활성학습과 인간‑인‑루프 딥러닝을 활용한 의료 영상 분석
본 리뷰는 의료 영상 분석에 딥러닝을 적용할 때 인간 전문가의 지속적인 참여가 왜 필수적인지를 논의한다. 활성학습, 모델 출력과의 상호작용, 실용적 배포 고려사항, 그리고 향후 연구 과제를 네 가지 핵심 영역으로 정리하고, 각 영역별 최신 방법론과 연구 동향을 제시한다.
저자: Samuel Budd, Emma C Robinson, Bernhard Kainz
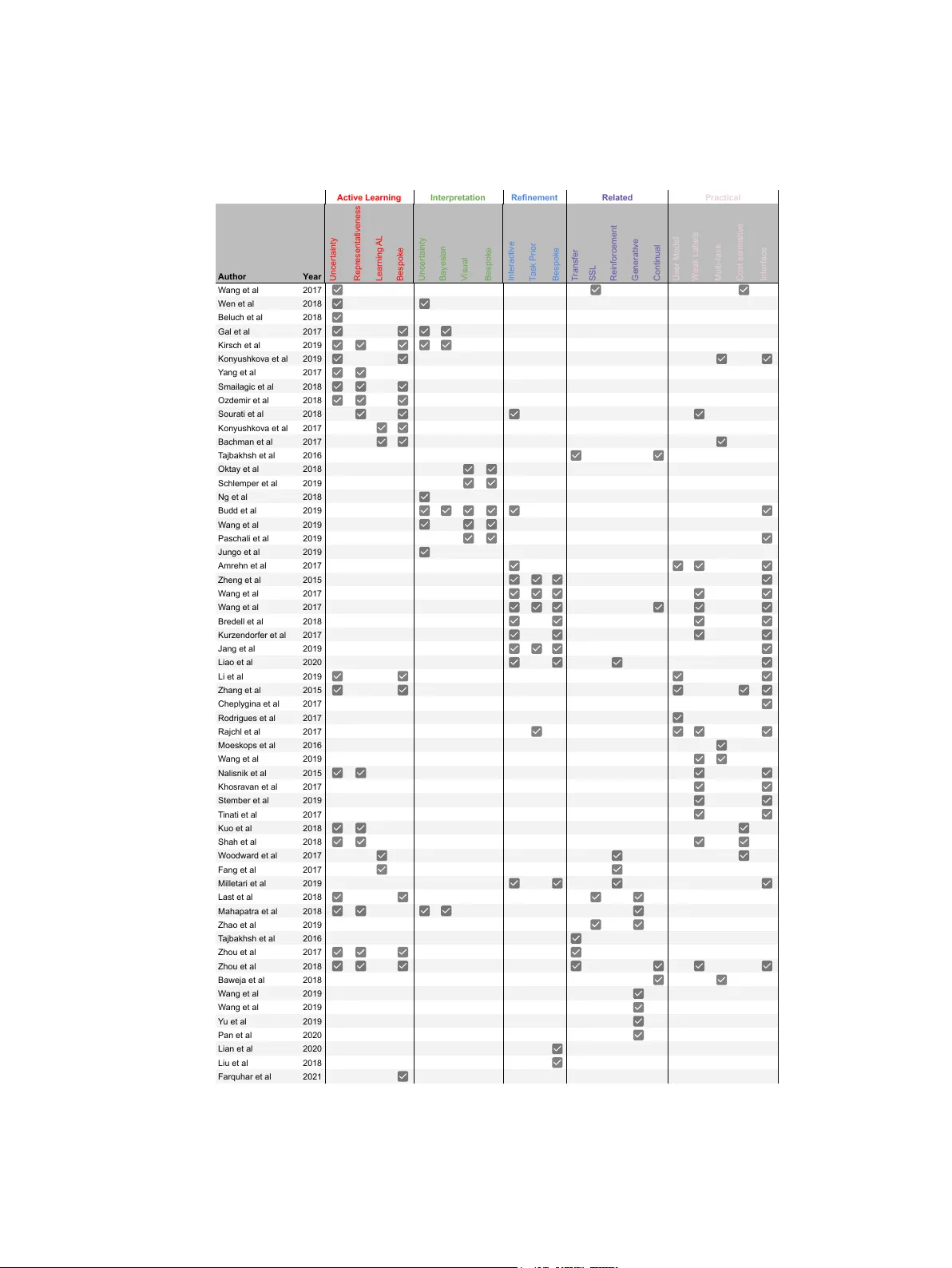
이 리뷰는 의료 영상 분석에 딥러닝을 적용하면서 발생하는 고유한 제약을 극복하기 위해 인간‑인‑루프(HITL) 컴퓨팅이 왜 중요한지를 체계적으로 탐구한다. 서론에서는 의료 영상이 임상 의사결정의 핵심임을 강조하고, 방사선과 전문인력 부족, 데이터 라벨링 비용, 도메인 간 차이, 모델의 블랙박스 특성 등 세 가지 주요 도전 과제를 제시한다. 이러한 문제는 기존의 완전 자동화된 딥러닝 파이프라인이 임상 현장에 바로 적용되기 어렵게 만든다.
