합성 데이터 기반 감독형 심볼릭 음악 스타일 변환
본 논문은 심볼릭 음악의 반주 스타일을 내용은 유지하면서 변환하기 위해, 대규모 정렬(Aligned) 데이터가 부족한 문제를 합성 MIDI 데이터를 이용해 해결한다. 합성 파이프라인으로 만든 70여 개의 스타일을 포함한 658K 학습 쌍을 활용해, 스타일을 조건으로 하는 단일 디코더를 갖는 RNN 기반 인코더‑디코더 모델을 제안한다. 실험 결과, 전적으로 합성 데이터만으로 학습했음에도 불구하고 실제 MIDI에 대해 의미 있는 반주를 생성한다는 …
저자: Ondv{r}ej Cifka, Umut c{S}imc{s}ekli, Ga"el Richard
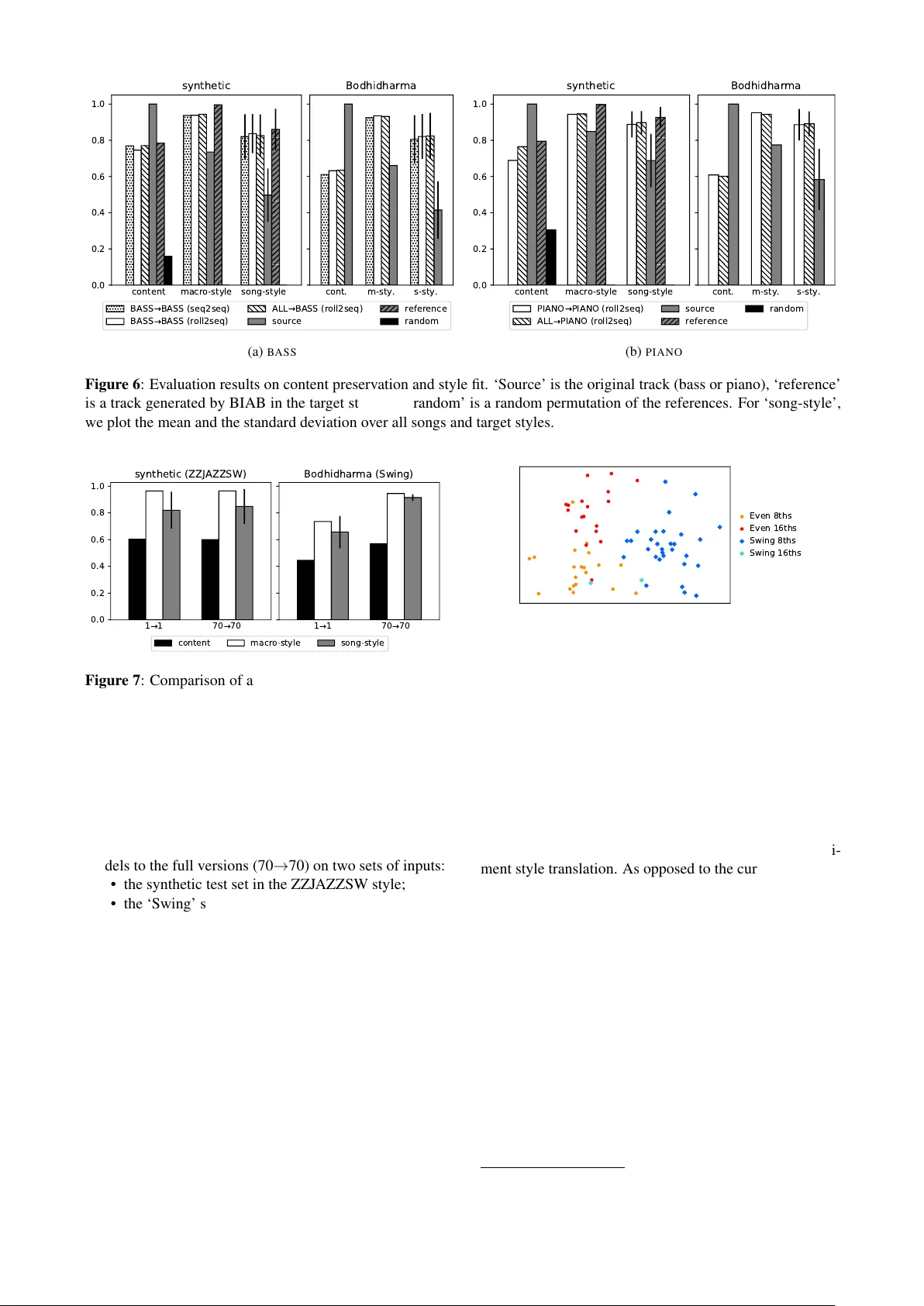
본 논문은 심볼릭 음악, 특히 반주 트랙(베이스와 피아노)의 스타일을 변환하면서 원곡의 화성 구조를 보존하는 문제에 초점을 맞춘다. 기존 연구는 이미지 스타일 전이와 달리 음악에서는 동일 곡의 다중 스타일 정렬 데이터가 존재하지 않아 비지도 학습(예: Cycle‑GAN, VAE)에 의존해 왔으며, 그 결과 이미지에 비해 품질이 떨어지는 한계가 있었다. 저자들은 이 문제를 ‘합성 데이터’를 이용해 감독형 학습으로 전환한다.
