비선형 은닉층이 다중 연합 탐색을 가능하게 하는 배우‑비평 에이전트
초록
본 연구는 전통적인 배우‑비평(Actor‑Critic) 모델이 단일 보상 위치는 학습하지만, 여러 쌍의 단서‑보상 연합을 동시에 학습하지 못한다는 한계를 규명한다. 이를 해결하기 위해 장소 세포와 시각 단서를 비선형 피드포워드 은닉층에 통합하고, TD 오차에 의해 가중치가 조정되는 플라스틱 메커니즘을 도입한 새로운 에이전트를 제안한다. 실험 결과, 이 모델은 다중 연합 탐색 과제를 성공적으로 학습하며, 은닉층을 순환형 리저버 네트워크로 교체할 경우 학습 속도가 더욱 가속화된다.
상세 분석
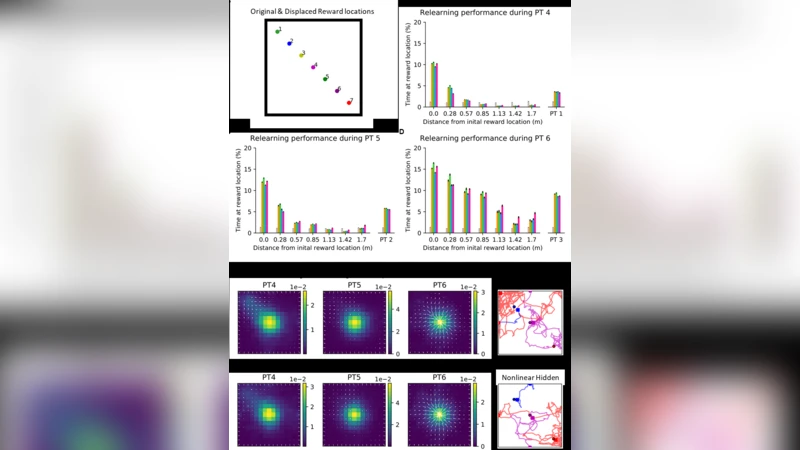
이 논문은 rodent의 다중 큐‑보상 위치 탐색 과제가 인공 에이전트에게 어떻게 구현될 수 있는지를 고찰한다. 기존의 딥 강화학습(Deep RL) 접근법은 뛰어난 성능을 보이지만, 신경생물학적 메커니즘과는 거리가 멀다. 반면, 고전적인 배우‑비평 구조는 TD(Temporal Difference) 오류에 기반한 시냅스 가중치 업데이트를 통해 생물학적 타당성을 확보하지만, 다중 연합 학습에서는 구조적 한계에 부딪힌다. 저자들은 먼저 표준 배우‑비평 에이전트를 구현해 단일 보상 지점 학습과 보상 위치 이동 적응을 확인한다. 그러나 동일한 구조로는 두 개 이상의 단서‑보상 쌍을 동시에 학습하지 못한다는 사실을 실험적으로 입증한다.
핵심적인 해결책은 장소 세포(place cell)와 시각 단서(cue) 정보를 비선형 활성화 함수를 갖는 피드포워드 은닉층에 먼저 매핑하는 것이다. 이 은닉층은 입력 차원을 압축하면서도 비선형 변환을 제공해, 서로 다른 단서‑보상 조합을 구분 가능한 내부 표현으로 변환한다. 이후 배우와 비평 네트워크는 은닉층 출력에 직접 연결되며, 가중치는 TD 오류에 의해 변조되는 Hebbian‑like 플라스틱 규칙을 따른다. 이러한 구조는 ‘숨은 연합 메모리’를 형성해, 동일한 장소 세포 집합이 여러 단서와 연결될 수 있게 만든다.
추가 실험에서는 은닉층을 고정된 랜덤 연결을 갖는 순환형 리저버 네트워크(Reservoir Computing)로 교체한다. 리저버는 풍부한 동적 상태 공간을 제공해 입력 시퀀스의 시간적 패턴을 자동으로 인코딩한다. 결과적으로 학습 초기 단계에서의 수렴 속도가 크게 향상되며, 특히 보상 위치가 급격히 변할 때도 안정적인 성능을 유지한다.
이 논문은 두 가지 중요한 시사점을 제공한다. 첫째, 비선형 은닉 변환이 없을 경우 고전적인 배우‑비평 구조는 입력 차원의 선형 결합만을 학습하게 되어, 다중 연합을 구분할 수 없는 ‘표현 병목’에 빠진다. 둘째, 순환형 리저버는 생물학적 시냅스 가소성 메커니즘과 결합될 때, 뇌의 해마‑전전두 피질 회로가 수행하는 복합적인 공간‑시간 연합 학습을 모사할 수 있음을 보여준다. 이러한 결과는 신경과학적 모델링과 생물학적 타당성을 갖춘 강화학습 알고리즘 설계에 새로운 방향을 제시한다.