금융 분야 인공지능 도전과 기술 그리고 기회
초록
본 리뷰는 금융 비즈니스와 데이터의 전반적 환경을 조망한 뒤, 수십 년에 걸친 인공지능 연구를 체계적으로 분류·정리한다. 고전 AI와 현대 AI 기법을 비교·비판하고, 데이터‑구동 분석·학습 흐름을 시각화한다. 마지막으로 향후 AI‑기반 금융과 금융‑동기 AI 연구의 미해결 과제와 성장 가능성을 제시한다.
상세 분석
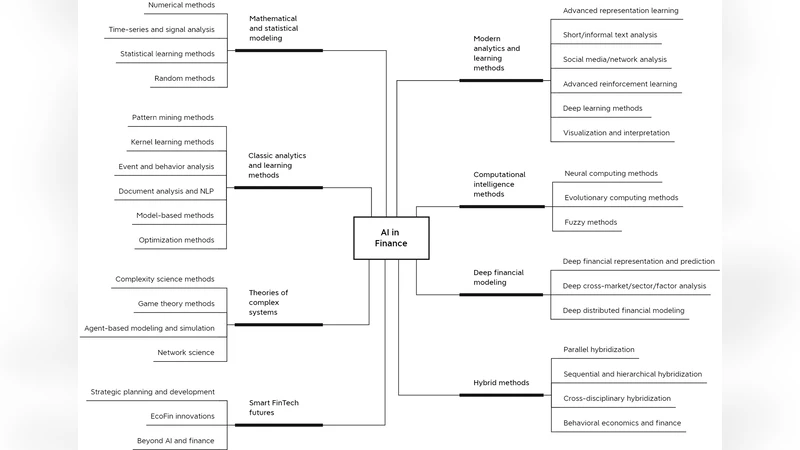
이 논문은 금융 분야에 적용된 인공지능 기술을 ‘도전·기술·기회’라는 삼각구조로 재구성한다. 먼저 금융 비즈니스와 데이터의 특성을 상세히 기술한다. 금융 데이터는 고빈도 거래 기록, 신용 스코어, 시장 뉴스, 소셜 미디어 감성 등 다양한 형태와 스케일을 갖으며, 비정형·정형 데이터가 혼재하고, 실시간성, 규제 준수, 프라이버시 보호 등 제약이 복합적이다. 이러한 환경은 전통적인 통계 모델만으로는 한계가 있어, 패턴 인식·예측·최적화에 AI가 도입되었다.
논문은 과거부터 현재까지 AI 연구 흐름을 연대별·주제별로 매핑한다. 1990년대 초반에는 전문가 시스템, 규칙 기반 모델, 전통적인 머신러닝(선형 회귀, SVM, 의사결정트리) 등이 주류였으며, 포트폴리오 최적화, 위험 측정, 신용 평가 등에 활용되었다. 2000년대 중반부터는 빅데이터와 클라우드 컴퓨팅이 확산되면서, 앙상블 학습, 강화학습, 그래프 기반 모델이 등장하고, 고빈도 거래와 알고리즘 트레이딩에 적용되었다. 최근 10년간은 딥러닝, 트랜스포머, 생성형 AI(예: GPT 계열), 그리고 멀티모달 학습이 급부상하면서, 시장 예측, 텍스트 기반 감성 분석, 자동화된 보고서 작성, 사기 탐지 등에 혁신을 일으키고 있다.
핵심 기술 비교에서는 고전 AI와 현대 AI의 장단점을 명확히 구분한다. 고전 AI는 해석 가능성, 학습 데이터 요구량이 적고, 규제 환경에 유리하지만 복잡한 비선형 관계를 포착하는 데 한계가 있다. 반면 현대 AI, 특히 딥러닝은 대규모 비정형 데이터에서 뛰어난 표현력을 보이나, ‘블랙박스’ 특성으로 인해 설명 가능성·규제 적합성 문제가 대두된다. 논문은 이러한 트레이드오프를 해결하기 위한 설명가능 AI(XAI), 모델 압축, 연합 학습 등 최신 연구 동향도 소개한다.
마지막으로 논문은 미해결 과제로 데이터 프라이버시·보안, 규제 대응, 모델 지속 가능성(에너지 소비), 도메인 적응(다양한 시장·상품에 대한 일반화) 등을 제시한다. 또한 AI가 금융 시장 구조 자체를 재편하고, 새로운 금융 상품·서비스(예: AI‑기반 파생상품, 맞춤형 투자 어드바이저) 창출을 촉진할 가능성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기