과학용 저전력 머신러닝 가속기, hls4ml 오픈소스 코디자인 워크플로우
초록
hls4ml은 머신러닝 모델을 FPGA·ASIC에 최적화된 하드웨어 구현으로 자동 변환해 주는 오픈소스 코디자인 툴킷이다. 최신 버전은 파이썬 API, 양자화 인식 가지치기, 엔드‑투‑엔드 FPGA 흐름, 저전력 장기 파이프라인 커널, ASIC 백엔드 등을 추가해 저전력·저지연 요구를 만족한다. 이를 통해 분야 과학자들이 복잡한 하드웨어 설계 지식 없이도 에너지 효율적인 엣지 인퍼런스를 구현할 수 있다.
상세 분석
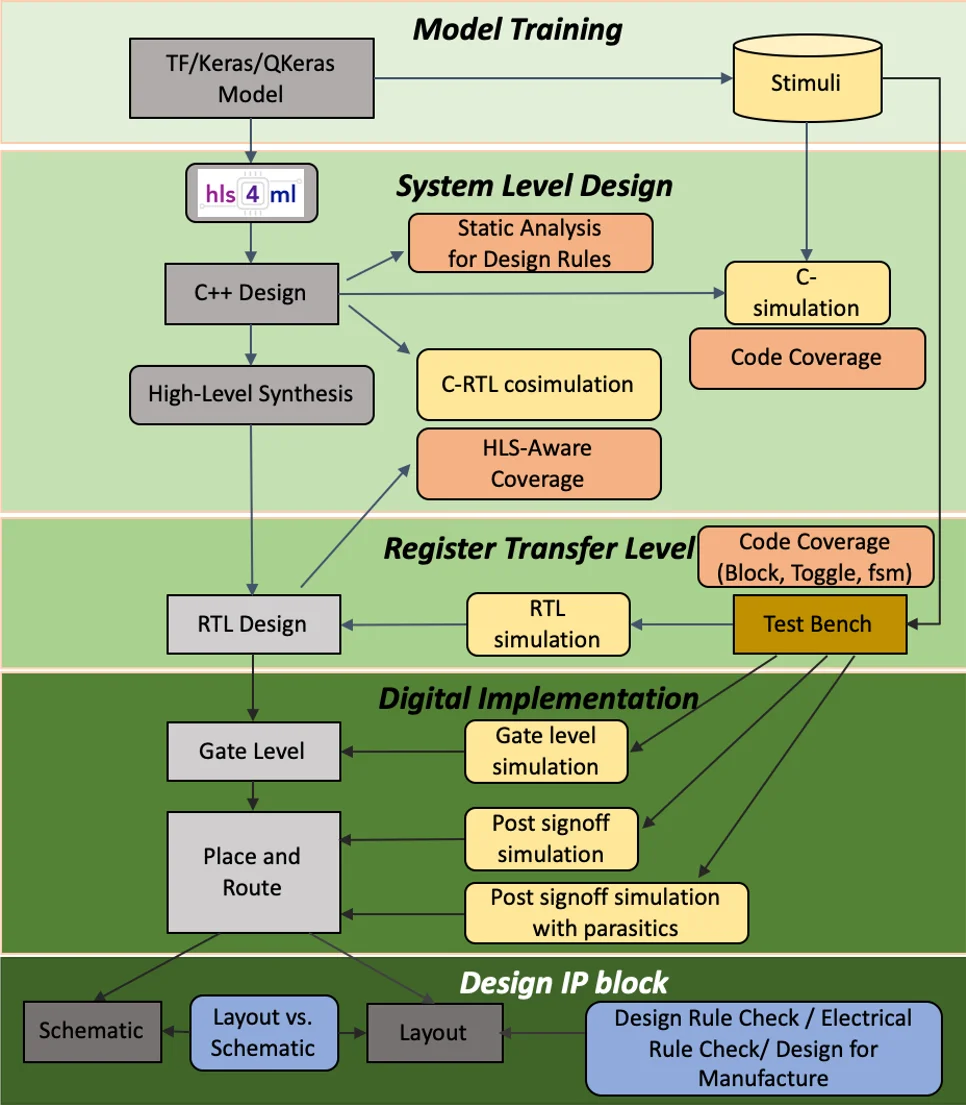
hls4ml은 기존의 고수준 합성(HLS) 기반 설계 흐름을 머신러닝 프레임워크(Keras, PyTorch, ONNX 등)와 긴밀히 연결한다. 모델 변환 단계에서 각 레이어와 활성화 함수를 독립적인 HLS 모듈로 매핑하고, 사용자가 지정한 정밀도와 병렬도(parallelism)를 기반으로 파이프라인 지연(latency)과 자원 사용량을 자동 조정한다. 특히 양자화 인식 훈련(QAT)과 양자화 인식 가지치기(QAP)를 지원함으로써, 가중치와 활성값을 1~8비트 수준으로 압축하면서도 정확도 손실을 최소화한다. 저전력 구현을 위한 핵심 기법으로는 ‘long‑pipeline kernels’가 있다. 이는 연산을 여러 클럭 사이클에 걸쳐 분산시켜 전력 피크를 낮추고, 동시에 레지스터와 DSP 사용을 최적화한다. 또한, 희소 연산(sparse operation) 지원을 통해 0값 가중치를 자동으로 스킵함으로써 불필요한 곱셈을 제거한다.
백엔드 측면에서는 Xilinx Vitis HLS, Intel Quartus HLS, Mentor Catapult 등 다중 HLS 컴파일러를 래핑하고, ASIC 흐름을 위한 RTL 변환 파이프라인도 제공한다. ASIC 전용 흐름은 전력·면적(PPA) 최적화를 위해 고정된 비트폭과 구조화된 파이프라인을 적용한다. hls4ml은 설계자에게 ‘resource‑aware’ 파라미터(예: DSP, BRAM, LUT 사용량)와 전력 추정치를 실시간으로 제공해, 설계 반복 주기를 크게 단축한다.
또한, hls4ml은 모델 압축 단계에서 배치 정규화(BatchNorm)와 같은 레이어를 전이(convolution) 레이어와 결합(fuse)하거나, 이진·삼진(tanh) 활성화와 결합해 연산량을 감소시킨다. 이러한 최적화는 HLS 수준에서 자동으로 적용되며, 사용자는 YAML 혹은 파이썬 딕셔너리 형태의 설정 파일만 수정하면 된다.
전체적으로 hls4ml은 ‘코드‑하드웨어’ 간의 경계를 낮추어, 과학 실험 장비, 웨어러블 센서, 무선 네트워크 등 다양한 저전력 엣지 시나리오에 맞는 맞춤형 ML 가속기를 빠르게 프로토타이핑하고 배포할 수 있게 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기