비표준 음성 맞춤형 자동음성인식 제한 데이터 활용
본 논문은 ALS 환자와 강한 억양을 가진 화자를 대상으로, 기존의 대규모 표준 음성 모델을 소량의 개인화 데이터(5~10분)만으로 미세조정(fine‑tuning)하여 워드 오류율(WER)을 크게 낮추는 방법을 제시한다. RNN‑Transducer와 LAS 두 아키텍처를 실험했으며, 인코더 일부(특히 첫 레이어와 joint layer)만 조정해도 전체 모델을 조정한 것과 동등한 성능 향상을 얻는다. 결과적으로 ALS 경증 화자에서 절대 WER …
저자: Joel Shor, Dotan Emanuel, Oran Lang
본 논문은 비표준 음성, 즉 근위축성 측삭경화증(ALS) 환자와 강한 억양을 가진 비원어민 화자를 대상으로, 기존의 대규모 표준 음성 기반 자동음성인식(ASR) 시스템을 소량의 개인화 데이터만으로 효과적으로 맞춤화하는 방법을 제시한다. 연구 배경으로는 현재 상용 ASR 모델이 수천 시간 규모의 ‘전형적인’ 음성 데이터에 기반해 훈련되며, 데이터에 충분히 대표되지 않은 집단—특히 의료적 장애를 가진 화자나 억양이 강한 화자—에 대해서는 인식 성능이 크게 저하된다는 점을 들었다. 이러한 문제를 해결하기 위해, 저자들은 두 가지 주요 접근법을 채택했다. 첫째, 대규모 표준 음성 데이터(1000시간 Librispeech)로 사전 학습된 베이스 모델을 활용한다. 둘째, 각 화자별로 제한된 양(5~10분)의 녹음 데이터를 사용해 모델을 미세조정(fine‑tuning)한다.
베이스 모델은 두 가지 최신 아키텍처를 사용했다. 첫 번째는 5‑layer 양방향 Convolutional LSTM 인코더와 2‑layer LSTM 디코더, 그리고 joint layer를 포함한 RNN‑Transducer(RNN‑T)로, 총 파라미터 수는 약 49.6 M이다. 두 번째는 4‑layer 양방향 Convolutional LSTM 인코더와 2‑layer RNN 디코더를 갖춘 Listen, Attend, and Spell(LAS) 모델이며, 파라미터 수는 132 M에 달한다. 두 모델 모두 80‑bin 로그멜 스펙트로그램을 25 ms 윈도우, 10 ms 홉으로 추출하고, 3‑프레임을 하나의 ‘슈퍼프레임’으로 합쳐 입력한다. 또한 다중조건 훈련(MTR) 기법을 적용해 방음실 시뮬레이터와 12 dB 평균 SNR의 잡음을 추가함으로써 실제 환경에 대한 강인성을 확보했다.
데이터는 두 종류로 구성되었다. ALS 데이터는 ALS Therapy Development Institute와 협업해 수집한 36.7시간(67명)의 녹음 중, 기능적 등급(FRS) 3 이하인 17명(22.1시간)만을 평가에 사용했다. 문장은 Cornell Movie‑Dialogs, 텍스트‑투‑스피치용 문장, 그리고 Boston Children’s Hospital에서 변형한 문장 등으로 구성돼, 어휘는 제한적이지만 음소 다양성은 충분히 확보되었다. 억양 데이터는 L2‑Arctic 데이터셋을 활용했으며, 20명의 비원어민 화자 각각 약 1시간의 발화를 제공한다. 각 화자는 90 %를 훈련, 10 %를 테스트에 할당했으며, 테스트에 포함된 고유명사는 훈련에서 제외해 과적합을 방지했다.
