대규모 인‑와일드 비디오 품질 데이터셋 KonVid‑150k와 효율적 딥러닝 평가 모델
본 논문은 자연 환경에서 촬영·업로드된 15만 개 이상의 비디오를 포함한 KonVid‑150k 데이터셋을 공개하고, 다중 레벨 공간 풀링(MLSP) 특징을 이용한 경량 VQA 모델(MLSP‑VQA)을 제안한다. 제안 모델은 KoNVid‑1k에서 SRCC 0.82를 달성하며, 다른 인‑와일드 데이터베이스에 대한 교차 테스트에서도 기존 최고 성능을 넘어선다.
저자: Franz G"otz-Hahn, Vlad Hosu, Hanhe Lin
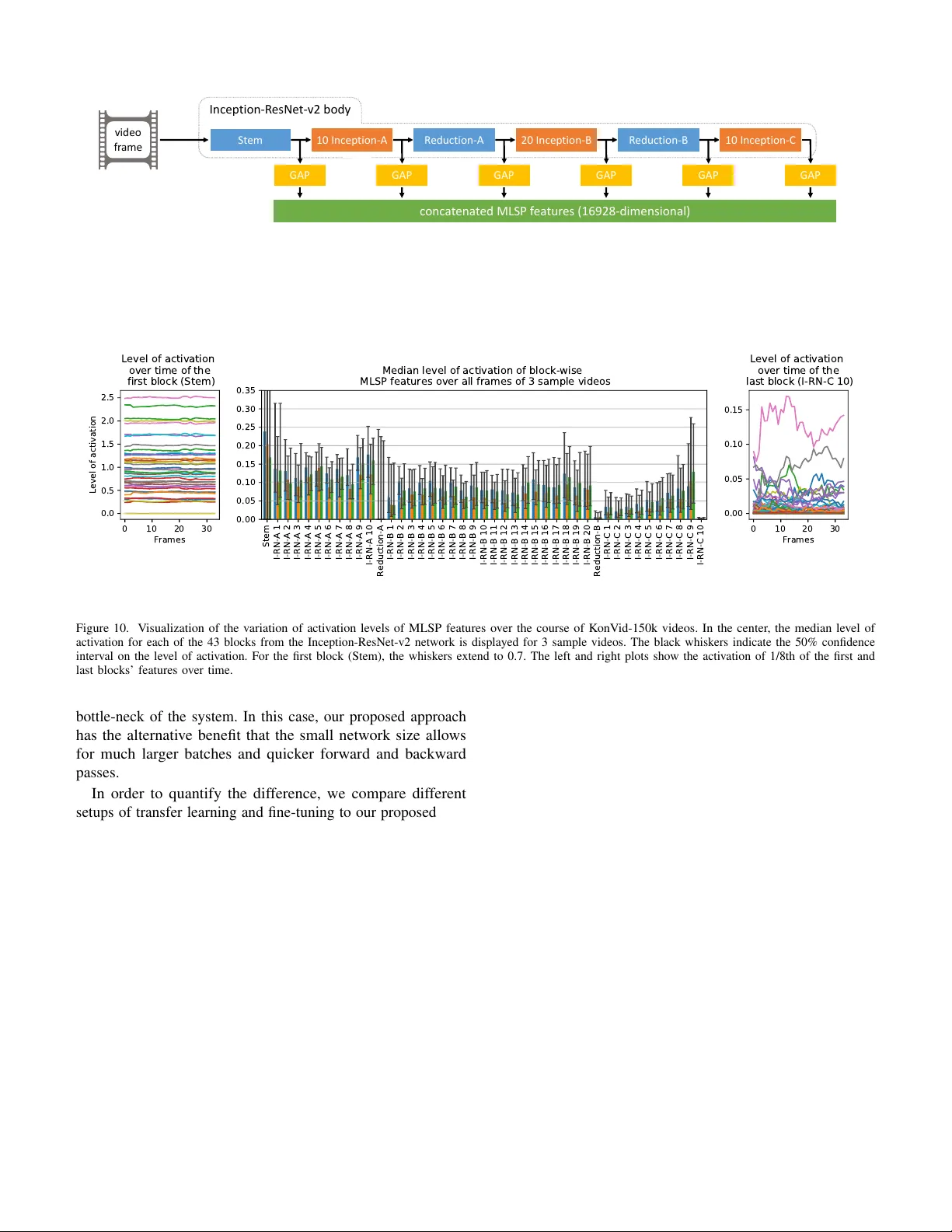
본 논문은 “No‑Reference Video Quality Assessment (NR‑VQA)” 분야에서 두 가지 근본적인 한계를 극복하고자 한다. 첫 번째는 기존 데이터베이스가 인위적으로 만든 왜곡에 국한돼 실제 인터넷 환경에서 발생하는 복합적인 품질 저하를 충분히 반영하지 못한다는 점이며, 두 번째는 딥러닝 기반 모델이 학습에 필요한 대규모 고품질 라벨이 부족해 성능이 제한된다는 점이다. 이를 해결하기 위해 저자들은 크게 세 가지 공헌을 제시한다.
