셰익스피어 시대 연극 초연 연도 예측을 위한 회귀 모델
초록
본 연구는 1585‑1610년 사이에 초연된 181편의 셰익스피어 시대 연극을 대상으로, 단어 출현 확률을 특징으로 11가지 회귀 기법을 적용해 초연 연도를 예측한다. 특히, 메메틱 알고리즘 기반의 Continued Fraction Regression(CFR)을 도입해 적은 변수로도 해석 가능한 모델을 구축하고, 빈번히 등장하는 20개 단어가 연대와 장르에 미치는 영향을 분석하였다.
상세 분석
이 논문은 초기 연극 기록이 부재한 셰익스피어 시대의 작품들을 연대 순서대로 배치하는 문제에 통계적 접근을 시도한다. 285편의 원문을 수집한 뒤, 1585‑1610년 사이에 초연된 181편을 분석 대상으로 선정하였다. 텍스트는 VARD 소프트웨어를 이용해 현대식 철자를 일관되게 정규화하고, TEI XML 태그로 대사와 비대사를 구분하였다. 특히, ‘that’과 같은 동형이의어를 품사별로 태깅해 48개의 별도 형태로 분류함으로써 어휘 빈도 측정의 정확성을 높였다.
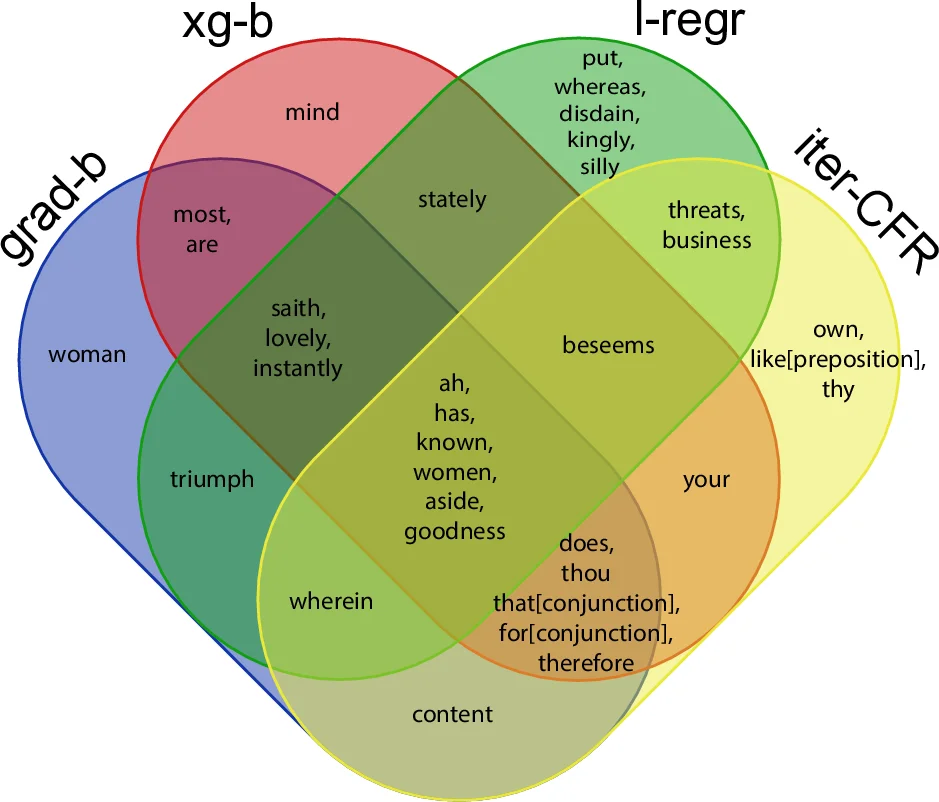
특징 선택 단계에서는 전체 51 183개의 어휘를 그대로 사용했으며, ‘불용어’를 제거하지 않아 흔히 간과되는 고빈도 기능어도 모델에 포함시켰다. NP‑complete인 최소 k‑특징 선택 문제를 해결하기 위해 두 가지 휴리스틱을 적용하였다. 첫 번째는 라소(Lasso) 회귀로, L1 정규화를 통해 100번의 부트스트랩 실험에서 90 % 이상 등장한 14개의 단어(‘and’, ‘a’, ‘you’ 등)를 선별했다. 라소는 선형 관계를 가정하지만, 변수 수를 크게 줄여 과적합을 방지한다는 장점이 있다.
두 번째는 메메틱 알고리즘을 이용한 Continued Fraction Regression(CFR)이다. CFR은 다변량 비선형 회귀를 연속분수 형태로 표현하고, 전역 탐색(유전 알고리즘)과 지역 탐색(그리디 개선)으로 최적 해에 근접한다. 논문은 100번의 독립 실행을 통해 평균 20개 이하의 변수만을 사용해 높은 예측 정확도를 달성했으며, 선택된 단어들의 의미적 해석이 가능하도록 설계되었다.
성능 평가는 80 % 훈련 / 20 % 테스트 분할과 leave‑one‑out 교차검증을 병행했으며, 평균 절대 오차(MAE)와 결정계수(R²)로 비교하였다. 라소와 CFR 모두 전통적인 선형 회귀, 릿지, 서포트 벡터 회귀 등 9가지 대조 모델을 능가했으며, 특히 CFR은 변수 수가 적음에도 불구하고 R² ≈ 0.78 수준을 기록했다.
단어 중요도 분석에서는 ‘thou’, ‘thy’, ‘sir’ 등 시대적 언어 특징을 반영하는 단어가 초연 연도와 강한 상관관계를 보였고, 장르별(비극, 코미디, 역사극) 빈도 차이도 드러났다. 이는 언어 변화가 단순 연대 추정뿐 아니라 장르 구분에도 활용될 수 있음을 시사한다.
한계점으로는 철자 정규화 과정에서 의미 손실 가능성, 샘플 수가 특정 연도 구간에 편중된 점, 그리고 외부 메타데이터(공연 기록, 출판 연도 등)와의 통합이 부족한 점을 들 수 있다. 향후 연구에서는 더 넓은 시계열 데이터와 다중모달 특징(음악, 무대 지시 등)을 결합해 모델의 일반화 능력을 강화할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기