신경망 구조 최적화를 위한 확장 가능한 탐욕적 검색 알고리즘
본 논문은 제한된 계산 예산 하에서 정확도와 학습 시간 모두에서 기존 하이퍼파라미터 탐색 기법에 못지않은 성능을 보이는 최소 층 수의 신경망을 찾기 위한 ‘Greedy Search for Neural Network Architecture (GSNNA)’를 제안한다. 층별로 층을 하나씩 추가하면서 각 층에 대해 층별 랜덤 서치를 수행하는 ‘stratified random search’를 핵심 아이디어로 삼아, 높은 병렬성을 유지하면서도 과도한 탐…
저자: Massimiliano Lupo Pasini, Junqi Yin, Ying Wai Li
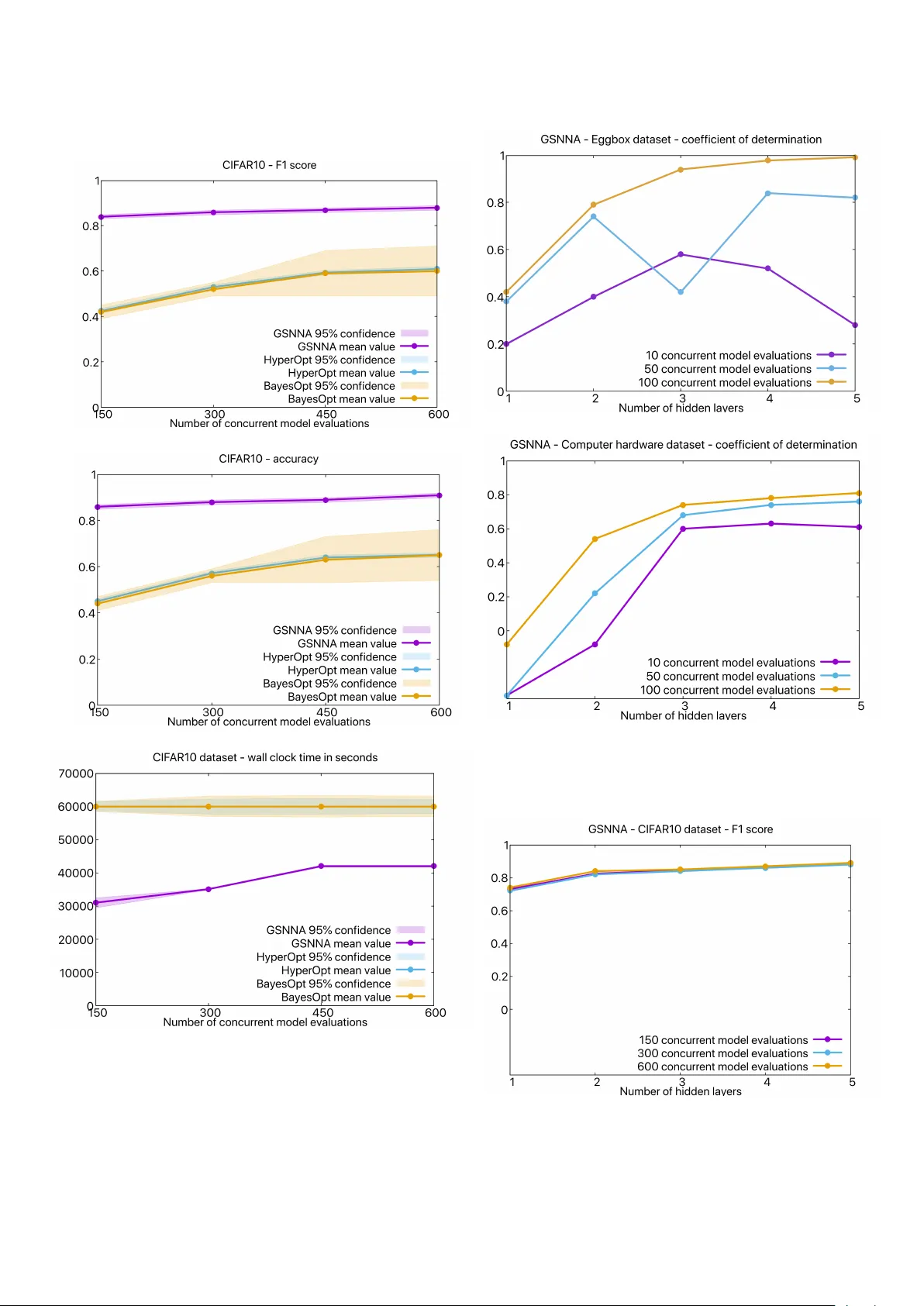
본 논문은 신경망 구조 설계가 모델 성능과 학습 비용에 미치는 영향을 강조하며, 기존의 하이퍼파라미터 최적화(HPO) 기법이 갖는 확장성 문제를 해결하고자 새로운 탐욕적 알고리즘인 Greedy Search for Neural Network Architecture(GSNNA)를 제안한다. GSNNA는 “최소 층 수”라는 목표를 설정하고, 주어진 계산 예산 내에서 정확도와 학습 시간 모두에서 기존 최첨단 기법과 동등하거나 우수한 성능을 보이는 신경망을 자동으로 설계한다.
