신뢰성 있는 샘플 제공을 위한 딥러닝 기반 인센티브 메커니즘
본 논문은 인간 에이전트가 직접 샘플 \(x_i\sim p(x)\) 을 보고하도록 설계된 “샘플 엘리시테이션” 문제를 정의하고, f‑다이버전스의 변분 형태를 딥 뉴럴 네트워크로 추정함으로써 근사적 인센티브 호환성을 달성한다. 제안된 메커니즘은 이론적 오류 경계와 베이지안 내시 균형을 보장하며, f‑GAN과의 연결을 통해 수집된 샘플로부터 전체 분포를 재구성한다. 합성 데이터와 MNIST·CIFAR‑10 실험을 통해 진실된 샘플을 효과적으로 유도…
저자: Jiaheng Wei, Zuyue Fu, Yang Liu
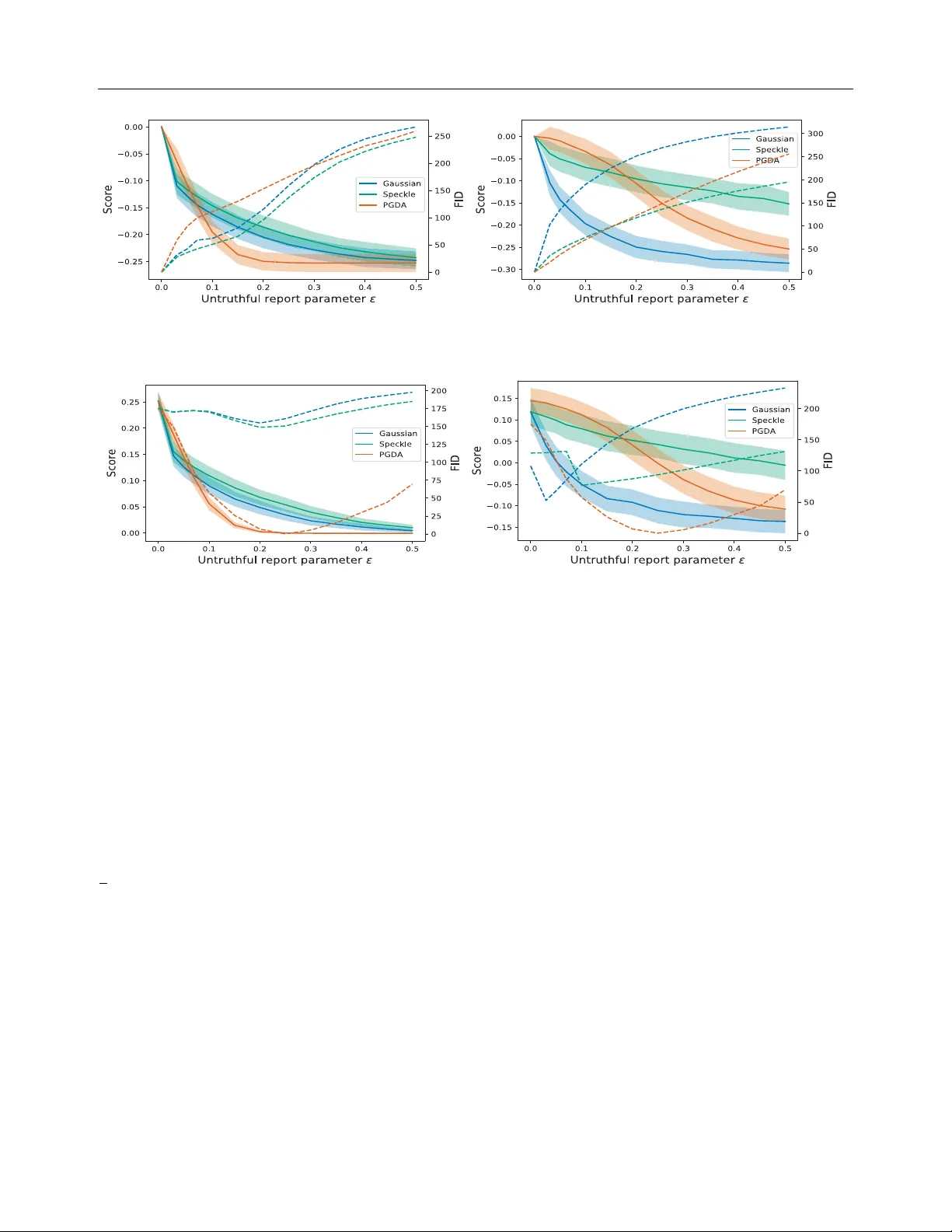
본 논문은 데이터 집약적인 머신러닝 시스템, 특히 딥러닝 모델을 학습시키기 위해 필요한 신뢰할 수 있는 샘플 \((x,y)\) 을 대규모로 확보하는 문제에 초점을 맞춘다. 전통적인 정보 엘리시테이션 연구는 에이전트에게 복잡한 확률분포 \(p(x)\) 그 자체를 보고하도록 요구하지만, 인간이 고차원·연속형 분포를 정확히 기술하는 것은 인지적 부담이 크다. 따라서 저자들은 “샘플 엘리시테이션(sample elicitation)”이라는 새로운 문제 정의를 제시한다. 여기서는 에이전트가 직접 \(x_i\sim p(x)\) 을 샘플링해 보고하도록 하고, 메커니즘 설계자는 이러한 보고가 진실된지 평가할 수 있는 스코어링 함수를 구축한다.
문제 설정은 두 가지 시나리오로 나뉜다. 첫 번째는 메커니즘 설계자가 일정량의 ‘그라운드 트루스’ 샘플을 보유하고 있는 경우이며, 두 번째는 오직 에이전트가 보고한 샘플만을 이용해야 하는 상황이다. 두 경우 모두 에이전트가 자신의 샘플을 임의의 변환 \(r_i(\cdot)\) 으로 보고할 수 있음을 가정한다. 목표는 스코어 \(S\) 가 다음을 만족하도록 설계하는 것이다. 진실된 보고에 대한 기대 스코어가 변조된 보고에 대한 기대 스코어보다 최소 \(\epsilon\) 만큼 크게 하고, 이 차이가 \(1-\delta\) 확률로 유지되게 한다. 이를 (δ, ε)‑properness 혹은 (δ, ε)‑베이지안 내시 균형(BNE)이라고 부른다.
핵심 이론적 도구는 f‑다이버전스 \(D_f(Q\|P)\) 이다. 기존 연구에서 적절한 스코어링 룰은 Bregman 다이버전스와 연결되지만, 고차원·연속형 데이터에서는 밀도함수 자체를 알 수 없으므로 변분 형태를 이용한다. Fenchel 이중성을 적용하면
\(D_f(Q\|P)=\max_{t}\mathbb{E}_{Q}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기