거의 희소 행렬의 근사 곱셈과 분산 작업 기반 병렬 프레임워크
초록
본 논문은 지수적 감쇠 특성을 갖는 대규모 행렬에 대해 입력 행렬과 부분 행렬 곱셈 모두를 트렁케이션하는 세 가지 근사 곱셈 방법을 제안하고, Chunks‑and‑Tasks 프로그래밍 모델을 이용한 완전 재귀형 분산 구현을 제시한다. 오류 분석을 통해 Frobenius 노름 오차가 행렬 크기 n에 대해 O(n¹ᐟ²), 트렁케이션 임계값 τ에 대해 O(τ^{p/2}) (p<2) 로 수렴함을 증명하고, 실험을 통해 결합 방법이 통신량을 절반 수준으로 감소시키며 약 10⁶ 원자 규모 시스템에서도 우수한 약한 스케일링을 보임을 확인한다.
상세 분석
이 연구는 전통적인 희소 행렬 곱셈과 완전 밀집 행렬 곱셈 사이에 위치하는 ‘거의 희소’ 행렬을 대상으로 한다. 이러한 행렬은 전자구조 계산에서 나타나는 지수적(또는 대수적) 감쇠 특성을 가지고 있어, 원소의 절대값이 거리 함수 d(i,j)에 따라 급격히 감소한다. 저자들은 두 가지 기존 접근법—입력 행렬 자체를 트렁케이션하는 방법과, 부분 행렬 곱셈 결과를 트렁케이션하는 Sparse Approximate Matrix Multiplication(SpAMM) 알고리즘—을 결합하여, 입력 행렬과 부분 곱셈 모두에 동일한 임계값 τ를 적용하는 새로운 혼합 기법을 제안한다.
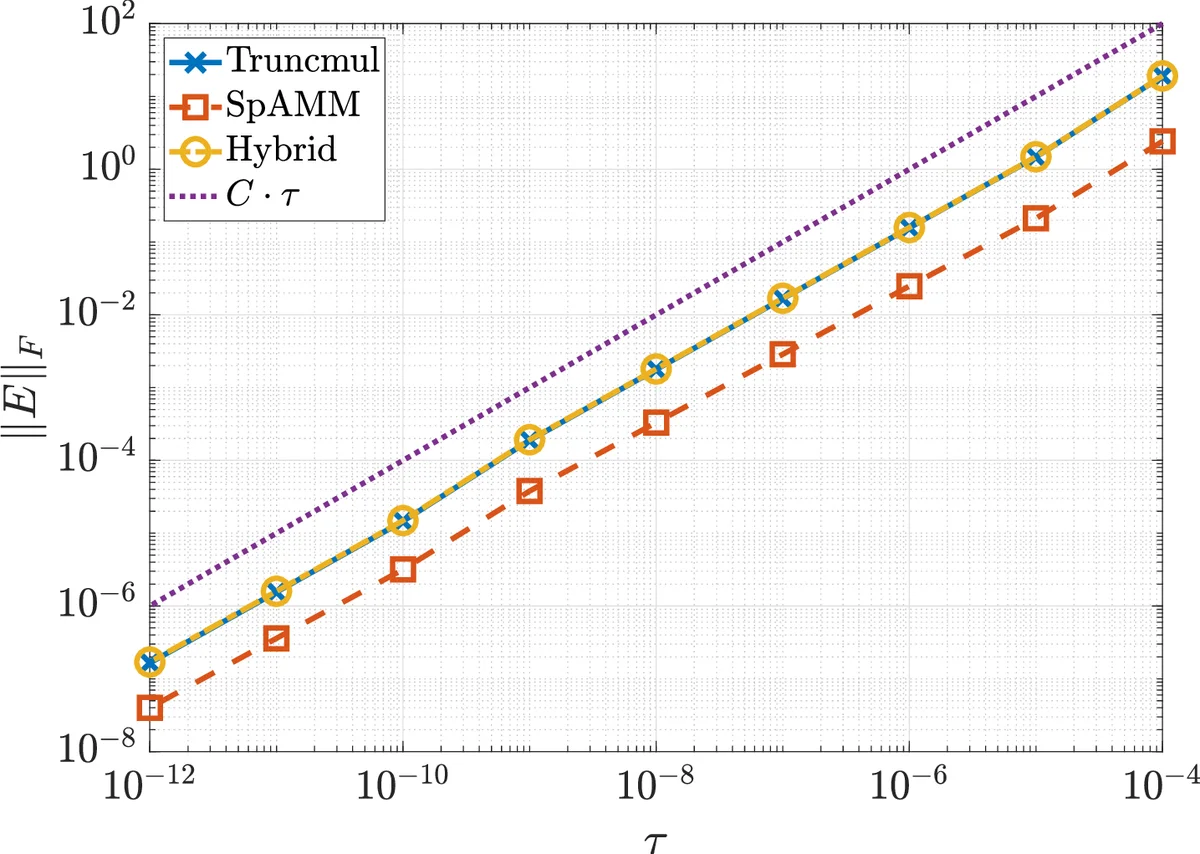
핵심 이론적 기여는 오류 분석이다. 정의된 거리 함수와 감쇠 상수(α, c)를 이용해, 행렬 A와 B가 각각 |a_{ij}| ≤ c₁ e^{-α d(i,j)}, |b_{ij}| ≤ c₂ e^{-α d(i,j)} 를 만족한다는 가정 하에, 트렁케이션 후 행렬 ˜A, ˜B를 정의하고 그 곱 ˜C와 정확한 곱 C=A·B의 차이 E=C-˜C를 분석한다. Lemma 4와 Theorem 5, 6을 통해 원소별 오차가 O(τ) 로 선형 감소하고, 전체 Frobenius 노름 오차는 n이 무한대로 갈 때 O(n^{1/2}) 로 성장하지만 τ→0 일 때 O(τ^{p/2}) (p<2) 로 급격히 감소함을 보인다. 이는 기존 SpAMM이 제시한 O(n) 수준의 오차 상한보다 훨씬 강력한 결과이며, 실제 계산에서 τ를 충분히 작게 잡으면 거의 정확한 결과를 얻을 수 있음을 의미한다.
