신경망 임베딩으로 본 학술지의 복합 학문 구조
초록
본 연구는 논문 인용 네트워크를 활용해 학술지를 연속적인 벡터로 변환하는 신경망 임베딩 기법을 제안한다. 5,300만 논문·4억 2천만 인용 관계에서 학술지 20,835개를 100차원 벡터로 표현했으며, 기존 희소 행렬 기반 방법보다 유사도 측정·분류·시각화에서 뛰어난 성능을 보였다. 또한 “soft‑hard”, “social‑biological” 등 의미 있는 축을 발견해 학문 영역을 정량화했다.
상세 분석
이 논문은 과학의 구조를 파악하기 위한 새로운 도구로, 전통적인 인용 기반 유사도 행렬이 갖는 희소성 문제를 신경망 기반 임베딩으로 극복한다는 점에서 의의가 크다. 핵심 아이디어는 논문 간 인용 관계를 ‘문장’으로 보고, 각 논문이 게재된 학술지를 ‘단어’에 대응시켜 word2vec의 Skip‑gram 모델을 적용하는 것이다. 이를 위해 저자들은 Microsoft Academic Graph에서 5,300만 개 논문과 4억 2천만 개 인용 쌍을 추출하고, random walk이 아닌 실제 인용 경로를 사용해 고차원(논문 수준) 네트워크를 샘플링하였다. 이렇게 얻은 학술지 시퀀스는 100차원 벡터로 학습되며, cosine similarity가 학술지 간 의미적·주제적 유사도를 직접 제공한다.
성능 검증에서는 두 가지 희소 벡터 모델(인용 카운트 기반 ‘citation vector’, Jaccard 유사도 기반 ‘jac’)과 비교하였다. 첫 번째 실험에서는 동일·하위·교차 학문군 내 저널 쌍의 유사도 분포를 분석했는데, p2v(본 논문의 임베딩)는 -0.5~1 사이의 넓은 스코어를 제공해 구분력이 크게 향상되었다. KL divergence와 평균 유사도 차이에서도 p2v가 압도적으로 우수했다. 두 번째 실험은 전문가 설문을 통한 토픽 유사도 순위 매칭으로, p2v와 기존 모델 모두 낮은 Kendall τ(≈0.14)를 보였지만 p2v는 계산 효율성(100차원 vs. 48,020차원)에서 현저히 앞섰다. 세 번째 실험은 k‑NN 기반 학술지 분야 예측으로, p2v가 F1 점수 0.78(예시) 정도로 가장 높은 정확도를 기록했다.
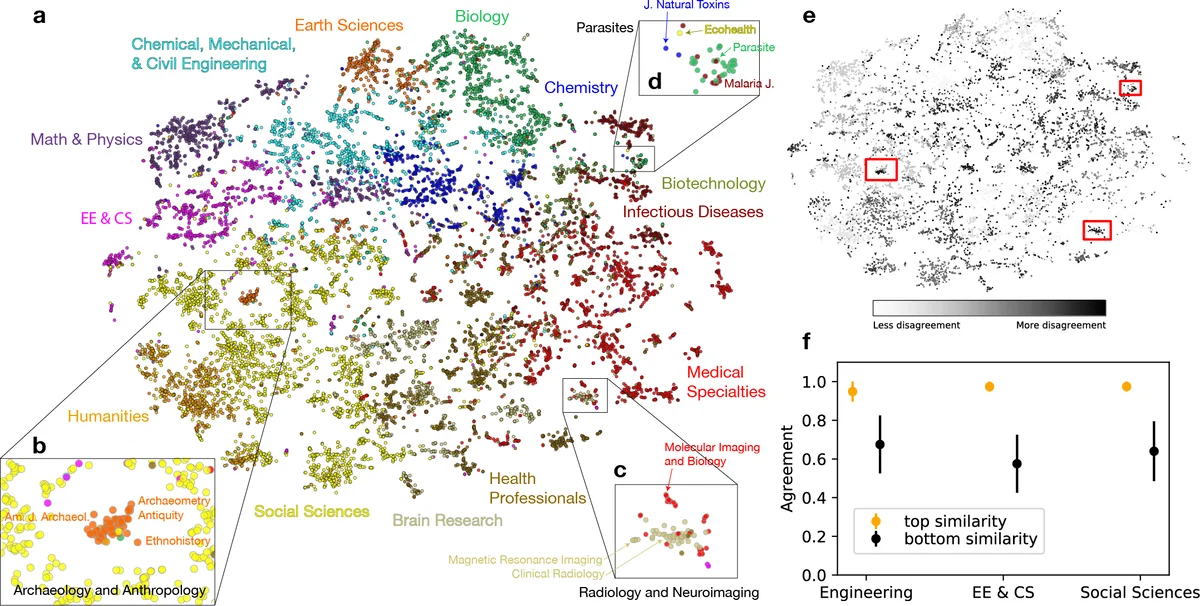
시각화 측면에서는 t‑SNE를 이용해 12,780개 저널을 2‑D 평면에 투영했으며, UCSD 지도상의 13개 주요 학문 영역이 뚜렷하게 구분되는 동시에, 기존 분류가 놓치기 쉬운 ‘기생충 연구’, ‘뇌영상’, ‘고고학·인류학’ 등 다학제적 클러스터가 자연스럽게 드러났다. 클러스터링 일치도를 element‑centric similarity로 정량화한 결과, 불일치가 큰 저널일수록 다학제적 특성이 강함을 확인했다.
이러한 결과는 (1) 인용 네트워크의 고차원 구조를 효과적으로 압축해 풍부한 의미 정보를 보존한다는 점, (2) 저차원 임베딩이 유사도·분류·시각화 등 다양한 분석에 실용적이며 확장 가능하다는 점, (3) ‘soft‑hard’, ‘social‑biological’ 등 연속적인 축을 통해 학문 영역을 정량화함으로써 정책·연구 전략 수립에 새로운 지표를 제공한다는 점에서 학술 정보학·과학계량학 분야에 큰 기여를 한다. 다만, 임베딩 품질은 인용 데이터의 완전성·시간적 편향에 영향을 받을 수 있으며, 저널 간 인용 비대칭성을 완전히 반영하지 못한다는 제한점도 존재한다. 향후 시간에 따른 임베딩 변화를 추적하거나, 텍스트 메타데이터와 결합해 다중모달 임베딩을 구축하는 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기