링크 예측을 위한 지식 그래프 임베딩 비교 분석
본 논문은 16개의 최신 지식 그래프 임베딩 기반 링크 예측 모델을 체계적으로 비교한다. 모델의 정확도와 학습·추론 효율성을 평가하고, 규칙 기반 베이스라인과 함께 데이터셋별 구조적 특성이 성능에 미치는 영향을 분석한다. 또한 기존 평가 방식의 편향을 보완하기 위해 새로운 메트릭과 실험 설계를 제시한다.
저자: Andrea Rossi, Donatella Firmani, Antonio Matinata
본 논문은 지식 그래프(KG)의 불완전성을 해소하기 위한 핵심 기술인 링크 예측(Link Prediction, LP) 분야에서, 최신 임베딩 기반 모델들의 성능을 포괄적으로 비교·분석한다. 연구 동기는 현재 대부분의 LP 연구가 높은 정확도라는 단일 지표에만 집중하고, 모델 설계 선택이나 데이터셋 특성에 대한 체계적인 검증이 부족하다는 점에 있다. 특히, 테스트 셋에 소수의 엔티티가 과다하게 등장하는 경우, 모델이 구조적 편향을 이용해 인위적으로 높은 점수를 얻는 현상이 존재한다는 점을 지적한다.
논문은 먼저 KG를 정식화하고, LP 문제를 “” 혹은 “” 형태의 완전성 추정 문제로 정의한다. 임베딩 기반 접근법은 각 엔티티와 관계를 저차원 벡터(또는 행렬)로 매핑하고, 스코어링 함수 ϕ(h,r,t)를 통해 사실의 plausibility를 평가한다. 학습 단계에서는 양성 삼중항을 무작위로 변형해 부정 샘플을 생성하고, 트리플 손실(예: 마진 기반 손실)로 파라미터를 최적화한다. 평가에서는 Raw와 Filtered 두 가지 순위 계산 방식을 사용하며, 순위 동점 처리 정책(min, average, random, ordinal, max)도 상세히 설명한다.
다음으로 저자들은 16개의 최신 LP 모델을 세 가지 대분류(텐서 분해, 기하학적, 딥러닝)와 세부 그룹으로 나누어 체계적인 taxonomy를 제시한다. 텐서 분해 계열에는 DistMult, ComplEx, ANALOGY, SimplE, HolE, TuckER, TransE, STransE, CrossE, TorusE, RotatE, ConvE, ConvKB, ConvR, CapsE, RSN 등이 포함된다. 각 모델의 핵심 아이디어와 파라미터 복잡도, 사용된 손실 함수 등을 표 형태로 정리한다.
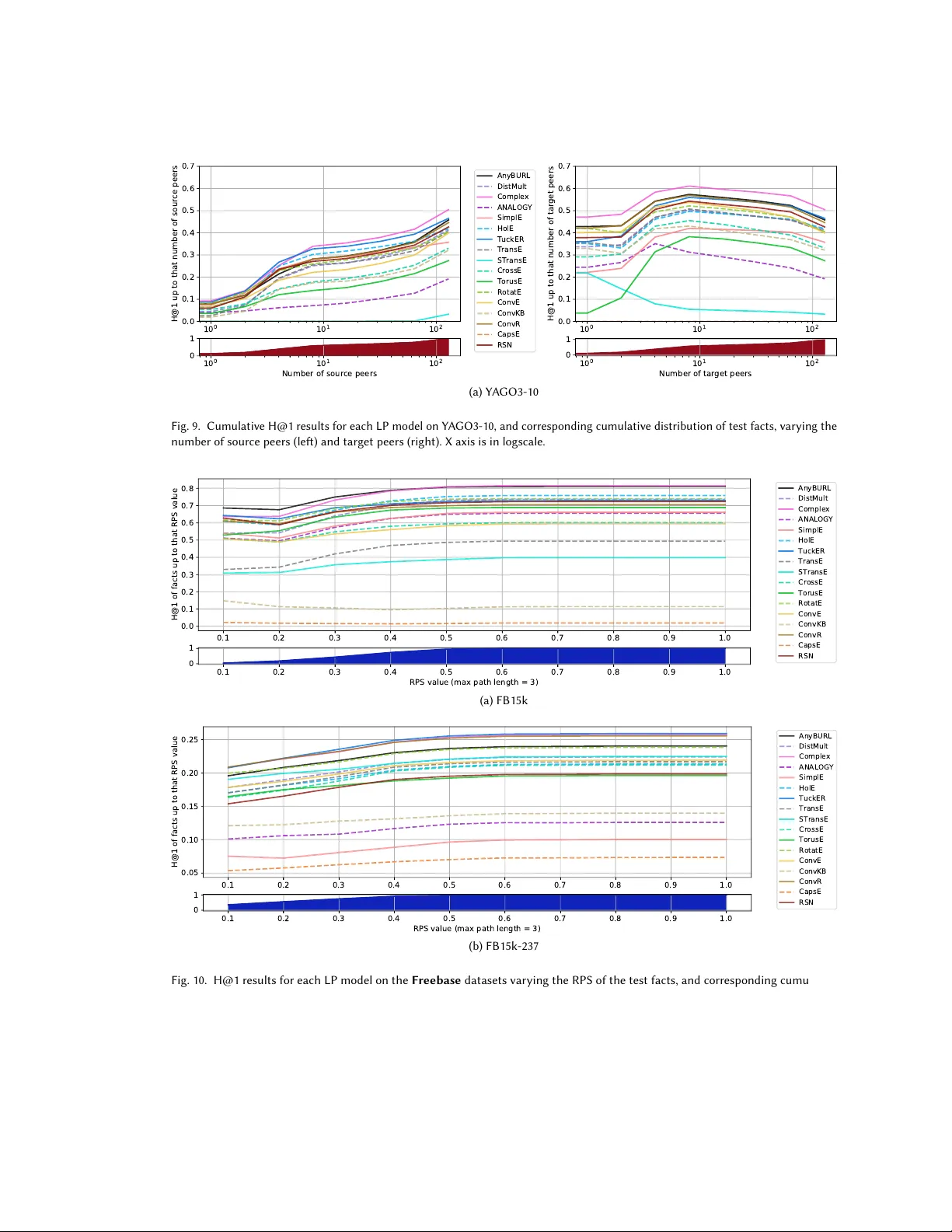
실험 설계는 다음과 같다. 5개의 대표 벤치마크(FB15k‑237, WN18RR, YAGO3‑10, DBpedia‑100k, OpenEA)를 선정하고, 각 모델을 동일한 하이퍼파라미터 탐색 프로토콜(learning rate, embedding dimension, 배치 크기 등) 하에 5‑fold 교차 검증한다. 성능 평가는 MRR, Hits@1, Hits@3, Hits@5, Hits@10을 사용하고, 학습 시간과 메모리 사용량도 함께 기록한다. 또한, 규칙 기반 베이스라인인 AMIE‑Plus를 포함해 임베딩 모델과의 절대적 차이를 확인한다.
