음악 태깅을 위한 오디오 전처리 방법 비교
초록
본 논문은 딥러닝 기반 음악 태깅에서 사용되는 다양한 오디오 전처리 기법을 실험적으로 비교한다. 시간‑주파수 표현, 로그 압축, 주파수 가중치 및 스케일링을 조합한 12가지 설정을 평가한 결과, 대부분의 전처리 방법은 성능에 큰 영향을 주지 않으며, 로그(데시벨) 압축만이 유의미한 성능 향상을 제공한다는 것을 확인하였다.
상세 분석
이 연구는 음악 정보 검색 분야에서 딥 뉴럴 네트워크가 입력 전처리 단계에 얼마나 민감한지를 정량적으로 밝히는 데 초점을 맞추었다. 먼저, 2‑D 컨볼루션 네트워크(k2c2 구조)를 고정하고, 입력으로는 96개의 멜 밴드와 1 360개의 시간 프레임을 갖는 단일 채널 스펙트로그램을 사용하였다. 데이터는 Million Song Dataset의 30 초 MP3를 12 kHz로 다운샘플링하고 256 샘플 홉 사이즈, 512‑포인트 FFT로 변환하였다.
시간‑주파수 표현에 대해서는 STFT와 멜 스펙트로그램을 동일한 훈련 규모에서 비교했으며, 고해상도 STFT(23.3 Hz)와 멜 스펙트로그램(35.9 Hz) 모두 비슷한 AUC를 보였다. 이는 충분한 데이터가 있을 경우 네트워크가 원시 STFT에서 유용한 특징을 자체적으로 학습할 수 있음을 시사한다. 그러나 멜 스펙트로그램은 차원 감소와 계산 효율성 측면에서 실용적이다.
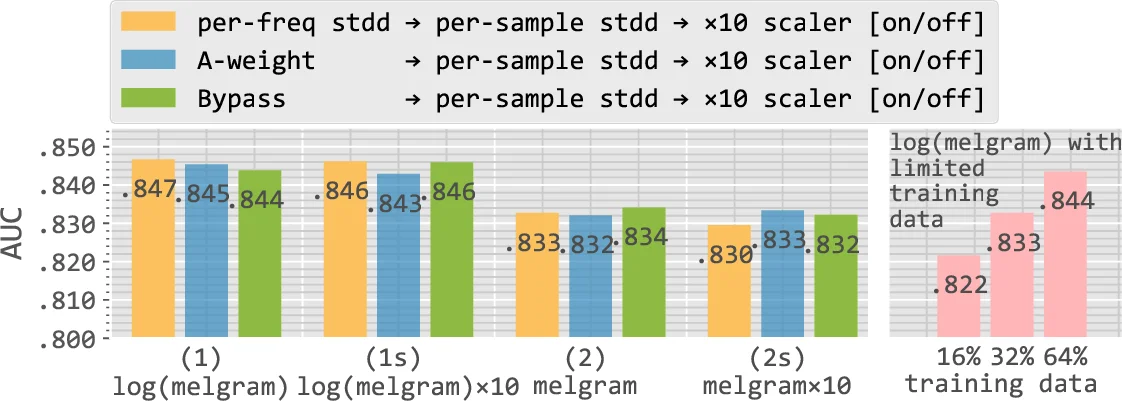
주파수 축 가중치(주파수별 표준화, A‑weighting, 무가중치)와 스케일링(입력값을 10배 확대) 두 축을 독립적으로 조합하였다. 실험 결과, 세 가지 가중치 모두 AUC 차이가 0.004 이하로 거의 동일했으며, 스케일링 역시 성능에 영향을 주지 않았다. 이는 배치 정규화와 같은 내부 정규화 메커니즘이 입력 스케일 차이를 자동 보정하기 때문이다.
가장 큰 차이를 만든 요소는 로그 압축이다. 로그(데시벨) 변환을 적용한 멜 스펙트로그램은 입력 분포를 거의 정규에 가깝게 만들고, 극단적인 값들을 억제한다. 반면 선형 스펙트로그램은 매우 편향된 히스토그램을 보여 학습 시 수치적 안정성이 떨어진다. 실험에서는 로그 압축을 적용했을 때 AUC가 평균 0.007~0.009 정도 상승했으며, 동일한 성능을 얻기 위해서는 로그 압축을 사용하지 않은 경우 데이터 양을 두 배 이상 늘려야 함을 정량화하였다.
또한, 가중치 초기화에 따른 변동성을 15번 반복 실험으로 측정했으며, 표준편차가 0.001 이하로 매우 낮아 실험 재현성이 확보됨을 확인했다. 전체적으로, 전처리 단계에서 대부분의 변형은 네트워크 성능에 미미하지만, 인간 청각 감각을 반영한 로그 압축은 필수적인 전처리임을 명확히 밝혔다.
댓글 및 학술 토론
Loading comments...
의견 남기기