성능 및 데이터 프로파일을 활용한 알고리즘 훈련 방법
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
**
본 논문은 파생‑무료 최적화기 BFO의 파라미터를 성능 프로파일과 데이터 프로파일을 직접 목표 함수로 삼아 자동 튜닝하는 새로운 방법을 제시한다. 두 프로파일을 면적 최대화하는 형태로 파라미터 탐색을 수행하고, 실험을 통해 평균 함수 평가 횟수를 최대 17 %까지 감소시키는 효과를 확인하였다.
**
상세 분석
**
이 논문은 기존에 알고리즘 파라미터 튜닝에 사용되던 평균·최악‑성능 최소화 방식(식 (1), (2))을 대체하거나 보완할 수 있는 새로운 접근법을 제시한다. 핵심 아이디어는 성능 프로파일 (p_s(\tau))와 데이터 프로파일 (d_s(\nu)) 자체를 “학습 목표 함수”로 전환하는 것이다.
- 데이터‑프로파일 기반 학습: 파라미터 집합 (Q)에 대해 (\phi_D^P(q)=\int_{\nu_{\min}}^{\nu_{\max}} d_{s_q}(\nu),d\nu) 를 정의하고, 이를 최대화하는 파라미터 (q)를 찾는다. 여기서 (\nu)는 문제 차원에 비례한 “예산”(단순히 단순히 심플렉스 그라디언트 평가 횟수)이며, (\nu_{\min},\nu_{\max})는 사용자가 지정하는 구간이다.
- 성능‑프로파일 기반 학습: 직접적인 비율 비교가 어려운 점을 보완하기 위해 기준 파라미터 (q_0)와의 차이를 적분한다. (\phi_P^P(q)=\int_{\tau_{\min}}^{\tau_{\max}} \bigl(p_{s_q}(\tau)-p_{s_{q_0}}(\tau)\bigr),d\tau) 를 최대화함으로써, 기존 파라미터 대비 전반적인 효율성을 향상시킨다.
두 방법 모두 파라미터 탐색 과정에서 “프로파일을 재계산”해야 하므로, 내부 최적화 루프에 BFO 자체를 사용한다는 메타‑최적화 구조를 갖는다. 실험에서는 55개의 연속형 무제한 문제(CUTEst)와 4가지 파라미터 구간(α,β,γ,δ,η,i)으로 구성된 BFO 파라미터 공간을 탐색하였다. - 실험 설정: 초기 파라미터 (q_0)를 기본값으로 두고, 각 파라미터에 대해 연속형이면 ±5 % 범위, 이산형이면 지정된 집합을 탐색하였다. 최적화 종료 기준은 함수값 허용오차 (\chi=10^{-4})와 최대 20 000 함수 평가(데이터‑프로파일) 혹은 (\tau_{\max}=20) (성능‑프로파일)이다.
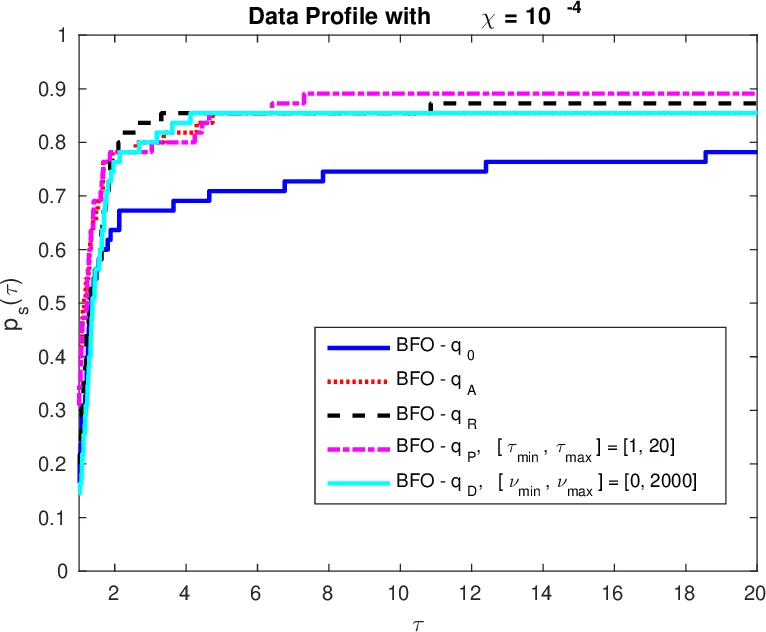
- 결과: 평균‑성능(식 (1)) 기반 학습((q_A))이 전체 함수 평가 횟수를 17 % 감소시켰으며, 견고성(식 (2)) 기반 학습((q_R))은 7 % 개선을 보였다. 데이터‑프로파일 기반 학습((q_D))은 데이터 프로파일 면적을 7 % 확대했으며, 성능‑프로파일 기반 학습((q_P))은 1 % 정도의 미세한 개선을 기록했다. 그래프(그림 1, 2)에서 볼 수 있듯, (q_P)는 성능‑프로파일에서 가장 높은 곡선을, (q_D)는 데이터‑프로파일에서 가장 높은 곡선을 형성한다.
- 파라미터 구간 효과: 데이터‑프로파일 학습 시 (
댓글 및 학술 토론
Loading comments...
의견 남기기