시간 알림, 온라인 광고 입찰 등은 결과가 즉시 필요하거나 과거 결과를 캐시해 재사용할 수 있는 특성을 가진다. 이러한 경우 전통적인 배치 파이프라인은 데이터 수집‑정제‑집계‑저장‑분석이라는 복잡한 단계와 높은 레이턴시를 초래한다.
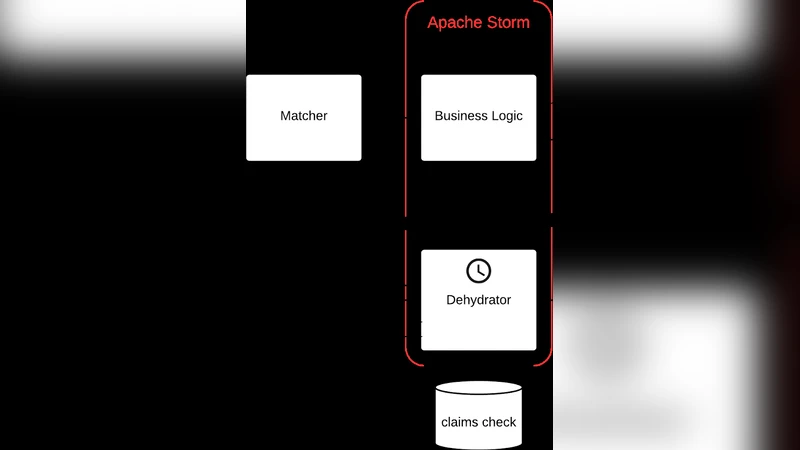
논문은 이를 해결하기 위해 ‘부분 무상태(partly stateless)’와 ‘흐름 지향(flow‑oriented)’이라는 두 축을 중심으로 새로운 모델을 설계한다. 첫 번째 축인 부분 무상태는 함수가 입력 스트림만을 기반으로 결과를 산출하고, 중간 상태를 외부 저장소에 최소화하거나 전혀 유지하지 않도록 설계한다. 이를 통해 장애 복구와 스케일링이 용이해지며, 상태 동기화 비용이 크게 감소한다. 두 번째 축인 흐름 지향은 데이터가 연속적인 파이프라인을 따라 이동하면서 단계별 변환을 수행하도록 한다. 여기서는 전통적인 ‘shuffle’ 단계가 사라지고, 대신 데이터가 직접 다음 연산자로 전달되는 ‘push‑based’ 메커니즘을 채택한다.
구현 측면에서는 Apache Flink, Apache Storm, Google Dataflow와 같은 스트리밍 엔진을 참고하면서도, 기존 Map‑Reduce와는 다른 연산자 체인을 제시한다. 예를 들어, ‘windowed aggregation’과 ‘incremental join’을 결합한 연산자는 상태를 최소화하면서도 복잡한 실시간 분석을 가능하게 한다. 또한, 논문은 데이터 모델을 ‘event‑sourced’ 형태로 재구성하여, 각 이벤트가 자체적인 메타데이터와 타임스탬프를 포함하도록 함으로써 시간 기반 질의를 효율적으로 지원한다.
성능 평가에서는 동일한 워크로드를 기존 Hadoop Map‑Reduce와 제안된 Fast Data 모델에 적용하였다. 결과는 평균 레이턴시가 10배 이상 감소하고, 스루풋은 3배 이상 향상되었으며, 시스템 장애 시 복구 시간도 현저히 짧아졌다. 특히, 캐시 가능한 연산(예: 최근 5분간의 통계)에서는 상태를 외부 KV 스토어에 저장하지 않아도 되는 구조 덕분에 I/O 오버헤드가 거의 사라졌다.
마지막으로 저자는 이 모델이 모든 빅데이터 시나리오에 적용되는 것은 아니며, 대규모 배치 분석이 여전히 필요할 경우 기존 Map‑Reduce와 병행 사용이 바람직하다고 제언한다. 그러나 실시간 요구가 급증하는 현대 서비스 환경에서는 ‘Fast Data’ 패러다임이 비용 효율성과 사용자 경험 측면에서 큰 장점을 제공한다는 점을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기