첫 번째 핵심 영역인 활성학습(AL)은 라벨링 비용을 최소화하면서 모델 성능을 최적화하는 전략이다. 논문은 스트림 기반, 합성 기반, 풀 기반 세 가지 쿼리 타입을 상세히 설명한다. 스트림 기반은 실시간 데이터 흐름에서 즉시 불확실성을 판단해 라벨을 요청하지만 탐색‑활용 균형이 약하고 임계값 설정이 까다롭다. 합성 기반은 GAN 등 생성 모델을 활용해 가상의 샘플을 만들고 라벨을 얻지만, 인간 오라클이 이해하기 어려운 비현실적 샘플을 제시할 위험이 있다. 풀 기반은 대규모 미라벨 데이터 풀에서 모델이 예측한 불확실성을 기반으로 배치 단위로 샘플을 선택한다. 이는 딥러닝의 배치 학습과 자연스럽게 맞물리며, 현재 가장 널리 사용되는 방식이다.
정보성 측정 방법으로는 전통적인 불확실성 기반(least‑confident, margin, entropy)과 모델 파라미터 변화량 기반, 그리고 최근 메타‑학습·강화학습을 통한 정책 학습이 논의된다. 특히 딥러닝 모델의 파라미터 수가 방대해지면서 기존 휴리스틱이 계산 비용 면에서 비효율적임을 지적하고, 데이터‑드리븐 정책 학습이 향후 대안이 될 수 있음을 제시한다.
두 번째 영역은 모델 출력과 인간의 상호작용이다. 여기서는 예측 결과에 대한 시각적 해석 기법(CAM, Grad‑CAM, attention map)과 함께, 사용자가 직접 예측을 교정하거나 불확실성을 피드백으로 제공하는 반복 학습 루프를 강조한다. 이러한 인터랙션은 모델의 투명성을 높이고, 임상의가 자동화된 결과를 신뢰하도록 돕는다. 또한, 불확실성 전달(uncertainty quantification)과 설명 가능한 AI(XAI) 기법을 결합해 ‘왜 이 예측이 나왔는가’를 명확히 제시함으로써 법적·윤리적 요구사항을 충족한다.
세 번째 파트에서는 실용적 배포 고려사항을 다룬다. 데이터 프라이버시와 규제(예: GDPR, FDA) 준수, 클라우드‑엣지 혼합 아키텍처, 지속적인 모델 모니터링 및 업데이트, 사용자 인터페이스 설계, 그리고 다기관 협업을 위한 연합학습(federated learning) 등이 핵심 이슈로 제시된다. 특히 의료 현장에서 시스템이 중단 없이 운영되기 위해서는 자동화된 파이프라인과 인간 검증 단계가 원활히 연결돼야 함을 강조한다.
마지막으로 미래 전망과 미해결 질문을 제시한다. 멀티‑모달 학습(이미지·텍스트·임상 데이터 통합), 자기‑지도 학습, 대규모 사전학습 모델(Foundation Model)과 활성학습의 결합, 그리고 인간 피드백을 통한 지속적 학습(continual learning) 등이 향후 연구 방향으로 제시된다. 또한, 인간 오라클의 피로도 관리, 라벨링 품질 보증, 비용‑효율성 평가 등 실질적인 운영 문제도 해결해야 할 과제로 남아 있다.
결론적으로, 논문은 인간 전문가의 지식과 딥러닝의 자동화 능력을 최적 시점에 결합함으로써 의료 영상 분석의 정확도, 효율성, 투명성을 동시에 향상시킬 수 있음을 설득력 있게 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기