CSV 기반 가상 OBDA 성능 향상 MorphCSV
초록
MorphCSV는 CSV·Excel 등 표형 데이터에 대한 가상 온톨로지 기반 데이터 접근(OBDA) 시, 매핑·쿼리 정보에서 추출한 제약조건을 자동으로 적용해 스키마를 정규화하고 인덱스를 생성함으로써 SPARQL‑to‑SQL 변환의 완전성과 실행 속도를 크게 개선한다.
상세 분석
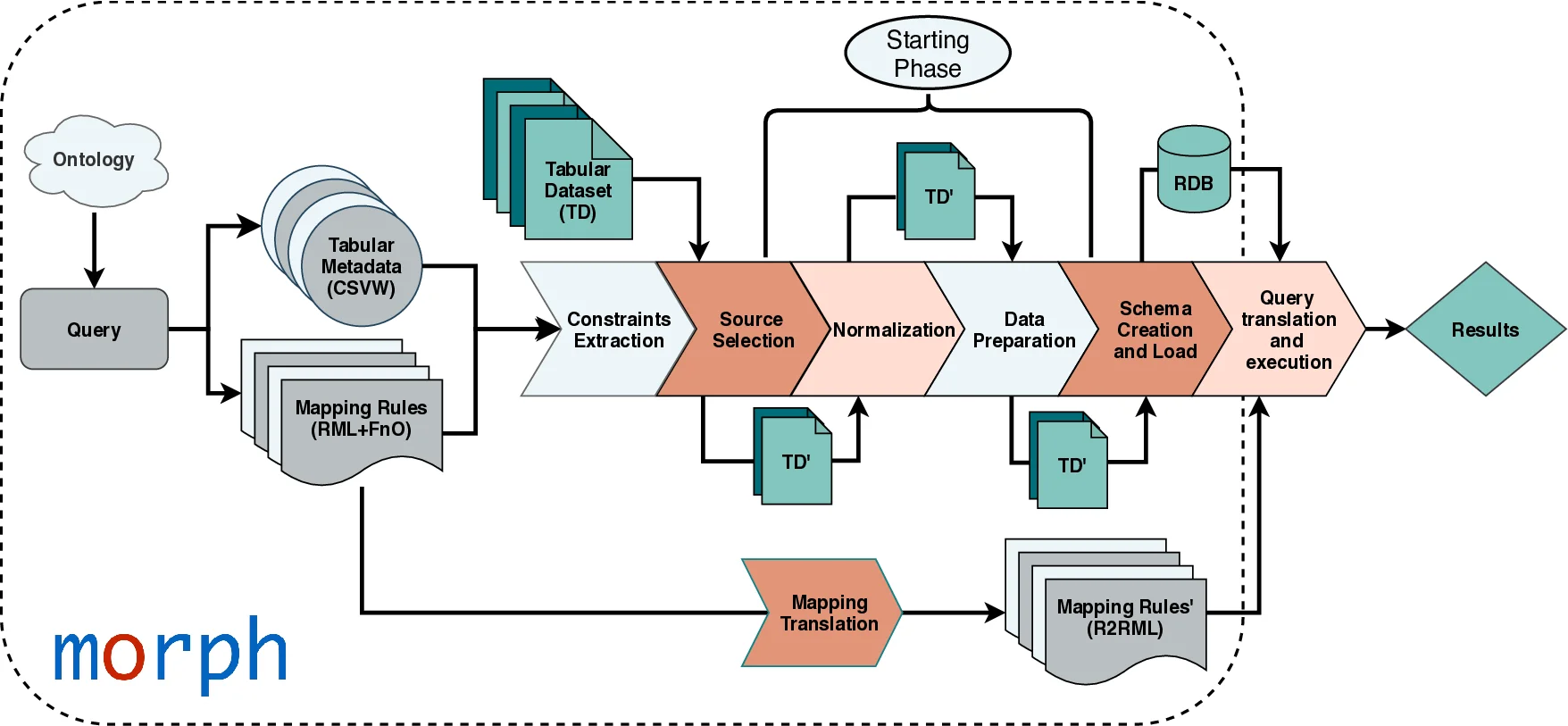
본 논문은 표형 데이터가 OBDA 환경에서 차지하는 비중이 급증하고 있음에도 불구하고, 기존 가상 OBDA 엔진이 전제하는 기본적인 관계 제약(기본키·외래키·데이터 타입·인덱스 등)이 CSV·Excel 파일에는 명시적으로 존재하지 않아 쿼리 변환 단계에서 성능 저하와 결과 누락이 발생한다는 문제점을 정확히 짚어낸다. 이를 해결하기 위해 저자들은 “가상 표형 데이터셋(VTD)”이라는 개념을 도입하고, VTD와 SPARQL 쿼리를 입력으로 받아 제약조건을 자동 생성·적용하는 MorphCSV 프레임워크를 설계하였다. MorphCSV는 크게 네 단계로 구성된다. 첫째, CSVW·RML 등 메타데이터 어노테이션과 매핑 파일을 분석해 고유 식별자, 외래키, 데이터 타입, 다중값 셀의 정규화 규칙 등을 추출한다. 둘째, 쿼리에서 실제로 사용되는 소스와 속성을 식별해 불필요한 컬럼 로딩을 최소화한다. 셋째, 추출된 제약조건을 기반으로 데이터 전처리를 수행한다. 여기에는 다중값 셀을 별도 행으로 분해하는 정규화, 날짜·숫자 형식 통일, 중복 레코드 제거 등이 포함된다. 넷째, 정규화된 데이터를 관계형 데이터베이스에 적재하면서 자동으로 기본키·외래키 제약과 인덱스를 생성한다. 이렇게 구축된 물리 스키마는 기존 SPARQL‑to‑SQL 엔진이 기대하는 “잘 설계된” 관계형 모델과 일치하므로, 엔진 내부의 비용 기반 옵티마이저가 인덱스 활용·조인 순서 최적화를 정상적으로 수행한다.
실험에서는 두 대표적인 오픈소스 OBDA 엔진인 Morph‑RDB와 Ontop에 MorphCSV를 적용하였다. BSBM 전자상거래 벤치마크, GTFS‑Madrid 교통 데이터셋, Bio2RDF 생물학 데이터셋 등 세 도메인에서 30여 개 SPARQL 쿼리를 실행했으며, 평균 응답 시간이 10배~100배까지 단축되는 동시에 기존 엔진이 놓쳤던 결과(특히 다중값 셀 정규화가 필요한 경우)가 모두 복원되는 것을 확인했다. 특히 GTFS 사례에서는 정규화 전후의 조인 비용 차이가 크게 나타났으며, 인덱스 부재로 인한 풀 스캔이 인덱스 기반 탐색으로 전환되어 성능이 급격히 개선되었다.
핵심 기여는 (1) 표형 데이터에 대한 제약조건 추출·적용 메커니즘을 체계화한 점, (2) 기존 OBDA 파이프라인에 비침투적으로 삽입 가능한 엔진 독립적 설계, (3) 실험을 통해 제약조건 적용이 쿼리 완전성과 실행 효율 모두에 긍정적 영향을 미침을 실증한 점이다. 논문은 또한 CSVW·RML 표준이 아직 제약조건 표현에 충분히 활용되지 못하고 있음을 지적하고, 향후 메타데이터 표준 강화와 자동화된 스키마 진화 관리 방안에 대한 연구 방향을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기