데이터 탐색을 위한 주성분 분석 완전 가이드
초록
본 논문은 주성분 분석(PCA)의 이론적 배경을 직관적으로 설명하고, 다양한 분야에서의 적용 사례를 포괄적으로 정리한다. 또한 표준화 여부가 PCA 결과에 미치는 영향을 실험적으로 검증하여, 연구자가 데이터 전처리 단계에서 올바른 선택을 할 수 있도록 돕는다.
상세 분석
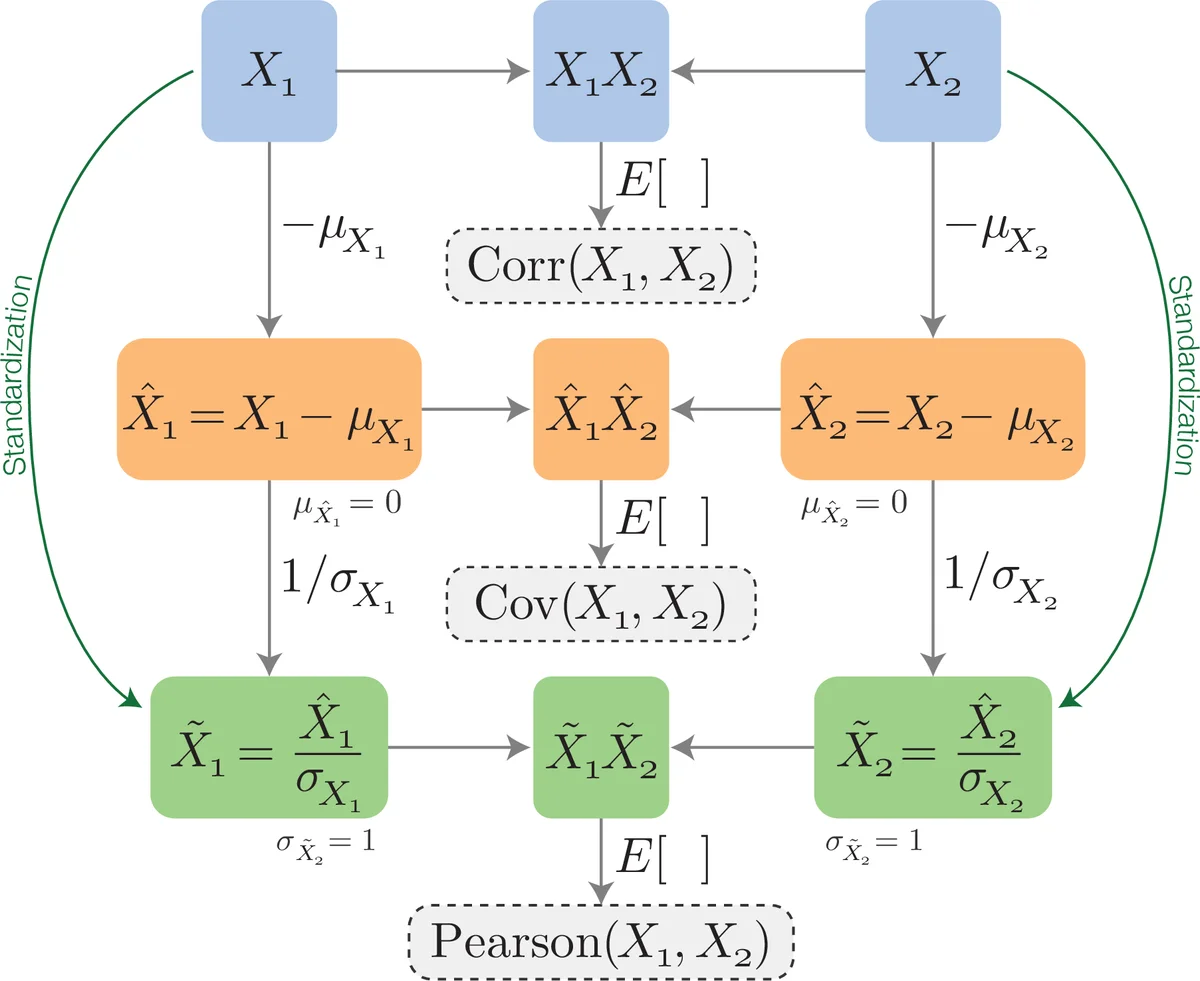
이 논문은 PCA를 데이터 과학의 기본 도구로 자리매김시키기 위해 세 가지 핵심 축을 제시한다. 첫째, 저자는 PCA의 수학적 근거를 ‘분산 최대화’라는 관점에서 재구성한다. 공분산 행렬의 고유값·고유벡터 분해를 통해 데이터의 주요 변동 방향을 찾는 과정을 상세히 설명하고, 이를 시각화한 2차원 예시(콩의 직경과 면적)로 직관성을 높였다. 둘째, 데이터 표준화(평균 0, 분산 1)와 비표준화가 PCA 축의 해석에 미치는 차이를 실험적으로 비교한다. 표준화된 데이터에서는 각 변수의 스케일 차이가 제거되어 고유값이 보다 균등하게 분포하고, 작은 분산을 가진 변수도 중요한 축에 기여할 가능성이 커진다. 반면 비표준화된 경우, 스케일이 큰 변수에 의해 첫 번째 주성분이 지배되며, 이는 실제 물리적 의미와 맞지 않을 수 있다. 이러한 결과는 ‘표준화 여부가 결과 해석에 결정적 영향을 미친다’는 중요한 교훈을 제공한다. 셋째, 저자는 PCA를 다른 차원 축소·분류 기법(LDA, ICA, 엔트로피 기반 방법)과 연계하는 전략을 제안한다. PCA를 사전 전처리 단계에 두어 데이터 차원을 크게 줄인 뒤, 보다 복잡한 비선형 방법을 적용하면 계산 비용이 감소하고 통계적 유의성이 향상된다. 또한, PCA 자체가 분산 기반이므로 클래스 구분을 위한 최적 축을 반드시 제공하지는 않으며, 이를 보완하기 위해 다중 투영 기법을 병행할 것을 권고한다. 논문 전반에 걸쳐 다양한 분야(생물학, 의학, 천문학, 화학, 공학 등)에서 PCA가 어떻게 활용됐는지 구체적인 사례를 제시함으로써, 독자가 자신의 연구 분야에 바로 적용할 수 있는 실용적인 로드맵을 제공한다. 특히, ‘PCA 축의 방향’, ‘회전’, ‘최대 분산 증명’ 등 고급 주제에 대한 수학적 증명과 직관적 설명을 동시에 제시해 초보자와 숙련자 모두에게 유익하다. 마지막으로, 저자는 실험 섹션에서 20여 개의 공개 데이터셋을 선정해, 표준화 여부에 따른 누적 분산 비율, 차원 축소 후 복원 오차, 그리고 시각적 biplot 해석을 정량적으로 비교한다. 결과는 대부분의 데이터셋에서 23개의 주성분만으로 전체 분산의 8095%를 설명할 수 있음을 보여주며, 표준화된 경우가 일반적으로 더 높은 압축 효율과 안정적인 축 선택을 제공한다는 결론을 도출한다. 이러한 체계적인 분석은 PCA를 데이터 탐색 초기 단계에서 필수 도구로 채택하도록 설득한다.
댓글 및 학술 토론
Loading comments...
의견 남기기