효율적인 무감독 어휘 확장으로 RNN 언어 모델 성능 향상
본 논문은 사전 학습된 RNNLM의 중간층을 그대로 유지하면서 입력·출력 임베딩 행렬만 확장해 OOS(Out‑of‑Shortlist) 단어를 효과적으로 모델링하는 방법을 제안한다. 유사 단어의 임베딩을 빌려 새로운 단어 벡터를 생성하고, ASR 출력에서 자동으로 OOS 단어 목록을 추출하는 무감독 절차를 도입한다. TED‑LIUM 실험에서 기존 RNNLM 대비 4 % 상대 WER 개선, 5‑gram KN 모델 대비 7 % 개선을 달성했으며, 추…
저자: Yerbolat Khassanov, Eng Siong Chng
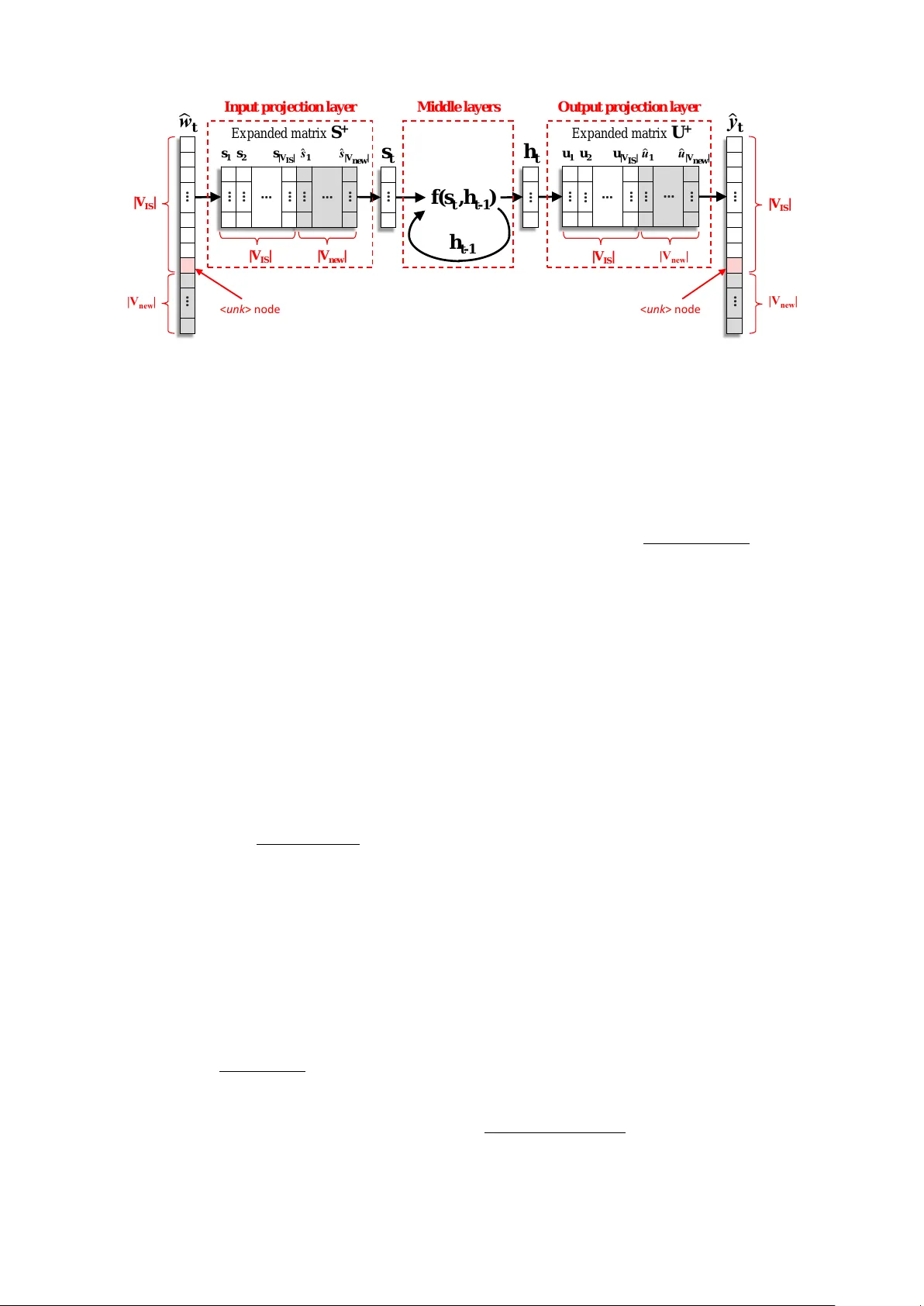
본 논문은 자동 음성 인식(ASR) 시스템에서 재스코어링 단계에 사용되는 RNN 기반 언어 모델(RNNLM)의 어휘 제한 문제를 해결하고자 한다. RNNLM은 학습 비용이 높아 전체 어휘를 모두 포함하기 어렵고, 일반적으로 가장 빈번한 수만 개 단어만을 ‘in‑shortlist(IS)’로 두고 나머지 단어는 하나에 집약한다. 이 구조는 테스트 음성에 OOS(Out‑of‑Shortlist) 단어가 많이 포함될 경우, 에 할당된 확률 질량이 분산돼 해당 단어들의 확률 추정이 부정확해지고, 결과적으로 WER이 상승한다. 기존 해결책은 IS 집합을 확대하고 전체 네트워크를 재학습하는 것이었지만, 이는 수일‑수주에 이르는 학습 시간과 대규모 텍스트 코퍼스 확보의 어려움을 동반한다.