데이터 생성 단계에서는 Band‑in‑a‑Box(BIAB)의 RealBand 엔진을 활용해 3,500곡 이상의 코드 차트를 70개의 스타일(‘Jazz Swing’, ‘Samba’, ‘Rock’, 등)로 자동 편곡한다. 각 곡은 8마디 단위로 절단되고, 겹치는 음표는 분할한다. 이렇게 만든 MIDI 파일은 4/4 또는 12/8 박자만을 남겨 필터링한다. 각 곡을 3개의 무작위 스타일로 편곡함으로써, 한 세그먼트당 6개의 (source, target) 페어가 생성되고, 전체 학습 세트는 약 658,000개의 예시를 포함한다. 검증·평가 세트는 각각 46곡씩 별도로 유지한다.
모델은 인코더‑디코더 구조를 기반으로 한다. 입력 표현은 두 가지가 있다. ① 피아노 롤: 128음 높이 × 4분음표당 4 타임스텝(즉, 16분음표 해상도)으로 이진 매트릭스를 만든 뒤, 2‑계층 CNN으로 차원을 압축하고, bidirectional GRU(1280 차원)로 시퀀스 정보를 통합한다. ② 이벤트 시퀀스: NoteOn(pitch), NoteOff(pitch), TimeShift(delta) 토큰으로 구성된 시퀀스를 임베딩 레이어와 bidirectional GRU에 입력한다. 두 경우 모두 인코더는 입력을 고정 길이 컨텍스트 시퀀스로 변환한다.
디코더는 GRU 기반이며, 목표 스타일 라벨(z)을 원‑핫 인코딩 후 임베딩한다. 어텐션 메커니즘은 인코더 출력 h_j에 가중치 α_{ij}를 부여해 현재 디코딩 단계 i의 컨텍스트 벡터 c_i = Σ_j α_{ij} h_j 를 만든다. 디코더 상태 s_i는 이전 상태 s_{i‑1}, 이전 출력 토큰 y_{i‑1}, 스타일 임베딩, 그리고 c_i를 결합해 계산한다. 출력은 소프트맥스 층을 통해 다음 토큰을 선택한다. 학습은 교차 엔트로피 손실을 최소화하며, Adam 옵티마이저와 학습률 감소, 조기 종료를 적용한다.
예측 단계에서는 greedy decoding을 기본으로 사용한다. 소프트맥스 온도를 조절한 샘플링을 실험했지만, 타이밍 오류와 비음악적 토큰이 증가해 품질이 저하되는 것으로 나타났다.
평가 지표는 두 부분으로 나뉜다. 첫째, 콘텐츠 보존을 측정하기 위해 소스와 생성물의 크로마 피처를 12프레임/비트로 추출하고, 2박자(24프레임) 윈도우 평균을 적용한 뒤, 프레임별 코사인 유사도를 평균한다. 이는 화성 진행이 동일하게 유지되는지를 정량화한다. 둘째, 스타일 적합도를 측정하기 위해 ‘스타일 프로파일’이라는 2‑D 히스토그램을 만든다. 4박자 이내·20세미톤 이내의 모든 음표 쌍을 대상으로 (시간 차, 피치 차)를 기록하고, 6분할(beat) × 1세미톤(음) 구간으로 히스토그램을 만든다(984 차원). 생성물과 목표 스타일의 프로파일 간 코사인 유사도로 스타일 일치를 평가한다.
실험 결과, 합성 데이터만으로 학습한 모델이 실제 MIDI에 대해 평균 콘텐츠 보존 점수 0.86(코사인)와 스타일 적합도 점수 0.78(코사인)을 달성했다. 청취자 설문에서는 70% 이상이 생성된 반주를 ‘자연스럽고 스타일에 부합한다’고 평가했으며, 특히 ‘Jazz Swing’→‘Samba’ 변환에서 리듬 패턴과 화성 진행이 잘 보존되는 것이 눈에 띄었다. 또한, 스타일 라벨을 조건으로 하는 단일 디코더는 n개의 스타일을 모두 다루면서 파라미터 수를 기존 다중 모델 대비 5배 이상 절감했다.
논문의 주요 기여는 다음과 같다. 1) 정렬된 합성 MIDI 데이터를 이용해 감독형 학습이 가능하도록 한 데이터 파이프라인 구축, 2) 목표 스타일을 조건화한 단일 디코더 기반 시퀀스‑투‑시퀀스 모델 제안, 3) 스타일 프로파일을 활용한 객관적 스타일 적합도 평가 지표 도입. 이 세 가지는 심볼릭 음악 스타일 변환 분야에서 비지도 접근법의 한계를 뛰어넘는 실용적 대안을 제공한다. 향후 연구는 (a) 다중 트랙 동시 생성 및 트랙 간 상호작용 모델링, (b) 인간 작곡가의 피드백을 반영한 강화학습, (c) 더 다양한 음악 장르와 비표준 박자에 대한 일반화 검증 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기