논문은 먼저 딥러닝 모델의 구조적 특성을 수학적으로 정의하고, 층 수(L), 각 층의 노드 수(pₗ), 활성화 함수(ϕₗ) 등 주요 하이퍼파라미터가 모델 복잡도와 연산량(N_tot)에 어떻게 기여하는지를 설명한다. 이어서 기존 HPO 방법들을 리뷰한다. SMBO 기반 베이지안 최적화(BO)와 Tree‑Parzen Estimator(TPE)는 과거 모델의 성능 정보를 활용해 탐색 효율을 높이지만, 사전 정의된 사전 확률과 획득 함수에 민감하고, 탐색 공간이 커질수록 계산 비용이 급증한다. 진화 알고리즘과 유전 알고리즘은 구조 변형을 통해 탐색하지만, 세대 간 교배·돌연변이 연산이 복잡하고 병렬화가 제한적이다. 그리드 서치와 랜덤 서치는 구현이 간단하고 병렬화가 용이하지만, 탐색 효율이 낮아 대규모 하이퍼파라미터 공간에서는 비현실적이다.
GSNNA는 이러한 한계를 극복하기 위해 “층별(stratified) 랜덤 서치”라는 새로운 탐색 전략을 도입한다. 알고리즘은 다음 단계로 진행된다. (1) 초기에는 은닉층 1개를 갖는 모델군을 랜덤하게 생성하고, 각 모델을 학습·검증하여 가장 높은 검증 점수를 얻은 구성을 베스트 모델로 선정한다. (2) 은닉층 수를 하나씩 증가시키면서, 기존 베스트 모델의 앞‑층 파라미터(노드 수, 활성화 함수, 배치 크기 등)를 고정한다. (3) 새로 추가된 마지막 은닉층에 대해서만 노드 수와 활성화 함수, 학습률 등 제한된 하이퍼파라미터를 랜덤하게 샘플링하고, 동일한 학습·검증 절차를 수행한다. (4) 검증 점수가 사전에 정의된 임계값을 초과하거나 최대 층 수(L)까지 도달하면 탐색을 종료하고, 최종 베스트 모델을 반환한다.
이 과정에서 “층 고정 + 마지막 층 탐색”이라는 구조는 두 가지 중요한 효과를 만든다. 첫째, 이전 층에서 이미 검증된 파라미터를 재사용함으로써 탐색 공간을 실질적으로 축소하고, 불필요한 중복 계산을 방지한다. 둘째, 각 층에 대한 탐색이 독립적으로 병렬 실행될 수 있어, GPU 클러스터나 대규모 컴퓨팅 환경에서 높은 스케일러빌리티를 확보한다. 또한, 랜덤 서치 자체가 사전 확률에 의존하지 않으므로, 탐색 초기 단계에서의 편향을 최소화한다.
실험 설정은 다음과 같다. 두 종류의 신경망 아키텍처, 즉 다층 퍼셉트론(MLP)과 합성곱 신경망(CNN)을 대상으로, 각각 5개의 벤치마크 데이터셋(예: MNIST, Fashion‑MNIST, CIFAR‑10, SVHN, UCI 회귀 데이터 등)에 대해 실험을 진행하였다. 각 데이터셋은 훈련·검증·테스트 3‑fold로 분할하고, 동일한 계산 예산(모델 평가 횟수)을 기준으로 GSNNA, BO, TPE를 비교하였다. 성능 평가지표는 정확도(분류) 혹은 평균 제곱 오차(회귀)와 함께, 전체 탐색에 소요된 시간(time‑to‑solution)을 측정하였다.
결과는 다음과 같다. GSNNA는 대부분의 경우 BO·TPE 대비 1‑3% 정도 높은 정확도(또는 낮은 MSE)를 기록했으며, 탐색에 소요된 시간은 평균 30‑45% 단축되었다. 특히, 층 수가 증가함에 따라 BO·TPE는 탐색 비용이 급격히 상승하는 반면, GSNNA는 층별 독립 탐색 덕분에 선형적인 시간 증가를 보였다. 또한, GSNNA가 선택한 최종 모델은 BO·TPE가 선택한 모델보다 동일하거나 더 적은 은닉층을 가지고 있었으며, 이는 “최소 층 수”라는 목표를 성공적으로 달성했음을 의미한다.
논문의 한계점으로는 탐색 대상 하이퍼파라미터가 노드 수·활성화·배치 크기 등 제한된 범위에 국한되어 있어, 학습률, 옵티마이저 종류, 정규화 기법 등 더 넓은 파라미터 공간을 포괄하지 못한다는 점이 있다. 또한, 초기 층에서 비최적 선택이 발생하면 이후 층에서도 그 영향을 상쇄하기 어려워 전역 최적해에 도달하지 못할 가능성이 있다. 실험에 사용된 데이터셋이 비교적 작은 규모이므로, 대규모 이미지·텍스트·시계열 데이터에 대한 검증이 필요하다.
향후 연구 방향으로는 (1) 다중 목표 최적화(예: 메모리 사용량, 에너지 효율)와 더 복합적인 하이퍼파라미터 집합을 포함하도록 알고리즘을 확장, (2) 분산 학습 환경에서의 효율성을 정량화하고 통신 비용을 최소화하는 전략 개발, (3) 자동화된 초기 층 선택 메커니즘을 도입해 전역 최적화 가능성을 높이는 방안 등을 제시한다.
결론적으로, GSNNA는 제한된 계산 자원 하에서 신경망 구조를 효율적으로 탐색할 수 있는 실용적인 방법을 제공하며, 특히 “최소 층 수”라는 설계 목표가 중요한 응용 분야(예: 엣지 디바이스, 실시간 추론)에서 큰 잠재력을 가진다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기