저자들은 RNNLM을 ‘입력 투사층 → 중간 비선형층 → 출력 투사층’이라는 세 부분으로 명확히 분리하고, 중간층은 문맥 정보를 압축하는 역할만 수행하므로 파라미터를 고정해도 기존 모델의 기능을 유지할 수 있다고 가정한다. 따라서 어휘 확장은 입력 임베딩 행렬 S와 출력 임베딩 행렬 U만을 확장하는 방식으로 수행한다.
구체적인 절차는 다음과 같다.
1. **OOS 단어 추출(무감독)**: 디코딩 단계에서 사용되는 배경 LM(대규모 어휘를 가진 n‑gram 모델)으로부터 생성된 라티스 혹은 N‑best 리스트를 분석한다. 여기에는 테스트 데이터에 실제로 등장할 가능성이 높은 OOS 단어가 포함되어 있다. 이를 빈도 기준으로 상위 일부를 선택해 V_new이라는 확장 후보 집합을 만든다.
2. **유사 후보 단어 선정**: 각 OOS 단어에 대해 의미·구문적으로 가장 유사한 IS 단어들을 찾는다. 저자는 기존 워드 임베딩 공간에서 코사인 유사도, 혹은 외부 동의어 사전·WordNet 등을 활용해 2~3개의 후보 C를 선정한다. 후보는 반드시 IS 집합에 존재해야 한다.
3. **임베딩 벡터 생성 및 행렬 확장**: 입력 임베딩 S의 경우, 후보들의 벡터 s_i를 정규화된 가중치 m_i로 가중 평균해 새로운 입력 벡터 ˆs_new을 만든다(ˆs_new = Σ_i m_i s_i). 출력 임베딩 U도 동일한 방식으로 ˆu_new을 만든다. 이렇게 만든 ˆs_new과 ˆu_new을 각각 기존 행렬 S와 U에 열 단위로 추가해 확장된 행렬 S⁺와 U⁺를 구성한다. 입력 원-핫 벡터와 출력 스코어 계산도 동일하게 확장된 차원으로 수행된다.
이 방법은 중간층 파라미터를 그대로 유지하므로, 기존 모델이 학습한 고차원 문맥‑단어 매핑을 그대로 활용한다. 새로운 단어가 기존 IS 단어와 충분히 유사하면, 해당 단어에 대한 확률 추정이 자연스럽게 이루어진다.
실험은 다음과 같이 설계되었다. TED‑LIUM 코퍼스를 사용해 10 k개의 IS 단어만을 학습한 4‑layer LSTM RNNLM을 baseline으로 설정하고, 동일한 데이터와 150 k 어휘를 가진 Kneser‑Ney 5‑gram 모델(KN5)도 비교 대상으로 두었다. OOS 단어는 ASR 시스템(칼디 기반)에서 생성된 300‑best 리스트에서 빈도 상위 140 k 단어를 추출했으며, 각 OOS에 대해 2개의 가장 유사한 IS 후보를 선택해 임베딩을 평균하였다. 평가 지표는 perplexity와 WER이며, 개발 셋을 통해 후보 수, 가중치, LM 스케일 등의 하이퍼파라미터를 튜닝했다.
결과는 다음과 같다. VE‑LSTM(확장된 RNNLM)은 baseline LSTM 대비 약 4 % 상대 WER 감소를 보였고, KN5 대비 7 % 감소했다. perplexity 역시 유의미하게 낮아졌으며, 학습 시간은 기존 모델과 동일하게 짧았다(임베딩 행렬 확장만 수행). 메모리 사용량은 추가된 단어 수에 비례해 증가했지만, 현대 GPU 메모리 한계 내에서 충분히 관리 가능했다.
논문의 주요 기여는 (1) 중간층을 고정한 채 어휘만 효율적으로 확장하는 새로운 프레임워크 제시, (2) 실제 ASR 출력에서 OOS 단어를 자동으로 추출하는 무감독 방법 도입, (3) 실험을 통해 추가 학습 데이터 없이도 의미 있는 WER 개선을 입증한 점이다. 한계로는 유사 후보 선정이 부정확할 경우 임베딩 추정이 왜곡될 수 있고, 라티스 품질에 따라 잡음이 많은 OOS 단어가 포함될 위험이 있다. 향후 연구에서는 대규모 사전 학습 언어 모델을 활용한 후보 선정 강화, 동적 어휘 확장(실시간 ASR 파이프라인에 적용) 및 서브워드 기반 혼합 모델과의 결합 등을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기