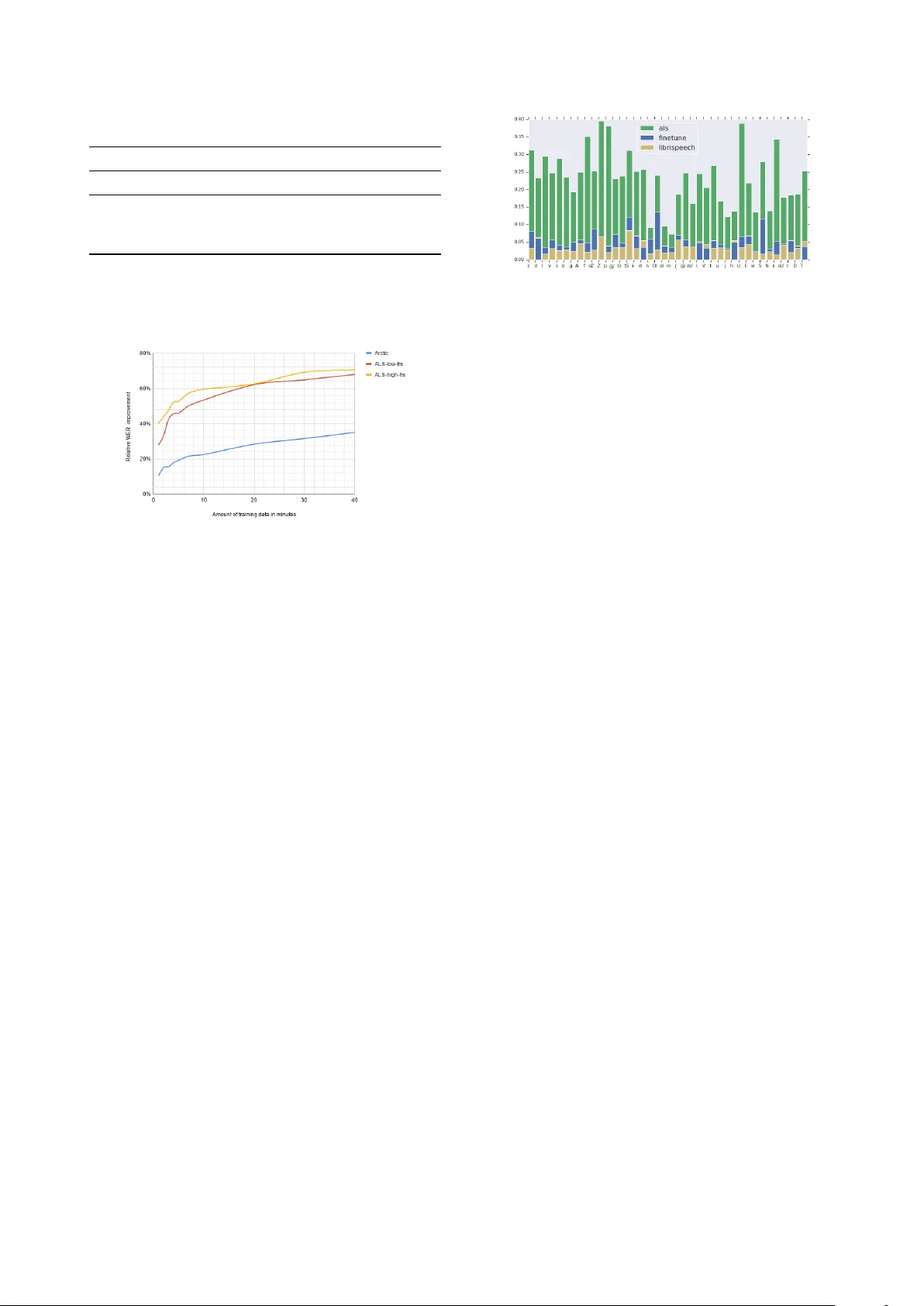
미세조정 실험에서는 RNN‑T와 LAS 각각에 대해 다양한 레이어 조합을 탐색했다. RNN‑T의 경우, 인코더 레이어를 E0(입력에 가장 가까운 레이어)부터 순차적으로 포함시키는 방식을 사용했으며, 실험 결과 ‘joint layer + 첫 번째 인코더 레이어(E0)’만을 업데이트해도 전체 인코더를 모두 업데이트했을 때와 거의 동일한 성능 향상을 얻을 수 있었다. 구체적으로, 이 조합은 전체 상대 WER 개선의 91 %를 차지했으며, ALS 화자 전체 평균 WER은 18.1 %에서 15.1 %로 감소했다. 반면 LAS 모델은 레이어별 차이가 크게 나타나지 않아, 전체 네트워크를 모두 미세조정하는 것이 최적이었다.
데이터 양에 대한 민감도 분석 결과, ALS 데이터에서는 5분(≈0.08 h)만으로도 전체 개선의 71 %를 회복했으며, 10분이면 80 %에 도달했다. 억양 데이터에서도 14분과 20분이 각각 전체 개선의 70 %와 81 %를 제공했다. 이는 소량의 개인화 데이터만으로도 비표준 발음 특성을 충분히 학습할 수 있음을 시사한다.
음소 오류 분석을 통해, 표준 음성 대비 ALS 음성에서 삭제 오류가 가장 많이 발생하는 다섯 음소(p, U, f, k, Z)가 전체 오류의 20 %를 차지한다는 것을 발견했다. 삽입·대체 오류는 n과 m이 주를 이루며, 전체 오류의 17 %를 차지한다. 미세조정 후에는 이러한 오류 분포가 표준 음성 모델과 유사해졌으며, KL divergence가 0.26에서 0.10으로 크게 감소했다. 이는 미세조정이 단순히 개별 화자에 특화된 패턴을 학습하는 것이 아니라, 비표준 발음 전반에 걸친 일반적인 오류 패턴을 교정한다는 증거다.
최종 성능은 다음과 같다. ALS 경증(FRS = 3) 화자에서는 절대 WER 10.8 %를 달성했으며, 중증(FRS = 1‑2) 화자에서는 20.9 %까지 낮췄다. 억양 화자에서는 8.5 %의 절대 WER를 기록했다. 이는 기존 Google Cloud ASR(스트리밍 전용, 역방향만 사용) 대비 35 %~62 %의 상대 개선에 해당한다. 또한, 미세조정에 사용된 컴퓨팅 자원은 4대의 Tesla V100 GPU를 4시간 이하로 사용했으며, 이는 실용적인 서비스 배포 수준이다.
논문은 이러한 결과를 바탕으로 다음과 같은 결론을 내렸다. (1) 제한된 개인화 데이터만으로도 대규모 사전학습 모델을 효과적으로 비표준 음성에 적응시킬 수 있다. (2) 인코더 초반부와 joint layer만 선택적으로 학습함으로써 파라미터 효율성을 크게 높일 수 있다. (3) RNN‑T와 LAS 두 아키텍처 모두에서 개선 효과가 확인되었으며, 특히 RNN‑T는 인코더만 미세조정해도 충분한 성능 향상이 가능했다. (4) 향후 연구에서는 다수 화자를 대상으로 한 공동 모델 학습, 완전히 다른 도메인(예: 의료 기록)에서의 일반화, 그리고 훈련 문장과 테스트 문장의 내용 차이가 큰 경우의 성능 변화를 조사할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기