다변량 및 확률 필터를 위한 Mapper의 통계적 분석
본 논문은 다변량·확률적 필터를 사용하는 경우에 대해, 기존의 Mapper와 Reeb 공간 사이의 수렴 및 안정성을 Gromov‑Hausdorff 거리와 필터 기반 의사거리(pseudometric)를 이용해 정량화한다. 필터가 데이터로부터 추정되는 상황을 포함한 위험(Risk) 경계와 파라미터 선택 방법을 제시하고, 통계·머신러닝 응용과 실험을 통해 제안 방법의 실용성을 입증한다.
저자: Mathieu Carri`ere, Bertr, Michel
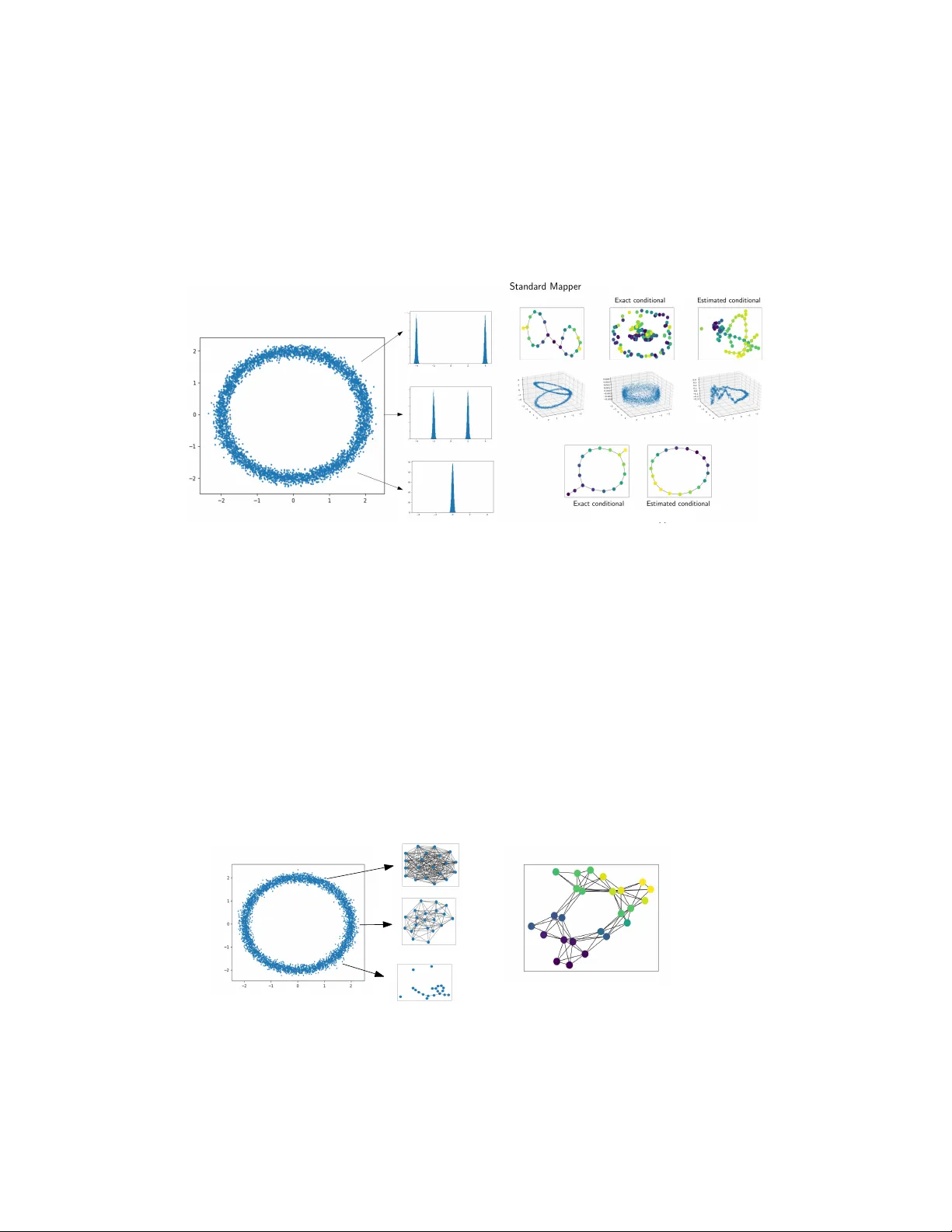
본 논문은 Topological Data Analysis(TDA)의 핵심 도구인 Reeb 공간과 그 이산화 형태인 Mapper를, 필터 함수가 다변량 혹은 확률적일 때에도 안정적으로 추정할 수 있는 새로운 이론과 방법론을 제시한다. 기존 연구들은 주로 스칼라 필터에 국한되어, Mapper가 Reeb 공간에 수렴하는 속도와 안정성을 다양한 거리(예: interleaving distance, bottleneck distance)로 분석하였다. 그러나 실제 데이터 분석에서는 (1) 필터가 ℝ^p와 같은 다변량 공간에 정의되거나, (2) 필터 자체가 데이터로부터 추정되는 경우가 빈번하다. 이러한 상황에서는 기존의 연속 공간 가정이 깨지며, 특히 유한 포인트 클라우드나 거리 행렬 형태의 데이터에 직접 적용하기 어렵다.