1. **KonVid‑150k 데이터베이스 구축**
- **구성**: 전체 153,841개의 5초 길이 비디오(A 서브셋)와 1,596개의 고정밀 비디오(B 서브셋)으로 구성. A 서브셋은 각 비디오당 5개의 MOS를, B 서브셋은 최소 89개의 MOS를 제공한다.
- **수집·전처리**: YouTube, Vimeo, Flickr 등 공개 플랫폼에서 원본 파일을 다운로드하고, 파일 크기를 제한하기 위해 고품질 재인코딩을 수행하면서 인코딩 아티팩트를 최소화했다.
- **주관식 평가**: 크라우드소싱을 활용했으며, 초기 퀴즈와 삽입형 검증 질문을 통해 라벨 품질을 보장했다. 라벨 노이즈와 라벨 수에 따른 성능 변화를 분석하기 위해 다양한 라벨 수(5~89)를 실험적으로 사용했다.
2. **MLSP‑VQA 모델 제안**
- **특징 추출**: 사전 학습된 InceptionResNet‑v2의 모든 인셉션 블록 출력을 전역 평균 풀링(GAP)하여 고정 차원의 벡터(다중 레벨 특징)로 변환한다. 이는 저‑레벨 색·텍스처부터 고‑레벨 의미론까지 포괄한다.
- **프레임 선택**: 각 비디오에서 일정 수(보통 10~20)의 대표 프레임을 추출하고, 각 프레임에 대해 MLSP 특징을 계산한다.
- **네트워크 변형**:
* **MLSP‑VQA‑FF**: 프레임별 특징을 평균한 뒤 2~3개의 완전 연결층으로 MOS를 예측하는 가장 단순하고 효율적인 구조.
* **MLSP‑VQA‑RN**: 프레임 순서를 보존하기 위해 GRU 기반 순환 레이어를 삽입, 시간적 변화를 학습한다.
* **MLSP‑VQA‑HYB**: FF와 RN의 장점을 결합해 프레임 평균과 순환 정보를 동시에 활용한다.
- **학습 효율성**: 전체 네트워크를 파인튜닝하는 전통적 전이 학습 대비 메모리 사용량이 5~10배 적고, 학습 시간도 3~4배 빠르다.
3. **광범위한 실험 및 분석**
- **인‑와일드 벤치마크**: KoNVid‑1k, LIVE‑VQC, LIVE‑Qualcomm 등 기존 인‑와일드 데이터베이스에 대해 교차‑테스트를 수행. KonVid‑150k에서 사전 학습된 MLSP‑VQA‑FF는 KoNVid‑1k에서 SRCC 0.83, LIVE‑VQC에서 0.75, LIVE‑Qualcomm에서 0.64를 기록, 모두 기존 최고 기록을 초과한다.
- **인‑데이터셋 테스트**: 동일 데이터셋 내 훈련·테스트(예: KoNVid‑1k)에서도 SRCC 0.82를 달성, 기존 딥러닝 모델(0.80) 및 손수 만든 특징 기반 방법(0.78)을 앞선다.
- **라벨 노이즈·데이터 크기 실험**: 라벨 수를 5→20→50→89로 증가시킬수록 SRCC가 상승하지만, 50~89 구간에서는 수익 감소가 관찰된다. 또한 인위적인 라벨 노이즈를 추가했을 때도 MLSP‑VQA‑FF는 비교적 강인한 성능을 유지한다. 이는 대규모 데이터가 라벨 정확도보다 모델 일반화에 더 큰 영향을 미친다는 결론을 뒷받침한다.
- **비교 대상**: 기존 손수 만든 특징 기반 모델(V-BLIINDS, TLVQM 등)과 최신 딥러닝 기반 모델(NR‑VQA‑CNN, VSFA 등)을 동일 조건에서 비교했으며, 모든 경우에서 MLSP‑VQA‑FF가 우수했다.
**시사점 및 활용 가능성**
- **산업 적용**: 스트리밍 서비스, 사용자 생성 콘텐츠 플랫폼 등에서 실시간 품질 모니터링 및 적응형 인코딩에 바로 적용 가능. 경량 구조 덕분에 서버·클라우드 비용을 절감하면서도 높은 정확도를 유지할 수 있다.
- **연구 확장**: KonVid‑150k는 라벨 수와 데이터 양 사이의 최적 배분을 연구할 수 있는 귀중한 리소스로, 향후 라벨링 비용을 최소화하면서도 성능을 극대화하는 전략을 설계하는 데 활용될 수 있다. 또한 MLSP 특징 추출 방식은 다른 비디오 기반 과제(예: 행동 인식, 비디오 요약)에도 전이 학습 형태로 적용 가능하다.
결론적으로, 본 논문은 규모와 다양성에서 기존 데이터베이스를 크게 뛰어넘는 KonVid‑150k를 공개하고, 다중 레벨 공간 풀링 특징을 활용한 경량 VQA 모델을 제안함으로써 인‑와일드 비디오 품질 평가 분야의 성능 한계를 크게 확장하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기