구현 측면에서는 Chunks‑and‑Tasks(C&T) 모델을 채택한다. C&T는 데이터와 연산을 ‘청크’와 ‘태스크’로 분리하고, 런타임 스케줄러가 작업을 동적으로 워크스틸링 방식으로 배분한다. 이 구조는 재귀적인 쿼드트리 분할과 깊이‑우선 탐색을 자연스럽게 지원하며, 행렬 블록이 서로 다른 노드에 위치해도 통신을 최소화한다. 특히, 입력 행렬 트렁케이션을 사전에 수행하면 전송해야 할 블록 수가 크게 줄어들어, 결합 방법에서는 통신량이 기존 두 방법 대비 약 2배 감소한다는 실험적 증거를 제시한다.
실험은 두 단계로 진행된다. 첫 번째는 인공적인 1‑차원 거리 모델을 사용한 스케일링 테스트로, n이 2^{10}부터 2^{20}까지 증가할 때 오류와 실행 시간을 측정한다. 두 번째는 실제 전자구조 계산에서 얻은 약 10⁶ 원자 규모의 행렬을 대상으로, 409616384 코어 클러스터에서 약한 스케일링을 평가한다. 결과는 결합 방법이 동일한 τ에 대해 정확도는 유지하면서, 통신량 감소와 작업 부하 균형 향상으로 전체 실행 시간이 1520% 정도 단축됨을 보여준다.
이 논문은 다음과 같은 의미를 가진다. 첫째, 거의 희소 행렬에 대한 오류 이론을 체계화함으로써, 트렁케이션 파라미터 선택에 대한 명확한 가이드라인을 제공한다. 둘째, C&T 기반의 완전 재귀형 구현이 대규모 분산 환경에서 효율적인 로드 밸런싱과 낮은 통신 오버헤드를 달성할 수 있음을 실증한다. 셋째, 전자구조 계산뿐 아니라 거리 기반 감쇠가 존재하는 다양한 과학·공학 문제(예: 커널 기반 머신러닝, 적분 방정식)에도 적용 가능한 일반적인 프레임워크를 제시한다. 향후 연구는 비정형 거리 함수, 동적 τ 조정 전략, 그리고 GPU와 같은 이종 자원과의 통합을 통해 성능을 더욱 확대할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기