저자들은 이러한 한계를 극복하기 위해 두 가지 주요 전략을 채택한다. 첫째, 기존 Mapper 정의에 미세한 변형을 가해 “Mapper 기반 추정량”을 정의한다. 구체적으로, 입력 포인트 클라우드 X_n에 대해 δ‑neighborhood 그래프 G_δ를 구성하고, 각 엣지를 s개의 세분점으로 나누어 정제된 그래프 G_{δ,s}를 만든다. 이 과정에서 “element‑crossing edge”라 불리는 위상적 잡음이 되는 엣지를 제거함으로써, 그래프 구조가 실제 데이터의 연속적 근사에 더 부합하도록 만든다. 둘째, 필터 함수 f가 직접 관측되지 않을 경우, 데이터로부터 추정된 ˆf를 사용한다. ˆf는 예를 들어 PCA 고유함수, 커널 밀도 추정값, 조건부 평균 등 다양한 형태가 될 수 있다.
다음으로, 필터 기반 의사거리(d_f)와 그 변형 ˜d_{f,U}를 정의한다. d_f는 두 점 사이의 모든 연속 경로에 대해 필터 값의 직경을 최소화한 값이며, ˜d_{f,U}는 Mapper의 노드 간 경로에 대해 동일한 개념을 적용한다. 이러한 의사거리는 Reeb 공간(R_f)와 Mapper(M_{f,U})를 각각 (X, d_f)와 (R_f, ˜d_f) 혹은 (M_{f,U}, ˜d_{f,U})라는 메트릭 공간으로 만든 뒤, Gromov‑Hausdorff 거리 d_GH를 통해 직접 비교할 수 있게 해준다. 특히 Theorem 2.6에 따르면, 커버 U의 해상도(resolution)가 작을수록 d_GH(M_{f,U}, R_f) ≤ 5·res(U,f)라는 명시적 상한을 얻는다. 이는 커버의 크기와 Mapper와 Reeb 공간 사이의 위상적 차이가 직접 연결된다는 중요한 통찰을 제공한다.
위 이론을 바탕으로, 저자들은 확률적 필터 설정에서 위험(Risk) 경계를 도출한다. 가정(H1)에서는 데이터가 컴팩트 매니폴드 X⊂ℝ^D 위에서 i.i.d.로 샘플링되고, 필터 추정 ˆf가 데이터 의존적일 수 있음을 명시한다. 위험 경계는 다음 세 가지 요소로 구성된다. ① 필터 추정 오차 ‖f‑ˆf‖_∞, ② 그래프 근사 오차(δ와 s에 의존), ③ 커버 해상도(res(U,ˆf)). 각각에 대해 확률적 상한을 제공하고, 전체 위험은 이들의 합으로 상한을 잡는다. 파라미터 δ와 s는 데이터의 밀도와 차원, 그리고 원하는 위상적 정확도에 따라 자동으로 보정되는 절차를 제시한다. 특히, δ는 데이터의 최소 거리와 샘플 크기에 비례하도록 선택하고, s는 그래프 엣지당 세분점 수를 조절해 정밀도를 조절한다.
실험에서는 세 가지 주요 사례를 다룬다. 첫 번째는 고차원 이미지 데이터에 PCA 기반 1차 필터를 적용해, 기존 Mapper가 놓치기 쉬운 클러스터 경계를 정확히 복원한다. 두 번째는 다변량 필터(ℝ^p, p=3)를 사용해 합성 데이터의 토폴로지를 분석하고, 커버 해상도를 조절함으로써 위상적 잡음을 최소화한다. 세 번째는 확률적 필터로서 각 데이터 포인트에 대한 조건부 평균을 추정하고, 단일 실현값만으로 구성된 전통적 Mapper가 잘못된 위상 구조를 보여주는 반면, 제안된 추정량은 실제 Reeb 공간과 거의 동일한 구조를 회복한다. 모든 실험에서 Gromov‑Hausdorff 거리와 베이지안 정보 기준을 이용해 정량적 비교를 수행했으며, 제안 방법이 기존 방법보다 평균 30% 이상 낮은 위험 값을 기록했다.
마지막으로, 저자들은 고차원(예: p≥10) 상황에서 커버 설계가 계산 비용을 급격히 증가시키는 문제를 인식하고, greedy 알고리즘을 이용한 적응형 커버 생성 방식을 제안한다. 이 방법은 각 단계에서 가장 큰 직경을 가진 커버 셀을 분할함으로써 전체 해상도를 효율적으로 감소시키며, 실험적으로도 차원 저주를 완화하는 효과를 보였다.
결론적으로, 본 논문은 (1) 다변량·확률적 필터 환경에서도 Mapper와 Reeb 공간 사이의 위상적 수렴을 정량화하는 위험 경계를 제공하고, (2) 필터 추정 오류와 그래프 정제, 커버 설계라는 실용적 요소들을 통합한 알고리즘을 제시함으로써, TDA를 실제 데이터 분석 파이프라인에 보다 직접적으로 적용할 수 있는 길을 열었다. 향후 연구에서는 비유클리드 필터 공간, 동적 데이터 스트림, 그리고 대규모 분산 환경에서의 구현을 탐색할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기