에지 AI를 위한 자원 제한 훈련(RCT) – 동적 비트폭 조정으로 메모리·에너지 절감
초록
본 논문은 에지 디바이스에서 양자화 모델을 학습할 때 발생하는 메모리·에너지 문제를 해결하기 위해, 양자화된 파라미터만을 유지하면서 레이어별 비트폭을 동적으로 조정하는 Resource Constrained Training(RCT) 방식을 제안한다. Gavg 지표를 이용해 양자화 언더플로우 빈도를 측정하고, 필요 시 비트폭을 늘려 학습 효율을 유지한다. 실험 결과, GEMM 연산 에너지 86 %와 파라미터 메모리 46 %를 절감하면서 정확도 저하를 최소화한다.
상세 분석
이 논문은 에지 AI 환경에서 양자화 모델을 직접 학습하는 것이 기존의 Quantisation‑Aware Training(QAT) 방식과 비교해 메모리와 에너지 측면에서 비효율적이라는 점을 명확히 지적한다. QAT는 학습 과정에서 FP32와 양자화 모델 두 개의 파라미터 복사본을 유지해야 하며, 이는 오프‑칩 DRAM과 온‑칩 캐시 사이의 빈번한 데이터 이동을 초래한다. 특히 배터리 구동 디바이스에서는 이러한 이동이 에너지 소모를 크게 늘린다.
RCT는 “양자화된 모델만 유지”한다는 근본적인 설계 철학을 채택한다. 이를 위해 레이어별 비트폭을 동적으로 조정하는 히스토리컬 메트릭인 Gavg를 도입한다. Gavg는 해당 레이어의 그래디언트 평균 크기를 최소 양자화 해상도(Δ)와 비교해 정의되며, 값이 0에 가까울수록 언더플로우가 빈번해 파라미터가 업데이트되지 않음을 의미한다. 알고리즘 1은 Gavg가 사전에 정의된 하한(T_min)보다 작으면 비트폭을 1비트씩 증가시키고, 상한(T_max)보다 크면 감소시키는 간단한 정책을 제시한다.
실제 학습 흐름은 알고리즘 2에 요약된다. 초기에는 낮은 비트폭(예: 8비트)으로 시작하고, 일정 간격(INTERVAL)마다 Gavg를 계산해 비트폭을 조정한다. 이 과정은 매 배치가 아니라 에포크당 몇 번만 수행해도 충분히 레이어별 학습 상태를 반영한다. 결과적으로 초기에는 메모리와 연산 에너지를 크게 절감하면서도, 학습이 진행됨에 따라 언더플로우가 심해지는 레이어에만 비트폭을 늘려 정확도 손실을 방지한다.
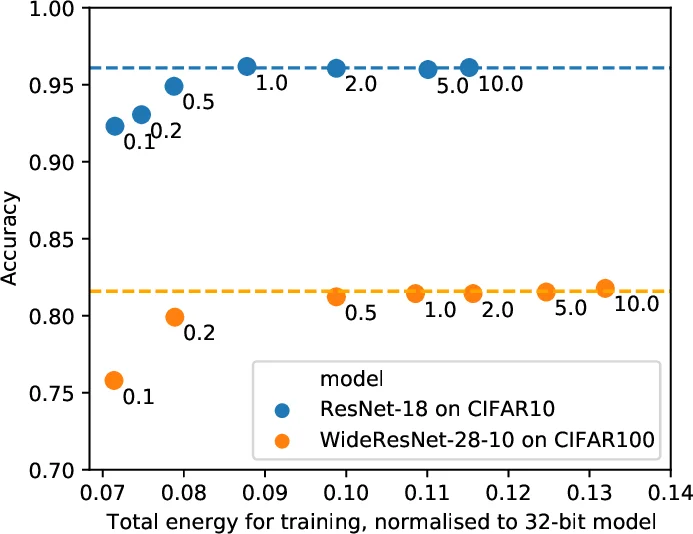
실험에서는 CIFAR‑10/100, SVHN, ImageNet 등 이미지 분류와 NLP 태스크에 대해 ResNet‑20/110, MobileNetV2, WideResNet‑28‑10 등 다양한 모델을 적용했다. 에너지 추정은 GEMM 연산을 32‑bit 기준으로 비례적으로 스케일링했으며, 16‑bit 연산이 32‑bit 대비 25 % 에너지 절감된다는 기존 연구를 근거로 했다. 결과는 RCT가 QAT 대비 모델 파라미터 메모리를 46 % 이상, GEMM 연산 에너지를 86 % 이상 절감하면서도 최종 정확도는 베이스라인(비양자화 FP32)과 1‑2 % 이내 차이로 유지함을 보여준다. 특히 QAT와 비교했을 때 파라미터 이동 에너지의 절반 이상을 추가 절감한다는 점이 눈에 띈다.
또한, 비트폭 변화를 시각화한 Figure 3은 학습 초기에 일부 레이어가 2‑4비트로 동작하다가 점차 8‑12비트 수준으로 상승하는 모습을 보여준다. 이는 Gavg 기반 조정이 레이어별 학습 난이도와 연관된 양자화 해상도를 자동으로 탐색함을 의미한다. 논문은 이러한 동적 비트폭 탐색이 일종의 경량화된 Neural Architecture Search( NAS) 역할을 수행한다는 점을 강조한다.
한계점으로는 현재 Gavg가 그래디언트 크기와 최소 해상도만을 고려해 단순히 비트폭을 조정한다는 점이다. 학습률, 모멘텀, 옵티마이저 특성 등 다른 요인을 통합하면 더 정교한 조정이 가능할 것으로 보인다. 또한 에너지 모델이 하드웨어‑독립적인 근사치에 의존하고 있어 실제 에지 디바이스에서의 절감 효과는 추가 검증이 필요하다.
전반적으로 RCT는 에지 디바이스에서 양자화 모델을 효율적으로 학습하기 위한 실용적인 프레임워크이며, 메모리·에너지 제약이 심한 환경에서도 적절한 정확도를 유지할 수 있는 방법론을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기