딥러닝 보안·프라이버시 종합 가이드
초록
본 논문은 딥러닝 모델이 직면한 보안 위협(중독·회피 공격)과 데이터 프라이버시 침해(모델 역추정·서비스 제공자 악용)를 체계적으로 분류하고, 각 위협에 대응하는 최신 방어 기법(그라디언트 마스킹, 견고성 강화, 이상 탐지, 인증, 차분 프라이버시, 동형암호, 안전한 다자간 연산 등)을 정리한다. 또한 공격·방어 기법의 구현 난이도와 실용적 한계를 논의하며, 향후 연구 방향을 제시한다.
상세 분석
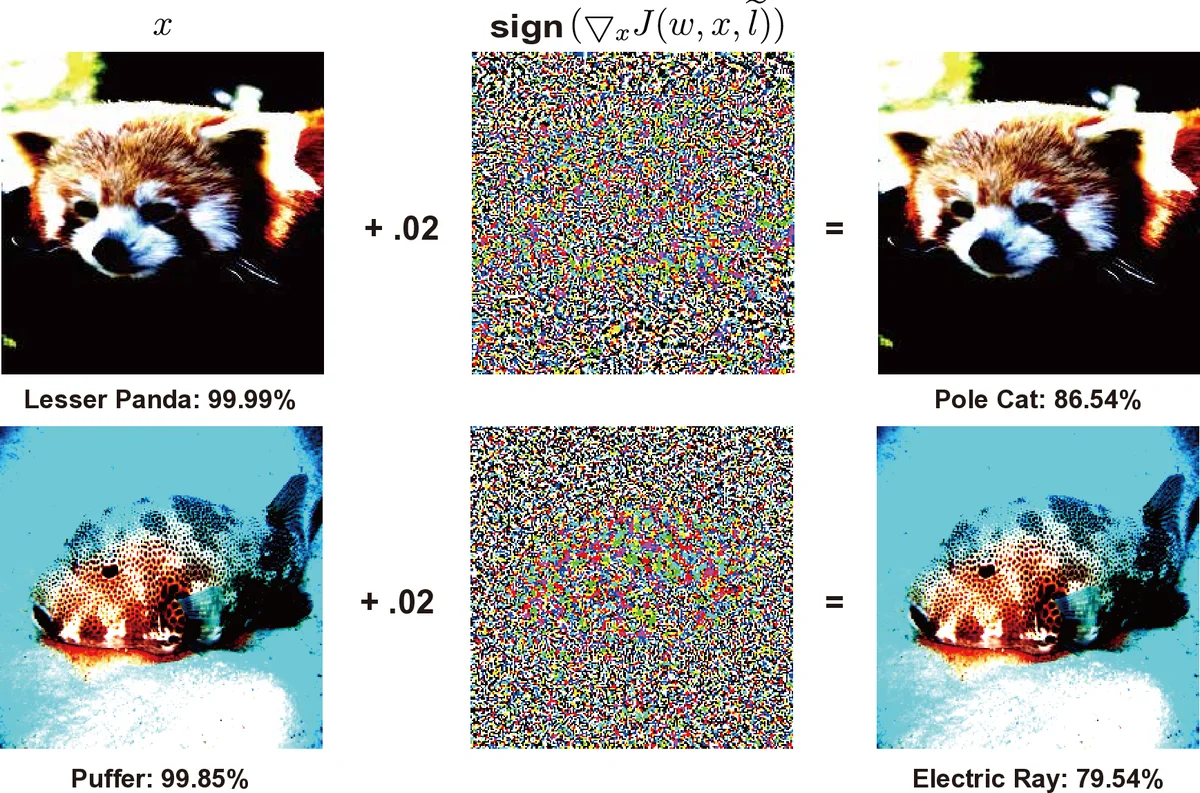
이 논문은 딥러닝 보안·프라이버시 분야를 ‘Secure AI’라는 개념 아래 통합적으로 조망한다. 먼저 공격을 ‘학습 단계(poisoning)’와 ‘추론 단계(evasion)’로 구분하고, 각각을 화이트박스·블랙박스 접근법에 따라 세분화한다. Poisoning 공격은 성능 저하, 목표 중독, 백도어 세 가지 서브클래스로 나뉘며, 특히 백도어 공격은 트리거 패턴을 삽입해 특정 입력에만 악의적 동작을 수행한다는 점에서 실용적 위험이 크다. Evasion 공격은 FGSM, PGD, CW, Universal Perturbation 등 다양한 노름(L0, L1, L2, L∞) 기반 기법을 포함하고, 최근에는 GAN 기반의 자연스러운 적대 예제와 공간 변환 공격이 등장해 기존 방어를 회피한다.
방어 측면에서는 크게 두 축으로 나뉜다. ① 공격 특성을 이용한 경험적 방어: 그라디언트 마스킹, 모델 견고성 강화(Adversarial Training, Randomized Smoothing), 이상 탐지(통계적 검증, 입력 변형 기반 탐지) 등; ② 형식적 보증 기반 방어: 인증(certification) 기법(라디컬 보증, 라플라시안 기반 경계 증명)과 같은 수학적 증명 방법이다. 경험적 방어는 최신 공격에 빠르게 대응 가능하지만, ‘gradient masking’과 같은 회피 가능성이 존재한다. 반면 인증 기반 방어는 이론적 안전성을 제공하지만 계산 비용이 높고, 적용 가능한 모델 구조가 제한적이다.
프라이버시 보호에서는 모델 역추정(model inversion), 멤버십 추론(member inference) 등을 통한 학습 데이터 유출 위험을 강조한다. 차분 프라이버시(DP) 적용은 학습 과정에 노이즈를 삽입해 개인 정보를 보호하지만, 노이즈 규모가 커질수록 모델 정확도가 급격히 저하되는 트레이드오프가 있다. 동형암호(Homomorphic Encryption)와 안전한 다자간 연산(Secure Multi‑Party Computation, MPC)은 데이터 자체를 암호화한 채 연산을 수행함으로써 완전한 기밀성을 제공한다. 그러나 현재는 연산 오버헤드가 수십 배에 달해 실시간 서비스에 적용하기 어렵고, 메모리 요구량과 네트워크 대역폭 문제도 존재한다.
논문은 또한 공격·방어 연구가 ‘화이트박스 ↔ 블랙박스’ 경계에서 상호 진화하고 있음을 지적한다. 공격자는 서브스티튜트 모델, 제로‑지식 추정 등을 활용해 블랙박스 환경에서도 높은 성공률을 보이며, 방어자는 이러한 추정에 강인한 메타‑학습 기반 방어와 모델 무작위화를 제안한다.
마지막으로 저자는 향후 연구 과제로 (1) 경량화된 암호학적 프로토콜의 실시간 적용, (2) 인증 기반 방어와 차분 프라이버시를 통합한 하이브리드 프레임워크, (3) 백도어 탐지를 위한 데이터 흐름 분석 및 원인 추적 메커니즘, (4) 표준화된 보안·프라이버시 평가 벤치마크 구축을 제시한다. 이러한 방향은 현재 딥러닝이 의료·자율주행·클라우드 AI 서비스 등 고위험 분야에 확대 적용되는 상황에서 필수적인 로드맵이라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기