데이터 기반 블랙박스 이산 시스템의 불변 집합 계산
초록
본 논문은 분석 모델이 없는 비선형 이산시간 시스템에 대해, 시스템이 점근적으로 안정함을 전제로 최대 불변 집합(즉, 수렴 영역)을 데이터‑드리븐 방식으로 추정한다. 시나리오 최적화와 확률적 보장을 결합해 거의‑불변 집합을 정의하고, 긴 궤적을 이용한 불변 지평선 추정과 짧은 궤적을 활용한 집합 식별 절차를 제시한다. 내부·외부 근사 집합을 확률적 신뢰 구간으로 제공한다.
상세 분석
본 연구는 블랙박스 형태의 비선형 이산시간 시스템 (x(t+1)=f(x(t))) 에 대해, 전통적인 모델 기반 불변 집합 계산이 불가능한 상황을 다룬다. 저자는 시스템이 (X\subset\mathbb{R}^n) 내에서 점근적으로 안정하고 (f) 가 연속이며 (f(0)=0) 이라는 가정 하에, 최대 불변 집합 (O_\infty) 이 실제로는 도메인 (X) 내에서 모든 초기조건이 영점으로 수렴하는 영역과 동일함을 보인다(정리 1). 그러나 (f) 를 알 수 없으므로 직접적인 재귀식 (O_{k+1}=O_k\setminus{x\mid f(x)\notin O_k}) 을 구현할 수 없다.
이를 해결하기 위해 논문은 ‘거의‑불변 집합(ε‑almost‑invariant set)’을 도입한다. 정의에 따르면, 집합 (Z) 내에서 (f) 가 (Z) 밖으로 나가는 확률 (P{x\in Z\mid f(x)\notin Z}) 이 ε 이하이면 (Z) 는 ε‑거의‑불변 집합이다. 이 개념은 작은 측정값을 갖는 예외 집합을 허용함으로써, 유한 샘플만으로도 확률적 보장을 얻을 수 있게 한다.
데이터‑드리븐 검증 단계에서는 초기조건 (x_i) 를 (X) 에서 i.i.d. (P) 에 따라 추출하고, 각 초기조건에 대해 충분히 긴 궤적을 시뮬레이션한다. 집합 (O_k) 의 지표함수 (\mathbf{1}{O_k}(x)) 를 이용해 (\theta_k(\omega_N)=\frac{1}{N}\sum{i=1}^N\mathbf{1}{O_k}(x_i)) 를 계산한다. (\theta_k) 는 (k) 가 증가함에 따라 비감소이며, 어느 (k) 에서 (\theta_k=\theta{k+1}) 이 되면 그 (k) 을 (\bar t(\omega_N)) 라 정의한다. 정리 1은 (\bar t) 가 실제 (O_\infty) 에 충분히 근접할 확률을 (1-\frac{1}{\varepsilon}(1-\varepsilon)^N) 로 상한을 제공한다. 이는 샘플 수 (N) 가 (\ln(\varepsilon\beta)/\ln(1-\varepsilon)) 이상이면 (\varepsilon)‑거의‑불변 집합을 신뢰도 (1-\beta) 로 보장한다는 실용적 샘플 복잡도 식을 제시한다.
또한 논문은 첫 탈출 시간 (t^(x)=\min{t\mid \phi(t,x)\notin X}) 을 이용해 (\bar t) 보다 더 보수적인 (t^(\omega_N)=\max_i t^(x_i)) 을 정의한다. 보조 정리 2는 (t^) 를 사용했을 때 (P{S(t^*)\ge\varepsilon}\le(1-\varepsilon)^N) 이라는 더 강력한 상한을 얻으며, 이는 실제 구현에서 샘플이 하나라도 (O_k\setminus O_{k+1}) 에 포함될 경우 바로 검출 가능함을 의미한다.
