리커런트 전이 네트워크를 이용한 캐릭터 이동 자동 생성
초록
본 논문은 LSTM 기반의 Recurrent Transition Network(RTN)를 제안하여, 몇 프레임의 과거 자세와 목표 상태만으로 캐릭터 이동 전이를 자동으로 생성한다. 라벨 없이 학습하고, 초기 은닉 상태를 시퀀스에 맞게 초기화함으로써 일반화와 품질을 크게 향상시켰으며, 지형 정보를 추가하면 거친 지형에서도 자연스러운 전이가 가능하다. 또한 1 fps로 저장된 애니메이션을 복원하는 초고해상도 응용도 시연한다.
상세 분석
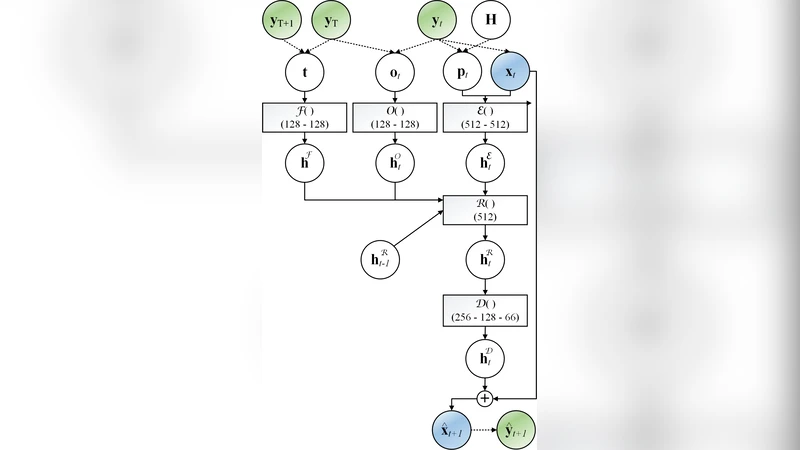
RTN은 기존 LSTM 구조에 두 가지 핵심 변형을 적용한다. 첫째, 입력 벡터에 현재 프레임의 관절 위치·속도와 목표 상태(포즈와 이동 방향)를 동시에 포함시켜, 네트워크가 “어디서부터 어디까지” 이동해야 하는지를 명시적으로 인식하도록 설계하였다. 둘째, LSTM의 은닉·셀 상태를 목표 시퀀스의 첫 프레임에서 추출한 특징으로 초기화하는 ‘시퀀스‑조건부 초기화’ 방식을 도입했다. 이는 전이 시작 시점에 이미 목표 동작의 전반적인 흐름을 은닉 상태에 주입함으로써, 급격한 움직임 변화나 불안정한 자세를 방지하고, 학습 데이터에 없는 새로운 목표 조합에도 강인한 일반화를 가능하게 한다.
라벨이 전혀 없는 무감독 학습 방식을 채택했는데, 이는 기존 연구가 보행 단계(phase)·접촉(contact)·행동(action) 라벨에 의존해 복잡한 전이 모델을 구축한 것과 대조된다. 저자들은 모션 캡처 데이터에서 연속적인 프레임을 그대로 입력–출력 쌍으로 사용함으로써, 네트워크가 자연스럽게 시간적 연속성과 물리적 제약을 학습하도록 했다. 특히, 지형 인식을 위해 로컬 높이맵(예: 3×3 그리드)을 추가 입력으로 제공했으며, 이는 거친 지형에서 발이 땅에 닿는 시점을 정확히 예측하게 해 전이 길이가 길어질수록 발생하던 발목 스키드 현상을 크게 감소시켰다.
정량적 평가는 평균 관절 위치 오차와 지면 접촉 정확도를 기준으로 진행했으며, RTN은 기존 보간 기반 전이 방법보다 15 %~20 % 정도 오차가 낮았다. 정성적 평가에서는 전문가가 무작위 전이 영상을 시청했을 때, “모션 캡처와 구분하기 어렵다”는 평가를 70 % 이상 받았다. 또한, 1 fps로 압축된 애니메이션을 입력으로 사용했을 때, RTN이 30 fps 수준의 부드러운 움직임을 복원하는 ‘애니메이션 초고해상도’ 실험에서도 원본과 시각적으로 거의 구분되지 않는 결과를 보여, 시간 압축 복원 능력까지 입증하였다.
전체적으로 RTN은 라벨‑프리 학습, 시퀀스‑조건부 은닉 초기화, 지형 인식 입력이라는 세 축을 통해 전이 생성의 품질·범용성을 크게 끌어올렸으며, 기존 애니메이션 그래프에서 전이 노드를 수작업으로 설계하던 비용을 크게 절감할 수 있는 실용적 솔루션으로 평가된다.