딥러닝 컴파일러 종합 조사: 설계와 최적화의 모든 것
초록
본 논문은 TensorFlow XLA, TVM, Glow 등 주요 딥러닝 컴파일러들의 설계 구조를 체계적으로 분석한다. 특히 다중 레벨 중간 표현(IR)과 프론트엔드·백엔드 최적화 기법을 중심으로 비교·분류하고, CNN 모델에 대한 정량적 성능 평가와 향후 연구 방향을 제시한다.
상세 분석
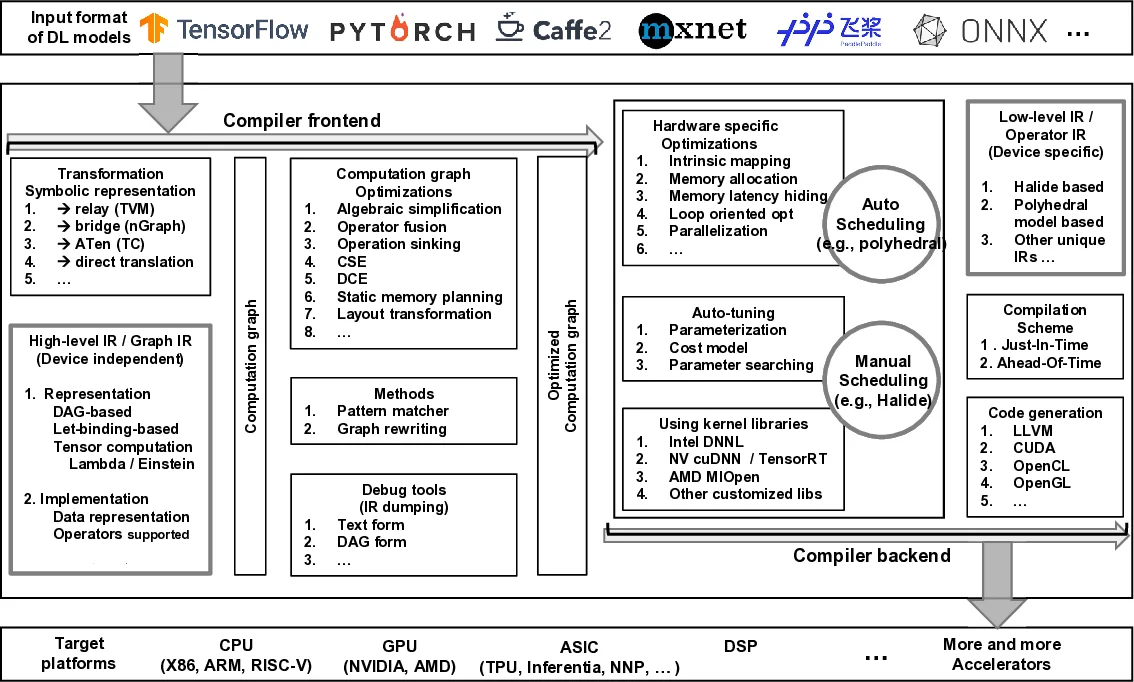
딥러닝 컴파일러는 기존 일반 목적 컴파일러와 달리 모델 수준의 연산 그래프와 하드웨어 특화 연산을 동시에 다루어야 한다는 점에서 독특한 설계 요구를 가진다. 논문은 이러한 요구를 충족하기 위해 대부분의 컴파일러가 채택하고 있는 3단계 구조—프론트엔드, 다중 레벨 IR, 백엔드—를 상세히 분해한다. 프론트엔드에서는 ONNX와 같은 공통 모델 포맷을 파싱하고, 연산자 레벨(node‑level), 블록 레벨(block‑level), 데이터 흐름 레벨(flow‑level)에서 초기 최적화를 수행한다. 다중 레벨 IR은 고수준 연산 그래프(IR‑1), 연산자 중심의 중간 표현(IR‑2), 그리고 하드웨어 친화적인 저수준 스케줄링·메모리 배치(IR‑3)로 구성되며, 각 단계마다 연산자 융합, 루프 변환, 텐서 재배치 등 특화된 변환이 적용된다. 백엔드에서는 타깃 하드웨어의 ISA와 메모리 계층 구조에 맞춘 코드 생성, 자동 튜닝(auto‑tuning) 파이프라인, 그리고 cuDNN·MKL‑DNN·TensorRT와 같은 최적화된 커널 라이브러리 연동이 핵심이다. 논문은 이러한 설계 흐름을 기반으로 TVM, XLA, Glow, nGraph 등 7여 개 컴파일러를 기능·지원 하드웨어·IR 구조·최적화 기법 측면에서 표형식으로 정리하고, 특히 IR 설계의 차이가 최종 성능에 미치는 영향을 실험적으로 입증한다. 또한 동적 shape 지원, 차별화된 양자화, 차분 가능 프로그래밍(differentiable programming) 등 최신 연구 트렌드를 미래 과제로 제시하며, 현재 대부분의 컴파일러가 정적 그래프와 고정 정밀도에 집중하고 있음을 지적한다. 이러한 분석은 연구자에게 설계 선택의 트레이드오프를 명확히 보여주고, 실무자에게는 프로젝트 요구에 맞는 컴파일러 선택 기준을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기