지능형 로봇 속임수를 위한 동적 게임 이론
본 논문은 N명의 로봇이 K단계에 걸쳐 비대칭 정보를 가지고 상호작용하는 동적 게임을 모델링하고, 완전 베이즈 내시 균형(PBNE)을 해석적·계산적으로 구한다. 선형‑이차(LQ) 설정에서는 인지 결합이 포함된 확장 리카티 방정식을 도출하고, 내재적 신념 업데이트가 있는 경우에는 실시간 재계획을 위한 제한된 호라이즌 알고리즘을 제안한다. 추격‑회피 시나리오를 사례연구로 삼아 속임수의 효과를 정량화하는 ‘속임수 가능성’, ‘도달 가능성’, ‘속임수…
저자: Linan Huang, Quanyan Zhu
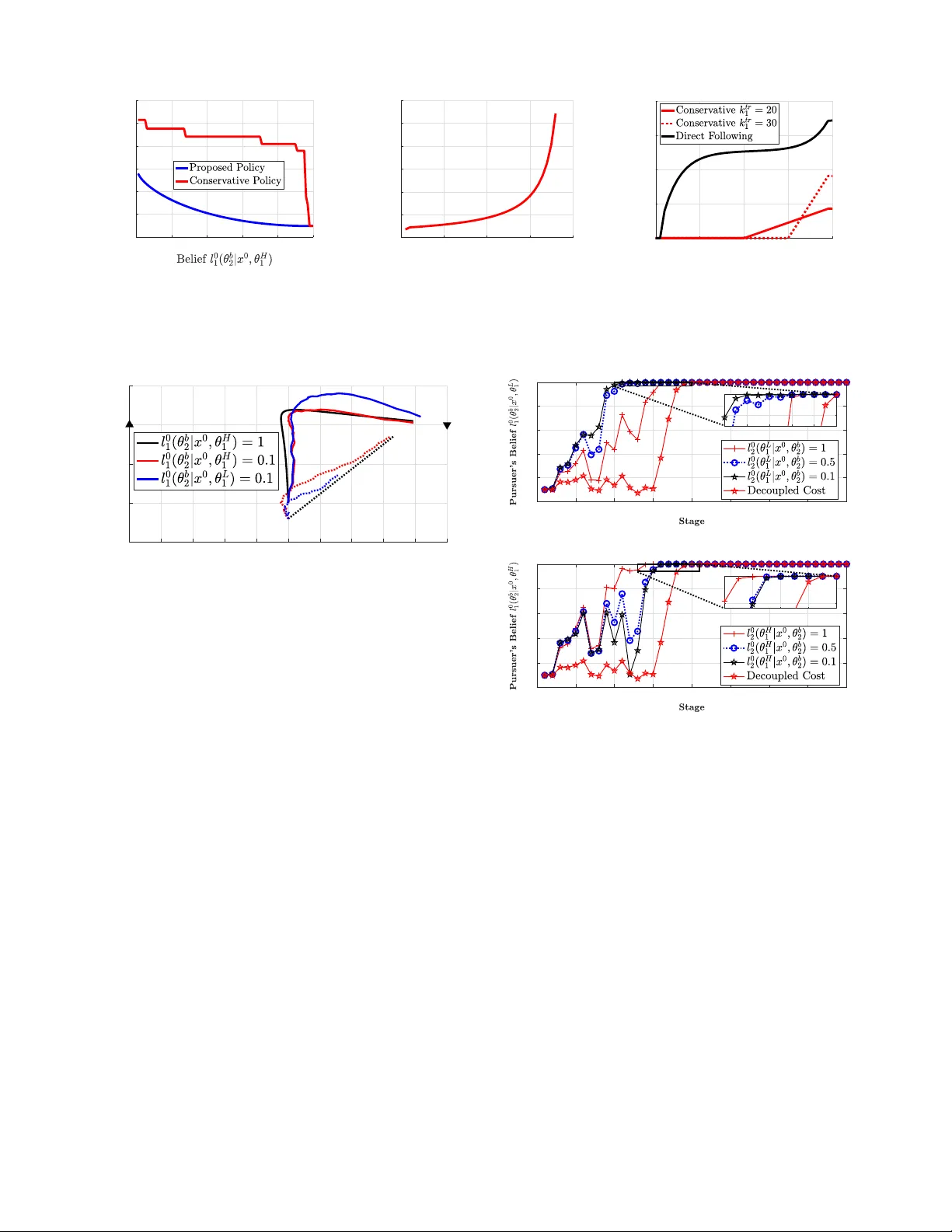
본 논문은 지능형 로봇 간의 지속적이고 합리적인 속임수(interaction)를 정량적으로 분석하기 위해 동적 게임 이론을 기반으로 한 새로운 프레임워크를 제시한다. 연구는 크게 네 가지 주요 기여로 구성된다.
