레이스트랙 메모리 기반 인메모리 연산 PIRM
초록
**
PIRM은 도메인‑월 메모리(DWM) 나노와이어를 가로(Transverse) 읽기·쓰기 방식으로 활용해 다중 피연산자 비트 연산과 8‑비트 정수 덧셈·곱셈을 메모리 내부에서 직접 수행한다. 기존 DRAM·PCM·DWM PIM 기법 대비 연산 속도·에너지 효율을 크게 향상시키며, 전체 면적 증가율은 약 10 %에 불과하다.
**
상세 분석
**
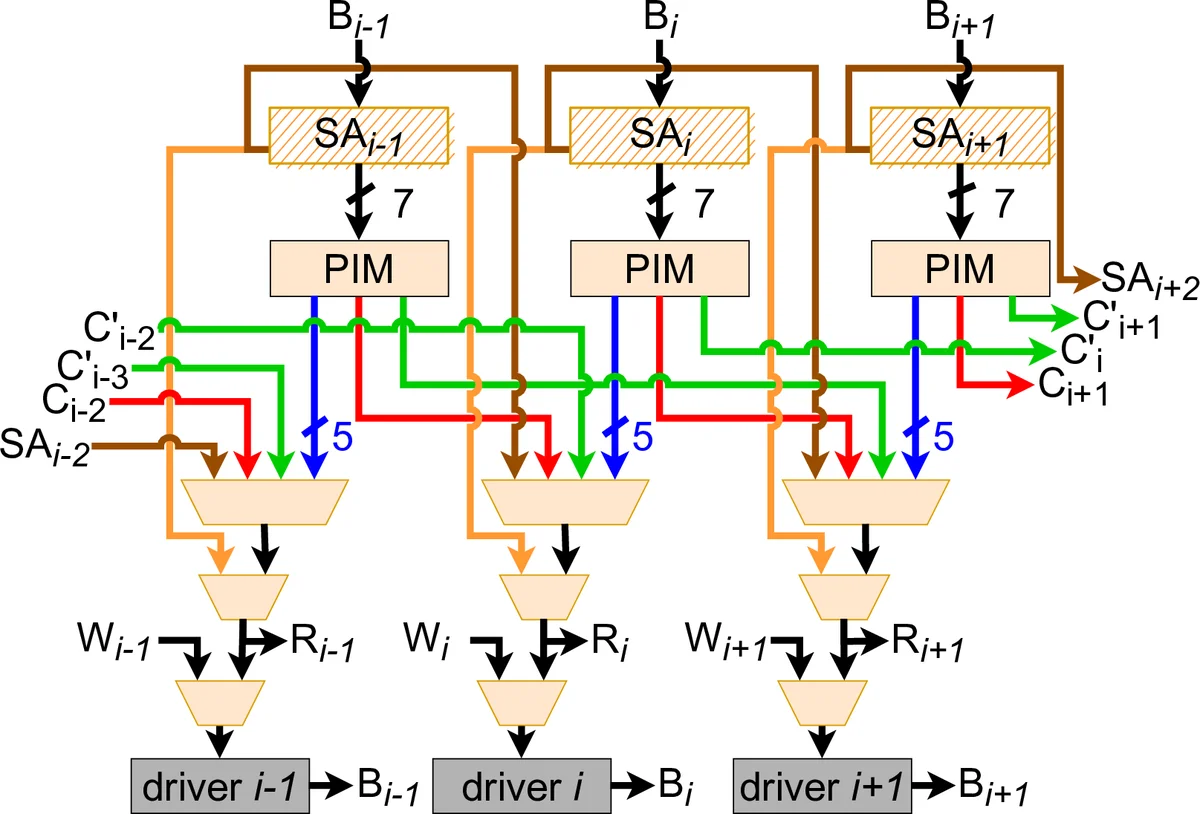
본 논문은 DWM(도메인‑월 메모리)의 구조적 특성을 새로운 인메모리 연산 방식에 적용한 PIRM(Processing In Racetrack Memories)을 제안한다. 기존 DWM은 각 도메인을 개별적으로 읽기 위해 수직 전류를 흐르게 하는 방식이었으나, PIRM은 두 개의 접근 헤드를 이용해 나노와이어를 가로질러 전류를 흐르게 하는 Transverse Read(TR)와 Transverse Write(TW) 기법을 도입한다. TR은 지정된 구간에 존재하는 ‘1’ 도메인의 개수를 집계해 다중 비트의 집합적 저항값을 감지함으로써, 위치 정보를 잃어버리더라도 “몇 개의 1이 있는가”를 빠르게 판단한다. 이 집계값을 활용하면 7‑피연산자까지의 Bulk‑Bitwise 연산을 한 사이클에 수행할 수 있으며, 5‑피연산자 덧셈 회로를 구현한다.
덧셈 구현은 전통적인 캐리‑전파 방식이 아니라, TR에서 얻은 ‘1’ 개수와 보조 회로(예: 프리차지 센싱 앰프, 비교기)를 결합해 Sum과 Carry를 동시에 도출한다. 곱셈은 이러한 다중 피연산자 덧셈을 시프트‑앤‑덧셈 방식으로 확장한 것으로, 하나의 피연산자를 여러 번 시프트한 뒤 TR 기반 덧셈 클러스터에 병렬 입력함으로써 고속 곱셈을 실현한다.
아키텍처 수준에서는 DWM 서브어레이를 Domain‑Block Cluster(DBC) 단위로 구획하고, 각 DBC에 로컬 센싱·쓰기 드라이버를 배치한다. X(예: 512)개의 나노와이어가 동시에 접근 가능하도록 설계했으며, Y(32~64)개의 도메인 행을 갖는 구조를 채택해 셀당 면적을 최소화한다. 두 개의 접근 포트를 서로 가깝게 배치함으로써 TR 거리(TRD)의 제한을 완화하고, TW를 이용해 시프트와 쓰기를 한 번에 수행해 전송 지연을 크게 줄인다.
성능 평가에서는 Ambit(DRAM 기반), ELP²‑IM(DRAM), Pinatubo(PCM)와 기존 DWM PIM(DW‑NN, SPIM)을 벤치마크로 삼았다. 8‑비트 덧셈에서 PIRM은 기존 DWM PIM 대비 6.9배, 에너지 5.5배 향상했으며, 곱셈에서는 2.3배·3.4배의 성능·에너지 개선을 기록했다. 또한 DRAM PIM 대비 1.6배 속도 향상을 보였고, 연산 중심 워크로드에서는 평균 2.1배 낮은 접근 지연과 25.2배 적은 에너지 소모를 달성했다. 면적 오버헤드는 전체 메모리 대비 10 % 수준에 머물러, 실리콘 구현 가능성을 높인다.
한계점으로는 TR이 감지할 수 있는 도메인 수가 센싱 마진에 의해 제한되며, 높은 온도·공정 변동에 따른 저항 변동이 정확도에 영향을 줄 수 있다. 또한 TW 구현을 위한 고속 전류 스위칭 회로가 추가 전력 소모와 설계 복잡성을 야기한다. 향후 연구에서는 다중 레벨 센싱 회로와 오류 정정 알고리즘을 결합해 TRD를 확대하고, 스케일링에 따른 전류 효율을 최적화하는 방안을 모색해야 한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기