생물학을 위한 딥러닝 10가지 빠른 팁
초록
본 논문은 생물학 연구자가 딥러닝을 효과적으로 활용하도록 돕기 위해, 머신러닝 기본 원리부터 모델 검증, 결과 해석까지 실용적인 10가지 지침을 제시한다. 협업 작성 도구와 커뮤니티 의견을 반영해 접근성을 높였다.
상세 분석
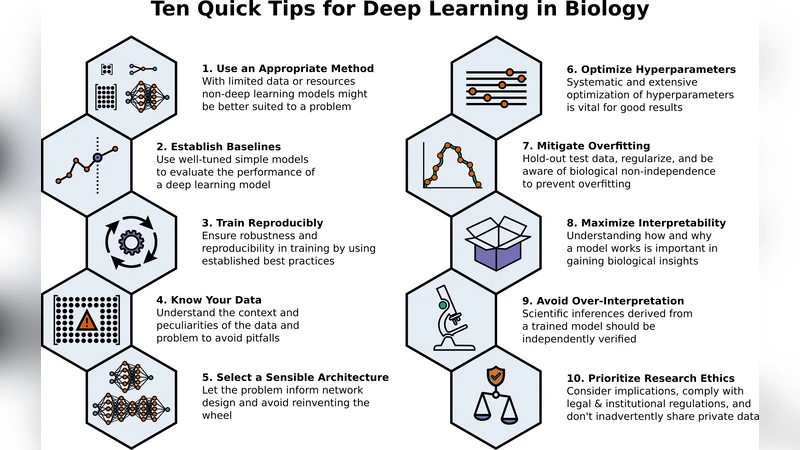
이 논문은 생물학 데이터의 고차원성, 잡음, 불균형 등 특수성을 고려한 딥러닝 적용 전략을 체계적으로 정리한다. 첫 번째 팁은 데이터 전처리와 탐색적 분석을 통해 변수 중요도와 분포를 파악하고, 필요 시 정규화·표준화·결측치 대체 등 기본적인 머신러닝 절차를 확실히 수행하라는 것이다. 두 번째는 적절한 모델 아키텍처 선택이다. 이미지 기반 연구라면 CNN, 시계열·유전체 데이터라면 RNN·Transformer, 구조적 데이터라면 MLP 혹은 그래프 신경망을 고려하되, 과도한 복잡성은 오버피팅 위험을 높인다는 점을 강조한다. 세 번째 팁은 하이퍼파라미터 튜닝이다. 학습률, 배치 크기, 정규화 기법(L2, dropout) 등을 그리드 서치·베이지안 최적화 등 체계적인 방법으로 탐색하고, 검증 데이터셋을 이용해 조기 종료(Early Stopping)를 적용한다. 네 번째는 모델 비교와 베이스라인 설정이다. 딥러닝 모델을 도입하기 전에 로지스틱 회귀·SVM·랜덤 포레스트 등 전통적인 머신러닝 모델을 베이스라인으로 구축하고, 동일한 데이터 분할과 평가 지표(AUROC, F1-score, PR-AUC 등)를 사용해 성능 차이를 정량화한다. 다섯 번째는 교차 검증과 데이터 스플리팅 전략이다. 특히 생물학 데이터는 실험 배치 효과와 시간적 의존성이 존재하므로, 그룹 기반 교차 검증(StratifiedGroupKFold)이나 시간 순서에 따른 검증을 적용해 일반화 오류를 최소화한다. 여섯 번째는 모델 해석 가능성이다. SHAP, LIME, Grad-CAM 등 포스트호크 해석 기법을 활용해 중요한 피처와 생물학적 의미를 도출하고, 결과를 도메인 전문가와 공동 검토한다. 일곱 번째는 재현성 확보이다. 코드와 환경을 Docker·Singularity 이미지로 캡슐화하고, 데이터와 모델 가중치를 공개 저장소에 버전 관리함으로써 다른 연구자가 동일 실험을 재현할 수 있게 한다. 여덟 번째는 실험 설계와 통계적 검증이다. 모델 성능 차이를 검증하기 위해 부트스트랩·퍼뮤테이션 테스트를 수행하고, p‑value와 신뢰 구간을 보고한다. 아홉 번째는 윤리적·법적 고려사항이다. 개인 유전체 데이터 등 민감 정보는 GDPR·HIPAA 등 규정을 준수하고, 모델이 편향을 학습하지 않도록 데이터 샘플링과 평등성 지표를 모니터링한다. 마지막 열 번째 팁은 지속적인 학습과 커뮤니티 참여이다. 최신 논문·오픈소스 라이브러리를 주기적으로 검토하고, GitHub·Manubot와 같은 협업 플랫폼을 활용해 피드백을 수집·반영한다. 전체적으로 논문은 딥러닝을 무작정 적용하기보다, 머신러닝 기본기를 튼튼히 하고, 체계적인 실험 설계와 엄격한 검증 절차를 거친 뒤에 적용하도록 권고한다. 이는 생물학 연구에서 과학적 신뢰성을 유지하면서도 최신 AI 기술의 이점을 최대한 활용할 수 있는 실용적인 로드맵을 제공한다.