대화형 교육 에이전트로 텍스트 분류 배우기
초록
본 논문은 인간 교사가 대화형 인터페이스를 통해 텍스트 분류 모델을 가르칠 수 있는 시스템을 제안한다. Naïve Bayes 기반 분류기에 인간이 제공한 대화형 키워드와 Word2vec 기반 의미 유사도를 결합하여 사전 학습 여부에 따라 두 가지 추론 방식을 적용한다. 60명의 MTurk 참여자를 대상으로 20개의 뉴스 기사(4개 카테고리)를 가르치고 테스트한 결과, 인간‑기계 대화가 기존 지도학습 대비 분류 정확도를 향상시킴을 확인하였다.
상세 분석
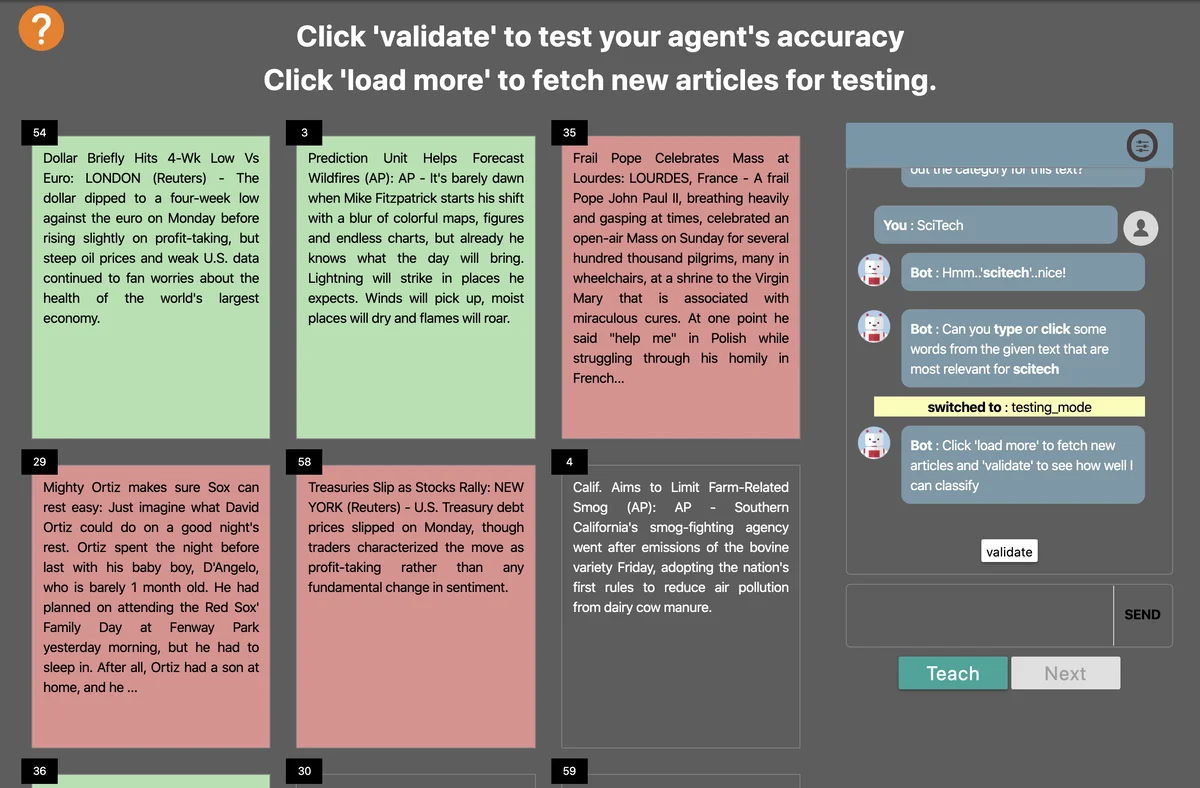
이 연구는 인터랙티브 머신러닝과 대화형 시스템을 융합한 ‘가르칠 수 있는’ 에이전트를 설계한다. 시스템은 웹 기반 챗봇 형태로 구현되며, 학습 모드와 테스트 모드 두 가지 인터페이스를 제공한다. 학습 모드에서는 사용자가 기사 텍스트에서 핵심 단어를 강조하거나 직접 입력하고, 에이전트는 이해가 부족한 부분을 질문함으로써 교사와의 상호작용을 유도한다. 이러한 대화는 교사가 자신의 지식을 재정립하도록 돕고, 동시에 에이전트는 ‘내부 관련 단어’, ‘외부 관련 단어’, ‘내부 비관련 단어’라는 세 가지 휴리스틱을 통해 피드백을 구조화한다.
학습 알고리즘은 전통적인 Naïve Bayes 모델에 인간이 제공한 대화형 키워드(s_i)를 추가 확률 요인으로 포함한다. 키워드와 문서 단어 간 유사도는 300 차원 Word2vec 벡터와 코사인 유사도로 측정되며, 유사도 임계값(0.2) 이하인 경우는 제외한다. 두 가지 경우를 제시했는데, (1) 사전 학습이 없는 경우는 P(C_k|s)만 사용하고, (2) 사전 학습이 있는 경우는 P(C_k|w)·P(C_k|s)를 곱해 최종 사후 확률을 계산한다. 이는 인간 피드백을 확률적 근거와 결합함으로써 기존 모델의 독립성 가정을 완화한다는 점에서 의미가 크다.
실험 설계는 60명의 크라우드워커를 대상으로 20개의 기사(각 카테고리 5개)를 학습·테스트하게 하였으며, 참가자는 최소 하나의 단어를 가르치고 자유롭게 학습·테스트 모드를 전환했다. 결과는 구체적으로 제시되지 않았지만, 논문은 인간‑대화 기반 학습이 전통적인 지도학습 대비 분류 정확도를 유의미하게 개선했음을 주장한다. 또한, 교사의 사전 경험, 카테고리별 사전 지식, 그리고 제공된 휴리스틱이 학습 효율에 미치는 영향을 논의한다.
이 연구는 대화형 인터페이스가 비전문가 교사에게도 직관적인 피드백 채널을 제공함으로써 머신러닝 모델을 개인화하고, 실시간으로 업데이트할 수 있는 가능성을 보여준다. 특히, 휴리스틱 기반 키워드 수집과 Word2vec 유사도 매칭이라는 두 단계 접근법은 텍스트 분류 외에도 다양한 도메인에 확장 가능할 것으로 기대된다. 다만, 현재는 Naïve Bayes와 단순 유사도 기준에 의존하므로 복잡한 문맥이나 다중 라벨 상황에서는 한계가 있을 수 있다. 향후 연구에서는 심층 신경망 기반 모델과의 통합, 대화 전략의 자동 최적화, 그리고 장기적인 교사‑학습자 관계 모델링이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기