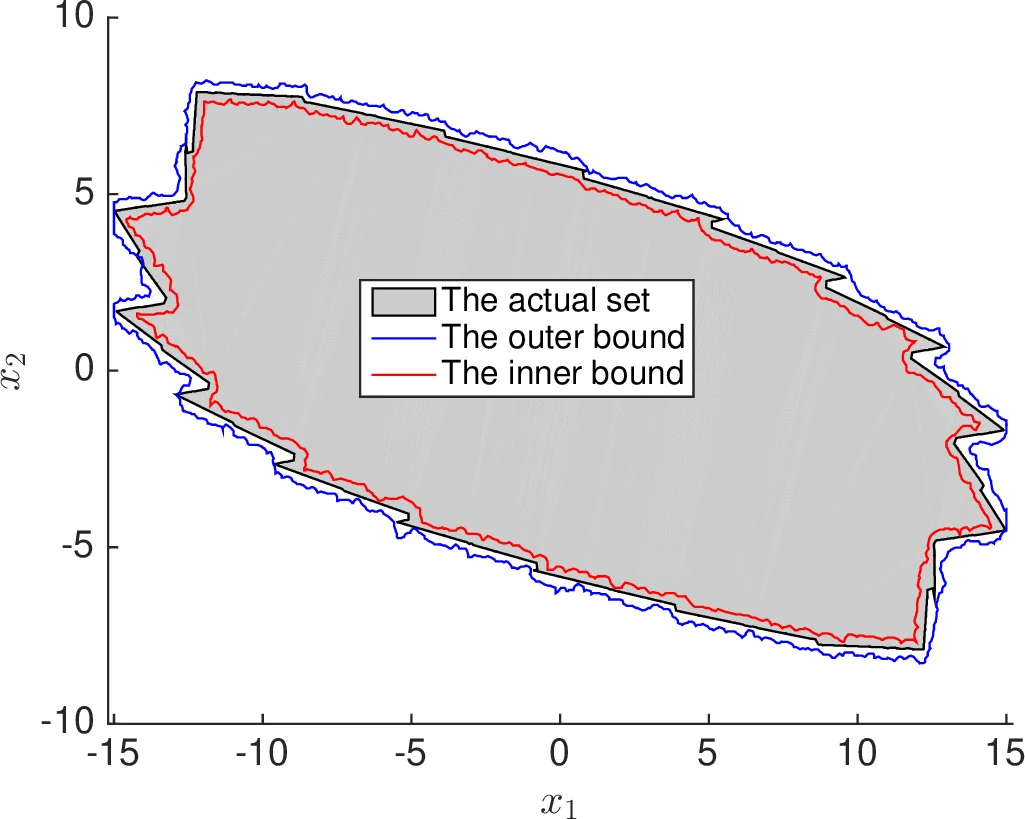
집합 식별 단계에서는 긴 궤적으로 얻은 (\bar t) 또는 (t^*) 에 기반해 암묵적인 거의‑불변 집합을 정의하고, 이를 다항식 혹은 다각형 형태의 명시적 집합으로 근사한다. 구체적으로, 다수의 짧은 궤적을 이용해 상태 공간을 격자화하고, 각 격자 셀에 대해 (\theta_k) 값을 추정한다. 내부 근사는 (\theta_k\ge 1-\varepsilon) 인 셀들을 모아 구성하고, 외부 근사는 (\theta_k>0) 인 셀들을 포함한다. 이렇게 얻은 두 집합은 각각 (\varepsilon)‑내부·외부 근사라 불리며, 확률적 보장은 앞서 제시된 시나리오 최적화 이론에 의해 그대로 이어진다.
복잡도 측면에서, 긴 궤적을 (L) 스텝 사용해 (\bar t) 를 추정하는 비용은 (O(NL))이며, 짧은 궤적을 격자화하는 비용은 (O(NM)) ((M)은 격자 셀 수)이다. 저자는 이 두 단계가 서로 보완적이며, 전체 알고리즘이 다항 시간 내에 실행 가능함을 강조한다. 마지막으로, 3~4개의 수치 예시(비선형 로봇 팔, 전력 시스템, 혼합 정수 비선형 모델 등)를 통해 제안 방법이 실제 시스템에 적용 가능하고, 기존 모델 기반 방법보다 샘플 효율성이 높음을 실증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기