첫 번째 기여는 N명의 로봇이 K단계에 걸쳐 비대칭 정보를 가지고 상호작용하는 ‘동적 게임 with private types’를 정의하고, 이를 완전 베이즈 내시 균형(PBNE)이라는 해석적 해결책으로 연결한 것이다. 각 로봇은 자신의 타입(예: 목표 지점, 기동성 등)을 비밀로 유지하면서, 다른 로봇의 타입에 대한 사전 확률과 실시간 관측을 통해 베이즈식 신념을 지속적으로 업데이트한다. 이러한 신념은 게임 진행 중에 변하며, 로봇의 행동은 물리적 상태와 신념 모두에 의존하는 ‘인지 결합(cognitive coupling)’을 만든다.
두 번째 기여는 PBNE 계산을 ‘비선형 확률 제어 문제’로 재구성하고, 선형‑이차(LQ) 형태의 시스템 동역학과 비용 함수를 가정했을 때 확장된 리카티 방정식(extended Riccati equations)을 도출한 것이다. 기존 리카티 방정식에 타입에 대한 베이즈 업데이트와 신념 전이 함수를 포함시켜, 각 로봇의 최적 제어가 상태와 신념에 대한 선형 피드백 형태로 표현될 수 있음을 보였다. 이 방정식은 ‘인지 결합 항’을 포함함으로써, 전통적인 LQ 게임이 갖는 해석적 단순성을 유지하면서도 비대칭 정보와 학습 효과를 동시에 포착한다.
세 번째 기여는 내재적 신념 전이(intrinsic belief dynamics) 상황에서의 계산 복잡도를 낮추기 위해 제한된 호라이즌(recurring‑horizon) 알고리즘을 설계한 것이다. 매 단계마다 최신 관측과 업데이트된 신념을 이용해 짧은 미래(K′)에 대한 최적 제어를 재계산함으로써, 실시간 적용이 가능한 근사 PBNE를 제공한다. 이 알고리즘은 시간·공간 복잡도가 선형에 가깝게 유지되어, 실제 로봇 시스템에 적용하기에 충분히 효율적이다.
네 번째 기여는 ‘속임수 추격‑회피(pursuit‑evasion)’ 게임을 사례연구로 채택하고, 새로운 성능 지표들을 제안한 것이다. 제안된 지표는 (1) Deceivability(속임수 가능성) – 로봇이 자신의 타입을 숨기고 상대를 오도할 수 있는 정도, (2) Reachability(도달 가능성) – 목표 지점에 도달할 확률, (3) Price of Deception(PoD) – 완전 정보 상황 대비 비대칭 정보 상황에서 발생하는 비용 비율이다. 실험 결과, PoD가 1을 초과할 경우 속임수가 양쪽 모두에게 이득이 될 수 있음을 확인하였다. 또한, 타입 구분도가 높을수록 Deceivability가 감소하고, 추격자의 기동성이 향상될수록 방어 성능이 개선되지만 일정 수준을 넘으면 추가적인 기동성 증가는 비용 효율이 낮아진다. ‘속임수에 대한 속임수(counter‑deception)’ 전략은 상황에 따라 역효과를 낼 수 있음을 보여, 단순히 기동성을 모방하는 것이 항상 최선이 아님을 강조한다.
논문 전반에 걸쳐 베이즈 학습, 동적 프로그래밍, 최적 제어를 통합한 포괄적 프레임워크를 제공함으로써, 로봇 군집, 인간‑로봇 협업, 군사 작전 등 다양한 응용 분야에서 전략적 의사결정을 지원한다. 특히, 비대칭 정보와 지속적인 학습이 결합된 환경에서 로봇이 어떻게 합리적으로 행동하고, 상대의 속임수를 어떻게 탐지·대응할 수 있는지를 이론적으로 정립하고, 실시간 알고리즘까지 제시한 점이 큰 의의이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기