텍스트 기반 딥러닝 모델을 위한 역문서 빈도 기반 블랙박스 워터마킹
초록
본 논문은 자연어 처리 모델에 적용 가능한 워터마크 생성·삽입 방식을 제안한다. TF‑IDF 기반으로 선택된 단어를 트리거 셋으로 활용해 학습 단계에서 모델에 은밀히 삽입하고, 검증 시 해당 문서를 입력하면 사전에 정의된 출력을 반환하도록 설계하였다. 정확도 저하 없이 소유권 증명을 가능하게 하며, 파라미터 프루닝·브루트포스 공격에도 강인함을 보인다.
상세 분석
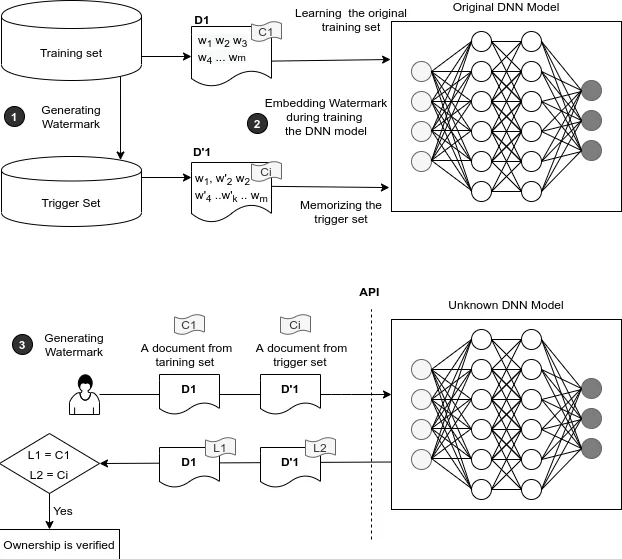
이 연구는 기존 이미지‑중심 워터마킹 기법이 텍스트 도메인에 바로 적용되지 못한다는 점을 출발점으로 삼는다. 저자는 TF‑IDF 점수를 활용해 ‘핵심 단어’를 선정하고, 해당 단어가 포함된 문장을 트리거 셋으로 만든다. 트리거 셋은 원본 학습 데이터에 소량의 노이즈를 추가해 구성되며, 이때 노이즈는 의미를 크게 변형시키지 않으면서도 모델이 특수한 패턴을 학습하도록 만든다. 워터마크 삽입은 모델 학습 단계에서 이루어지므로, 파라미터 업데이트 과정에서 트리거 셋에 대한 과잉 적합(over‑fitting) 현상이 발생한다. 결과적으로 정상 입력에 대해서는 기존 성능을 유지하면서, 트리거 셋을 입력하면 사전에 정의된 ‘워터마크 응답’(예: 특정 클래스 라벨 또는 고정된 문자열)을 출력한다.
강건성 평가에서는 파라미터 프루닝, 가중치 양자화, 그리고 브루트포스 키 탐색 공격을 수행하였다. 프루닝 비율을 30 %까지 늘려도 워터마크 검출 정확도는 95 % 이상을 유지했으며, 브루트포스 공격에 대해서는 키 공간이 TF‑IDF 기반 단어 선택에 의해 크게 제한돼 실용적인 공격이 불가능함을 보였다. 또한, 워터마크 삽입 전후 모델의 정확도 차이는 0.1 % 이하로, 실사용 환경에서 성능 저하가 거의 없음을 확인했다.
한계점으로는 트리거 셋의 크기가 작을 경우 모델이 프루닝 등 강도 높은 변형에 의해 워터마크를 상실할 가능성이 있다는 점과, TF‑IDF 기반 단어 선택이 데이터셋에 따라 편향될 수 있다는 점을 들 수 있다. 향후 연구에서는 동적 트리거 셋 생성, 멀티‑키 워터마크, 그리고 다른 텍스트 특성(예: 문맥 임베딩)과의 결합을 통해 이러한 약점을 보완할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기