신경 가소성 네트워크
본 논문은 인간 두뇌의 가소성 현상을 모방하여, 신경망의 유닛(가중치·뉴런·채널 등)에 이진 게이트를 부착하고 L₀ 정규화를 통해 활성·비활성 전이를 학습한다. 단일 파라미터 k 로 사전학습·희소화·미세조정의 세 단계와 드롭아웃·전통 학습을 자연스럽게 연결하며, 초기 네트워크 규모에 관계없이 자동으로 축소하거나 확장한다. 실험 결과, 합성 데이터와 이미지 분류 벤치마크에서 기존 프루닝·확장 기법보다 우수한 압축률과 정확도를 달성한다.
저자: Yang Li, Shihao Ji
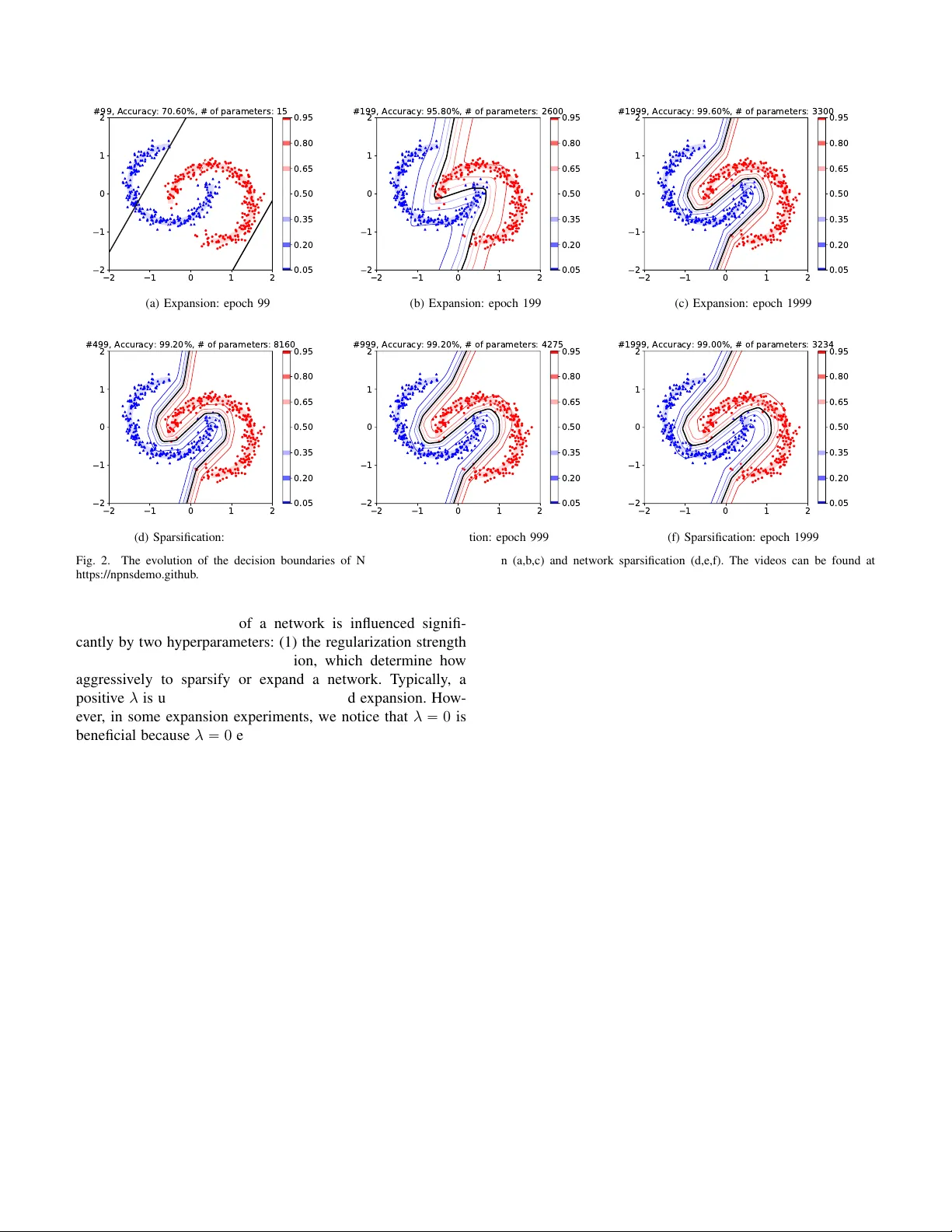
본 논문은 인간 두뇌의 가소성 현상을 모방하여, 딥러닝 모델의 구조를 학습 과정에서 자동으로 축소하거나 확장할 수 있는 새로운 프레임워크인 Neural Plasticity Networks(NPN)를 제안한다. 기존의 네트워크 프루닝(pruning) 연구는 주로 큰 모델을 시작점으로 하여 불필요한 가중치를 제거하는 방식에 초점을 맞추었으며, 반대로 네트워크 확장(network expansion) 연구는 상대적으로 적었다. NPN은 이러한 두 접근을 하나의 통합된 최적화 문제로 재정의한다.
핵심 아이디어는 각 가중치·뉴런·채널 등에 이진 스위치 z 를 부착하고, 이 스위치가 1이면 해당 유닛이 활성, 0이면 비활성화된 상태로 두는 것이다. 스위치의 활성 확률 π 은 로짓 φ 를 통해 파라미터화되며, π = g(φ) 로 정의한다. 여기서 g는 단순 시그모이드가 아니라 스케일 k 에 따라 형태가 변하는 스케일드 시그모이드 gₛₖ(φ)=σ(k·φ) 혹은 중앙‑스케일드 하드 시그모이드 ḡₛₖ(φ)=min(1,max(0,k·φ+0.5)) 로 설정한다. k 값이 클수록 게이트가 급격히 0↔1 전이하여 희소화가 강해지고, k 값이 작을수록 전이가 완만해져 새로운 유닛이 쉽게 활성화되며 네트워크가 확장된다.
목표 함수는 L₀‑norm 정규화 항을 포함한 경험적 위험 최소화 문제이다.
R(θ)= (1/N)∑ₙ L(h(xₙ;θ),yₙ) + λ‖θ‖₀
여기서 ‖θ‖₀는 비제로 파라미터 개수를 정확히 셈으로써 모델 복잡도를 직접 측정한다. θ를 ˜θ와 이진 게이트 z 의 원소별 곱으로 재표현하면, 목표 함수는 z에 대한 기대값 형태가 된다. 그러나 이 기대값은 고차원 이진 변수들의 조합이므로 직접 계산이 불가능하다.
이를 해결하기 위해 저자들은 이전 연구에서 제안한 L₀‑ARM 알고리즘을 차용한다. ARM(Augment‑Reinforce‑Merge) 추정기는 이진 변수의 기대값에 대한 무편향·저분산 그래디언트를 제공한다. 구체적으로, ∇_φ E₍z₎
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기