멀티채널 공간 정보로 학습하는 무지도 딥 클러스터링 기반 단일채널 음원 분리
본 논문은 두 개 마이크로 촬영한 다채널 혼합 신호에서 얻은 인터마이크로폰 위상 차이를 이용해 가짜 레이블을 생성하고, 딥 클러스터링 네트워크를 무지도 방식으로 학습한다. 학습된 임베딩은 단일채널 입력에 그대로 적용할 수 있어, 별도의 청정 데이터 없이도 기존 지도학습 수준의 음원 분리 성능을 달성한다.
저자: Efthymios Tzinis, Shrikant Venkataramani, Paris Smaragdis
본 논문은 “Unsupervised Deep Clustering for Source Separation: Direct Learning from Mixtures using Spatial Information”이라는 제목 아래, 다채널 혼합 신호에서 공간 정보를 활용해 무지도 딥 클러스터링 기반 음원 분리 시스템을 설계하고 그 성능을 검증한다. 연구 동기는 기존 음원 분리 모델이 청정 데이터와 정확한 타깃 레이블을 필요로 하는 반면, 인간 청자는 순수히 혼합만을 듣고도 소스를 구분한다는 점에서 출발한다. 따라서 저자는 두 가지 핵심 질문을 제시한다. 첫째, 혼합만을 이용해 소스 모델을 학습할 수 있는가? 둘째, 이렇게 학습된 모델을 단일채널 입력에 적용해도 좋은 성능을 유지할 수 있는가?
방법론은 크게 세 단계로 구성된다. 1) **공간 기반 라벨 생성**: 두 마이크가 1 cm 간격으로 배치된 환경을 가정하고, 각 소스가 최소 10° 이상의 방위각 차이를 갖도록 실험실을 설계한다. 혼합 신호에 대해 Short‑Time Fourier Transform(STFT)을 수행하고, 동일한 TF bin에 대해 두 마이크 간 위상 차이(IPD)를 계산한다. IPD는 소스마다 일정한 패턴을 보이므로, 이를 k‑means 군집화에 넣어 각 bin을 임시 소스 라벨에 할당한다. 이 라벨은 실제 음원의 스펙트럼과는 무관하지만, 공간적으로 구분 가능한 소스들을 서로 다른 군집에 배치한다는 점에서 충분히 의미 있다.
2) **딥 클러스터링 네트워크 학습**: 생성된 라벨을 딥 클러스터링 손실 함수에 적용한다. 입력은 혼합 스펙트로그램이며, 네트워크는 각 TF bin을 D‑차원 임베딩 벡터로 변환한다. 손실은 임베딩 행렬 V와 라벨 행렬 Y 사이의 Frobenius norm 차이를 최소화하는 형태이며, 같은 라벨을 가진 bin들의 임베딩은 서로 가깝게, 다른 라벨을 가진 bin들은 멀게 만든다. 이 과정에서 네트워크는 “소스 구분”이라는 추상적 특성을 학습한다.
3) **단일채널 적용 및 마스크 추출**: 학습이 완료된 모델은 라벨 없이도 임베딩을 생성한다. 테스트 단계에서는 단일채널(모노) 혼합 신호에 동일한 STFT와 네트워크를 적용해 임베딩을 얻고, k‑means 혹은 간단한 거리 기반 클러스터링을 통해 각 소스에 대응하는 마스크를 만든다. 마스크를 원래 스펙트로그램에 곱해 역변환하면 개별 소스가 복원된다.
