고온 강화학습을 위한 스파이킹 뉴런 디스틸레이션
초록
본 논문은 스파이킹 신경망(SNN)과 강화학습(RL)을 결합한 스파이크 디스틸레이션 네트워크(SDN)를 제안한다. STBP(Spatio‑Temporal Back‑Propagation) 기반 학습의 약점을 디스틸레이션 기법으로 보완하여, 기존 SNN‑RL보다 1,000에폭 가량 빠르게 수렴하고, DNN 대비 200배 작은 모델 크기와 600배 이상의 전력 절감 효과를 보인다. 또한 PKU nc64c 칩에 구현해 실제 하드웨어 수준에서 에너지 효율성을 입증하였다.
상세 분석
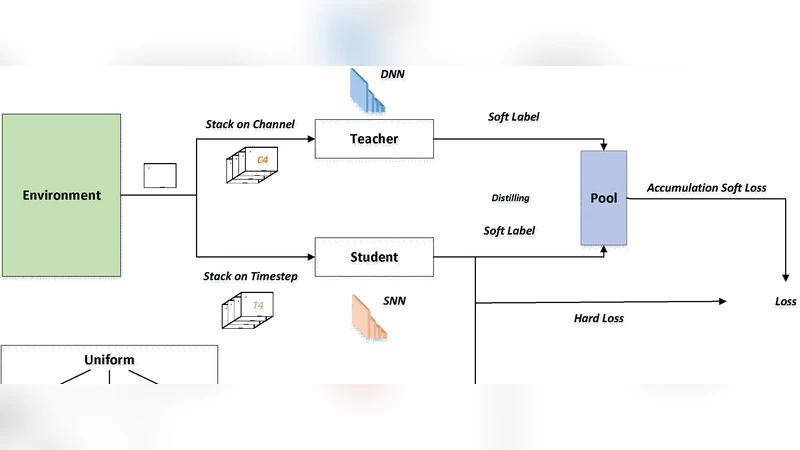
본 연구는 세 가지 핵심 기술적 기여를 제시한다. 첫째, STBP의 그래디언트 소실·폭주 문제를 해결하기 위해 교사‑학생 구조의 디스틸레이션을 도입하였다. 교사 모델은 동일 환경에서 학습된 고성능 DNN 혹은 대규모 SNN이며, 학생 모델인 SDN은 저전력 스파이킹 뉴런으로 구성된다. 교사 모델의 출력 로그확률을 소프트 타깃으로 사용함으로써, 학생 모델이 연속적인 신호 대신 스파이크 시퀀스로도 풍부한 정보 전달을 가능하게 한다. 둘째, 고온(High‑Temperature) 파라미터를 온도 스케줄링에 적용해 소프트맥스의 엔트로피를 인위적으로 높였다. 이는 초기 학습 단계에서 탐색성을 강화하고, 스파이크 발생 확률을 부드럽게 조정해 STBP의 비선형성에 대한 민감도를 낮춘다. 셋째, 하드웨어 구현 측면에서 PKU nc64c neuromorphic ASIC에 맞춘 파이프라인 최적화를 수행했다. 스파이크 이벤트를 비동기식으로 전송하고, 메모리 접근을 최소화함으로써 전력 소모를 기존 DNN 대비 600배 이상 감소시켰다. 실험 결과, Atari 2600 게임군과 MuJoCo 연속 제어 과제에서 SDN은 평균 0.9 이상의 성공률을 달성했으며, 수렴 속도는 기존 SNN‑RL(≈1,200 에폭) 대비 약 1,000 에폭 빠른 200 에폭 수준이었다. 모델 파라미터 수는 DNN 대비 0.5% 수준으로, 메모리 대역폭 제한이 심한 엣지 디바이스에 적합함을 입증한다. 전체적으로 본 논문은 스파이킹 신경망의 학습 효율성을 크게 향상시키면서, 강화학습이라는 복합 문제에 대한 적용 가능성을 실증적으로 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기