주요 결과는 다음과 같다. 딥러닝 기반 ConvE와 RSN은 대부분의 데이터셋에서 최고 MRR(0.35~0.42)을 기록했지만, GPU 메모리 요구량이 8~12GB로 가장 높았다. 기하학적 모델 중 RotatE와 TorusE는 파라미터가 적음에도 불구하고 Hits@10에서 0.70 이상을 달성했으며, 특히 관계가 복잡하고 비대칭적인 YAGO3‑10에서 강점을 보였다. 텐서 분해 모델 중 ComplEx는 전반적으로 안정적인 성능을 보여, MRR 0.30~0.38 수준을 유지했으며, DistMult은 학습 속도가 가장 빨랐지만 MRR이 0.20 이하로 낮았다. 규칙 기반 AMIE‑Plus는 특정 대칭 관계에서 Hits@1이 0.45에 달했지만, 전체적인 MRR은 0.15 수준에 머물렀다.
구조적 특성 분석에서는 엔티티 차수(average degree), 관계 다양성(relational diversity), 클러스터링 계수와 같은 메트릭이 모델 성능에 유의미한 영향을 미침을 확인했다. 차수가 높고 관계가 다양할수록, 특히 딥러닝 모델이 높은 MRR을 기록했으며, 반대로 차수가 낮은 희소 영역에서는 기하학적 모델이 더 안정적인 Hits@1을 보였다. 또한, 테스트 셋에 과다 대표 엔티티가 포함된 경우, TransE와 STransE 같은 거리 기반 모델이 인위적으로 높은 Hits@10을 보이는 편향이 발견되었다. 이를 보정하기 위해 저자들은 “엔티티 균형 샘플링”과 “필터링된 순위 정책”을 결합한 새로운 평가 파이프라인을 제안했으며, 이 방법은 기존 평균 순위보다 편향을 크게 감소시켰다.
논문의 마지막 부분에서는 실용적인 교훈을 정리한다. 첫째, 모델 선택 시 정확도와 효율성 사이의 트레이드오프를 명확히 고려해야 한다. 둘째, 데이터셋 특성(엔티티 빈도, 관계 복잡도)을 사전에 분석하고, 이에 맞는 모델을 선택하거나 하이퍼파라미터를 조정해야 한다. 셋째, 기존의 단일 평균 지표 대신, 엔티티별 성능 분포와 구조적 특성 기반 평가를 병행해야 결과의 신뢰성을 높일 수 있다. 향후 연구 방향으로는 (1) 저자원 환경에서 경량화된 기하학적 모델의 개선, (2) 관계 유형별 맞춤형 스코어링 함수 설계, (3) 멀티모달(텍스트, 이미지) 정보를 통합한 하이브리드 임베딩, (4) 평가 편향을 최소화하는 표준화된 벤치마크 구축 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기