이커머스 검색 결과 통합을 위한 계층 강화학습
초록
본 논문은 이커머스 환경에서 서로 다른 수직(vertical) 검색 엔진이 제공하는 결과를 페이지별로 동적으로 결합하는 문제를 다룬다. 고수준 정책이 페이지마다 어떤 수직을 노출할지 결정하고, 저수준 정책이 선택된 수직의 아이템을 슬롯에 순차적으로 채우는 방식으로 문제를 계층적 강화학습(HRL) 프레임워크에 매핑한다. 실험 결과, 제안 모델은 클릭률(CTR)·구매 전환(GMV) 등 핵심 비즈니스 지표에서 기존 방법들을 크게 능가한다.
상세 분석
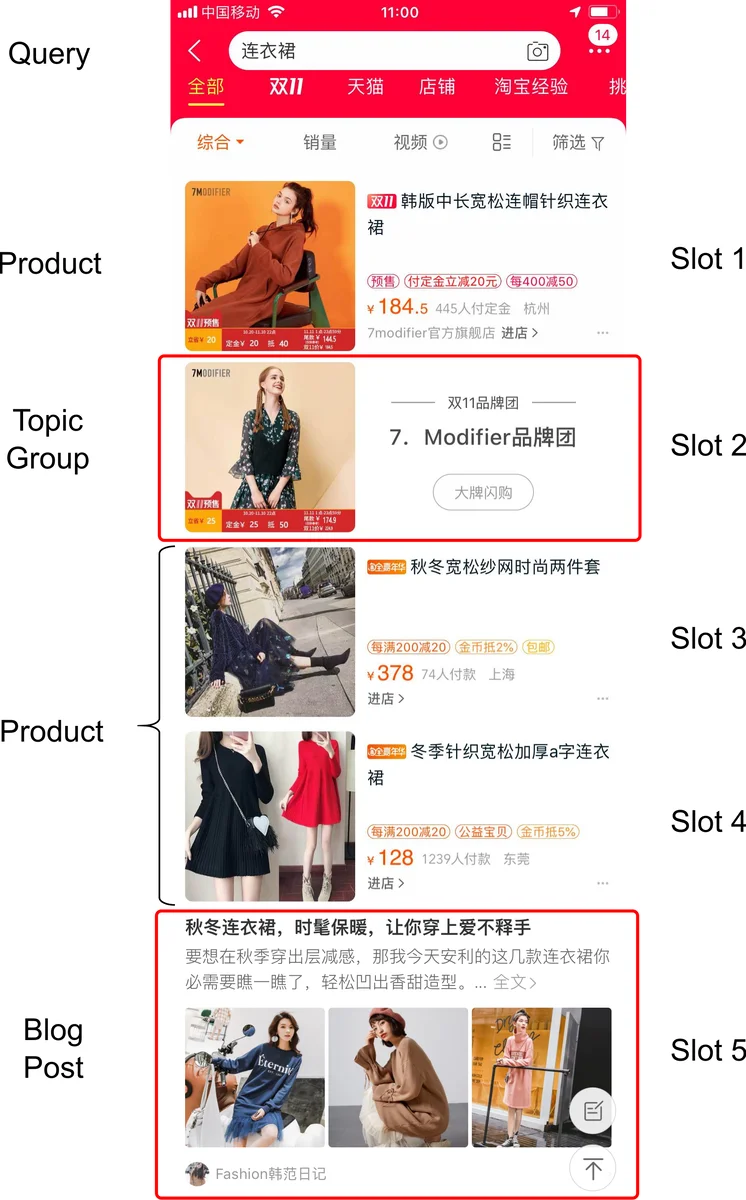
이 논문은 기존 웹 검색에서 보이는 ‘첫 페이지만의 집합적 결과 제시’와 달리, 이커머스 검색은 사용자가 스크롤하거나 페이지를 넘길 때마다 새로운 결과 집합을 제공해야 하는 특성을 지적한다. 이러한 특성은 두 가지 핵심 난제를 만든다. 첫째, 사용자가 이전 페이지에서 어떤 아이템을 클릭했는지, 어떤 브랜드·카테고리에 관심을 보였는지를 기반으로 현재 페이지에 어떤 수직(vertical) 소스를 노출할지 순차적인 의사결정이 필요하다. 둘째, 서로 다른 수직에서 반환되는 아이템은 각기 다른 relevance 모델에 의해 점수가 매겨지므로, 단순히 점수를 비교해 순서를 정하는 것이 불가능하다(‘relevance ranking issue’).
저자는 이 두 문제를 각각 고수준(source selection)과 저수준(item presentation) 정책으로 분리하고, 이를 반영한 Semi‑Markov Decision Process(SMDP) 형태의 계층 강화학습 구조를 설계한다. 고수준 정책은 옵션(option) 개념을 차용해, 현재 페이지에서 선택할 수 있는 수직 조합을 하나의 다중‑스텝 행동으로 정의한다. 옵션의 크기는 2^N (N은 수직 종류)이며, 핵심 검색(상품) 수직은 반드시 포함된다. 고수준 상태은 검색 요청(x), 이전 페이지에서의 사용자 행동 로그, 현재까지 노출된 아이템들의 메타데이터 등을 포함한다.
저수준 정책은 ‘슬롯 채우기(slot filling)’ 문제로 전환된다. 페이지 내 각 위치를 슬롯으로 보고, 현재 남아있는 후보 아이템 풀에서 가장 기대 보상이 높은 아이템을 선택해 슬롯에 배치한다. 이때 보상은 클릭, 구매, 체류 시간 등 암시적 피드백을 기반으로 정의되며, 즉시 보상(외재적 reward)과 장기 보상(내재적 reward)을 모두 고려한다. 저수준 정책 역시 DQN 구조를 사용해 Q‑value를 추정하고, ε‑greedy 탐색을 통해 학습한다.
핵심 기여는 다음과 같다. (1) 고수준 옵션 기반 정책을 통해 페이지 간 사용자 행동 패턴을 모델링함으로써 동적인 수직 선택을 가능하게 했다. (2) 저수준을 슬롯 채우기 문제로 재구성해, 서로 다른 소스의 아이템을 직접 비교하는 대신 순차적인 선택 과정을 통해 자연스럽게 순위를 결정했다. (3) 두 정책을 동시에 학습시켜, 현재 페이지의 즉각적인 피드백과 전체 세션에 걸친 장기 피드백을 모두 활용했다.
실험은 타오바오(Alibaba)의 실제 검색 로그를 이용해 수행했으며, 베이스라인으로는 전통적인 수직 선택기(이진 분류기)와 점수 기반 아이템 병합 모델, 그리고 최신 attention‑based 순위 모델을 포함한다. 제안 모델은 CTR 12.4% 향상, GMV 9.8% 상승 등 실질적인 비즈니스 지표에서 유의미한 개선을 보였다. 또한, 옵션 수가 늘어나도 학습 안정성이 유지되며, 페이지당 평균 응답 시간도 상용 시스템 수준에 머물렀다.
이 연구는 강화학습을 실제 대규모 이커머스 서비스에 적용한 드문 사례이며, 특히 사용자 행동의 장기 의존성을 고려한 계층적 의사결정 구조가 다른 멀티‑소스 추천·검색 문제에도 확장 가능함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기