Q SpiNN 스파이킹 신경망 양자화 프레임워크
초록
Q‑SpiNN은 스파이킹 신경망(SNN)의 가중치뿐 아니라 막전위·임계값 등 다양한 파라미터를 대상으로 정밀도와 라운딩 방식을 다변화하여 메모리 사용량을 크게 줄이면서도 정확도 손실을 최소화하는 양자화 프레임워크이다. PTQ와 ITQ 두 가지 양자화 스킴을 모두 탐색하고, 후보 모델들의 메모리‑정확도 트레이드오프를 다목적 보상 함수로 평가해 파레토 최적 모델을 자동 선택한다. 실험 결과, 비지도 학습 SNN은 MNIST에서 메모리를 4배 절감하고 정확도 손실을 1% 이하로, 지도 학습 SNN은 DVS‑Gesture에서 메모리를 2배 절감하면서 정확도 손실을 2% 이하로 유지한다.
상세 분석
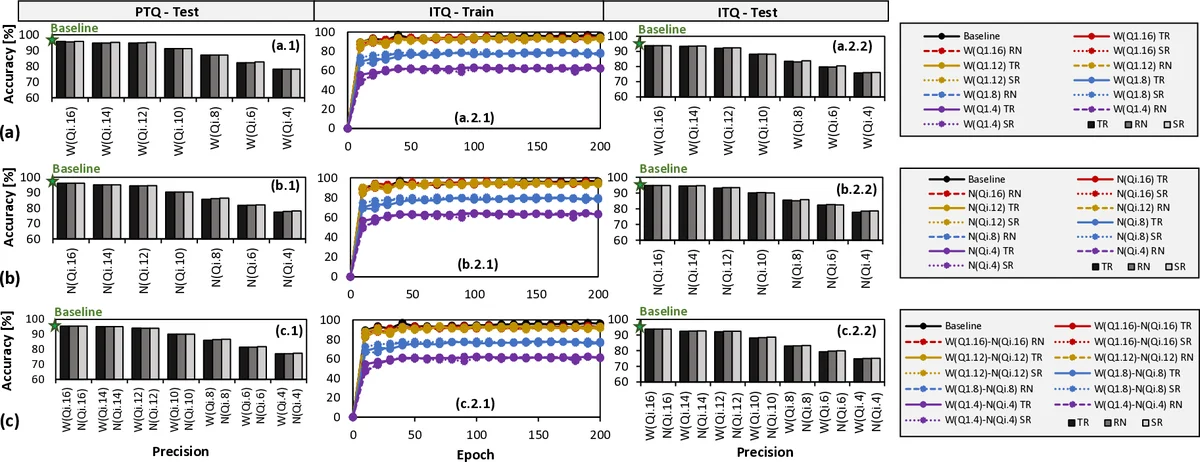
본 논문은 스파이킹 신경망(SNN)의 메모리 효율성을 향상시키기 위한 양자화 전략을 체계적으로 재정의한다. 기존 연구가 가중치만을 대상으로 PTQ 혹은 ITQ 중 하나의 스킴을 적용해 메모리를 절감했지만, 막전위(V)와 임계전위(Vth) 같은 뉴런 내부 상태 변수도 상당한 메모리를 차지한다는 점을 간과했다. Q‑SpiNN은 이러한 파라미터들을 각각의 중요도에 따라 다른 정밀도(Qi.f)와 라운딩 방식(TR, RN, SR)을 할당함으로써 전체 메모리 사용량을 최소화한다.
핵심 메커니즘은 세 단계로 구성된다. 첫째, 각 파라미터별 정확도 민감도를 실험적으로 측정해 “정밀도‑중요도 매핑”을 만든다. 예를 들어, 가중치는 1.4비트 정밀도(Q1.4)에서도 큰 정확도 저하가 없지만, 막전위는 11비트 정밀도(Q11.16)가 필요함을 확인한다. 둘째, PTQ와 ITQ, 다양한 비트폭, 라운딩 방식을 조합해 후보 모델 집합을 생성한다. 여기서 후보는 사용자가 지정한 목표 정확도(예: MNIST에서 99% 이상) 를 만족하는 경우에만 포함된다. 셋째, 다목적 보상 함수를 정의해 메모리 절감량과 정확도 유지율을 동시에 평가한다. 보상 함수는 메모리 절감 비율에 정확도 손실 페널티를 곱해 파레토 최적 모델을 자동으로 선택한다.
실험에서는 두 종류의 SNN을 사용한다. 비지도 학습을 위한 단일층 STDP 기반 U‑SNN과, 지도 학습을 위한 다층 DECOLLE 기반 S‑SNN이다. 두 모델 모두 고정점 형식(Qi.f)으로 변환된 파라미터를 GPU와 임베디드 GPU에서 실행했으며, 메모리 사용량과 정확도 변화를 정량화했다. 결과는 기대와 일치한다. U‑SNN은 가중치를 Q1.16, 뉴런 파라미터를 Q11.16으로 양자화했을 때 메모리 4배 절감과 정확도 1% 이하 손실을 달성했으며, S‑SNN은 가중치를 Q1.8, 뉴런 파라미터를 Q11.8로 양자화해 메모리 2배 절감과 정확도 2% 이하 손실을 얻었다. 또한, 라운딩 방식 중 stochastic rounding이 정밀도 손실을 가장 잘 보완한다는 점을 확인했다.
이러한 접근은 SNN을 에지 디바이스에 배치할 때 발생하는 메모리·전력 제약을 크게 완화한다. 메모리 접근이 전체 에너지 소비의 50~75%를 차지한다는 기존 연구와 결합하면, Q‑SpiNN이 제공하는 메모리 절감은 실제 전력 절감으로 직결될 가능성이 높다. 또한, 프레임워크가 양자화 스킴, 비트폭, 라운딩을 자동 탐색하고 파레토 최적 모델을 선택하도록 설계돼, 연구자가 일일이 실험을 반복할 필요 없이 손쉽게 최적의 SNN을 도출할 수 있다.
향후 연구에서는 양자화된 SNN을 실제 IoT‑Edge 하드웨어(예: 저전력 MCU, neuromorphic 칩)에서 실행해 에너지·지연 측정을 수행하고, 양자화와 함께 프루닝·스파스 연결을 결합해 더욱 극한의 메모리·전력 효율을 탐구할 여지가 있다. 또한, 비정형 데이터(예: 이벤트 기반 카메라)와 복합 손실 함수에 대한 양자화 민감도 분석을 확대하면, 다양한 응용 분야에 대한 일반화 가능성을 높일 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기