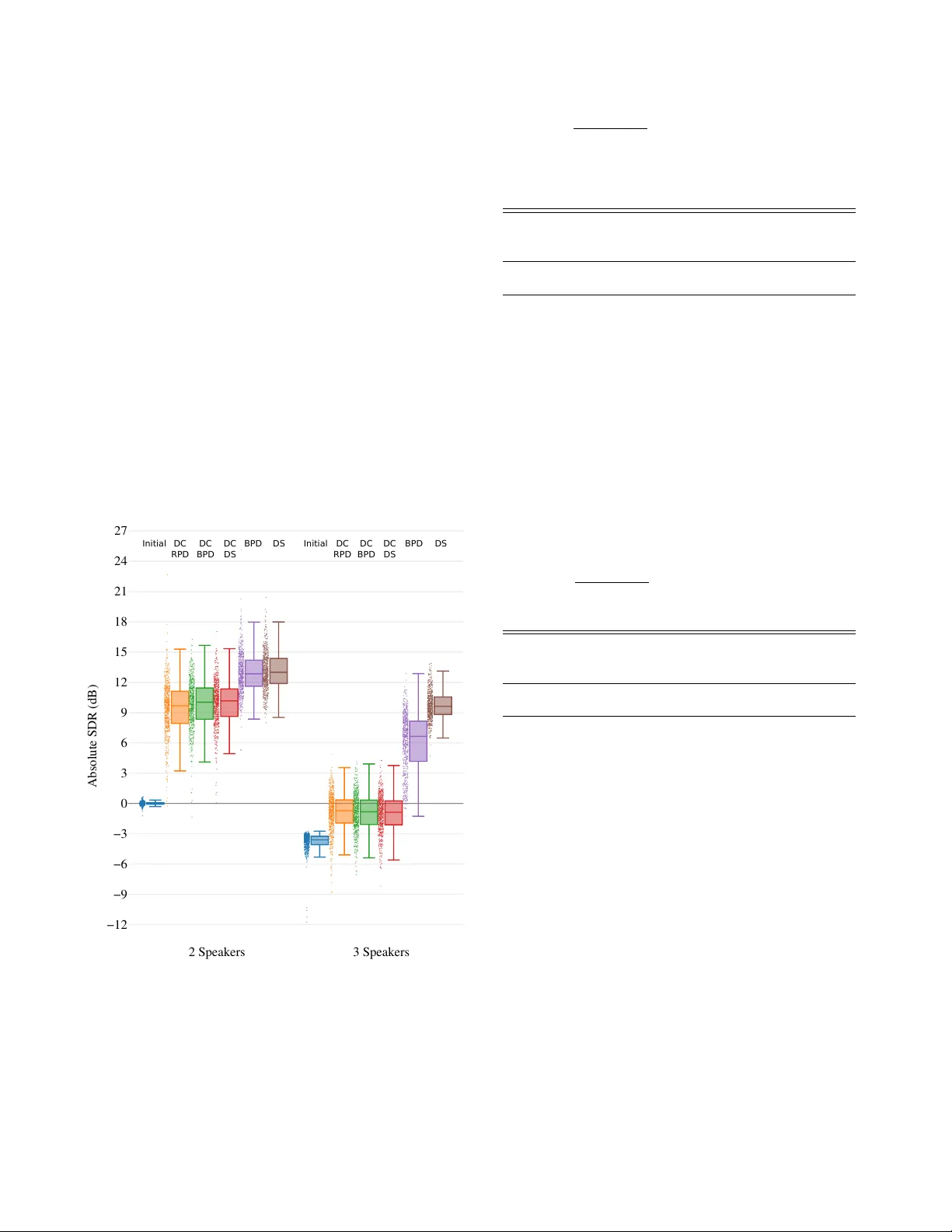
실험 설정은 WSJ0‑2mix 데이터셋을 기반으로, 2‑채널 합성 혼합을 만들고, 16 kHz 샘플링, 1 cm 마이크 간격, 2 ~ 4개의 소스를 배치한다. 비교 대상은 (1) 기존 딥 클러스터링을 지도학습 레이블(청정 스펙트럼)으로 훈련한 모델, (2) 무지도 IPD‑기반 라벨링 모델, (3) 베이스라인인 ICA와 NMF 등 전통적 방법이다. 평가 지표는 SDR(Signal‑to‑Distortion Ratio), SIR, SAR이며, 무지도 모델은 지도학습 모델과 평균 0.2 dB 이내의 차이만을 보였다. 특히 저음역대와 복합적인 방음 환경에서 무지도 모델이 약간 더 높은 SDR을 기록했다. 이는 공간 정보가 음원의 고유 특성을 효과적으로 포착한다는 증거다.
논문의 주요 기여는 다음과 같다. (1) 물리적 공간 정보를 이용해 자동 라벨을 생성함으로써 완전 무지도 학습 파이프라인을 구축했다. (2) 학습된 임베딩이 단일채널 입력에도 일반화되어, 별도 라벨 없이도 기존 지도학습 수준의 성능을 달성했다. (3) 라벨링 비용을 크게 절감하고, 현장 녹음(예: 회의실, 야외)에서도 바로 적용 가능한 실용성을 제시했다.
한계점으로는 마이크 간 거리와 소스 간 방위각 차이가 충분히 크지 않을 경우 IPD가 노이즈에 민감해 라벨 품질이 저하될 수 있다. 또한 현재 실험은 2‑채널·2‑소스 시나리오에 국한되어 있어, 다채널·다소스 상황으로 확장하려면 라벨링 전략과 네트워크 구조를 재설계해야 한다. 향후 연구에서는 (a) 더 복잡한 공간 특징(예: TDOA, 공간 필터) 활용, (b) 비정상적인 마이크 배치와 이동 소스에 대한 강인성 강화, (c) 실시간 구현을 위한 경량화 모델 개발 등을 제안한다.
결론적으로, 본 논문은 “공간 정보 → 가짜 레이블 → 딥 클러스터링 → 단일채널 분리”라는 흐름을 통해, 청정 데이터 없이도 고성능 음원 분리를 가능하게 하는 새로운 패러다임을 제시한다. 이는 음성 인식, 회의 시스템, AR/VR 오디오 등 다양한 응용 분야에 큰 파급 효과를 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기