글로벌 데이터 활용한 버그 로케이션 향상: GloBug 연구
초록
본 논문은 오픈소스 벤치마크 프로젝트에서 수집한 전역(bulk) 버그 보고서와 소스코드를 활용해 TF‑IDF와 Doc2Vec 모델을 사전 학습(pre‑train)함으로써 기존 IR 기반 결함 위치 추정 기법인 BugLocator의 정확도를 향상시키는 GloBug 프레임워크를 제안한다. 51개 프로젝트에 대한 실험 결과, 전역 TF‑IDF는 MRR 6.6%, MAP 4.8%의 평균 개선을 보였으며, 64%와 54%의 경우 각각 14% 이상 향상되었다. 반면, 전역 Doc2Vec 기반 임베딩은 기대 이하의 성능을 보여 TF‑IDF를 대체하기엔 한계가 있음을 확인하였다.
상세 분석
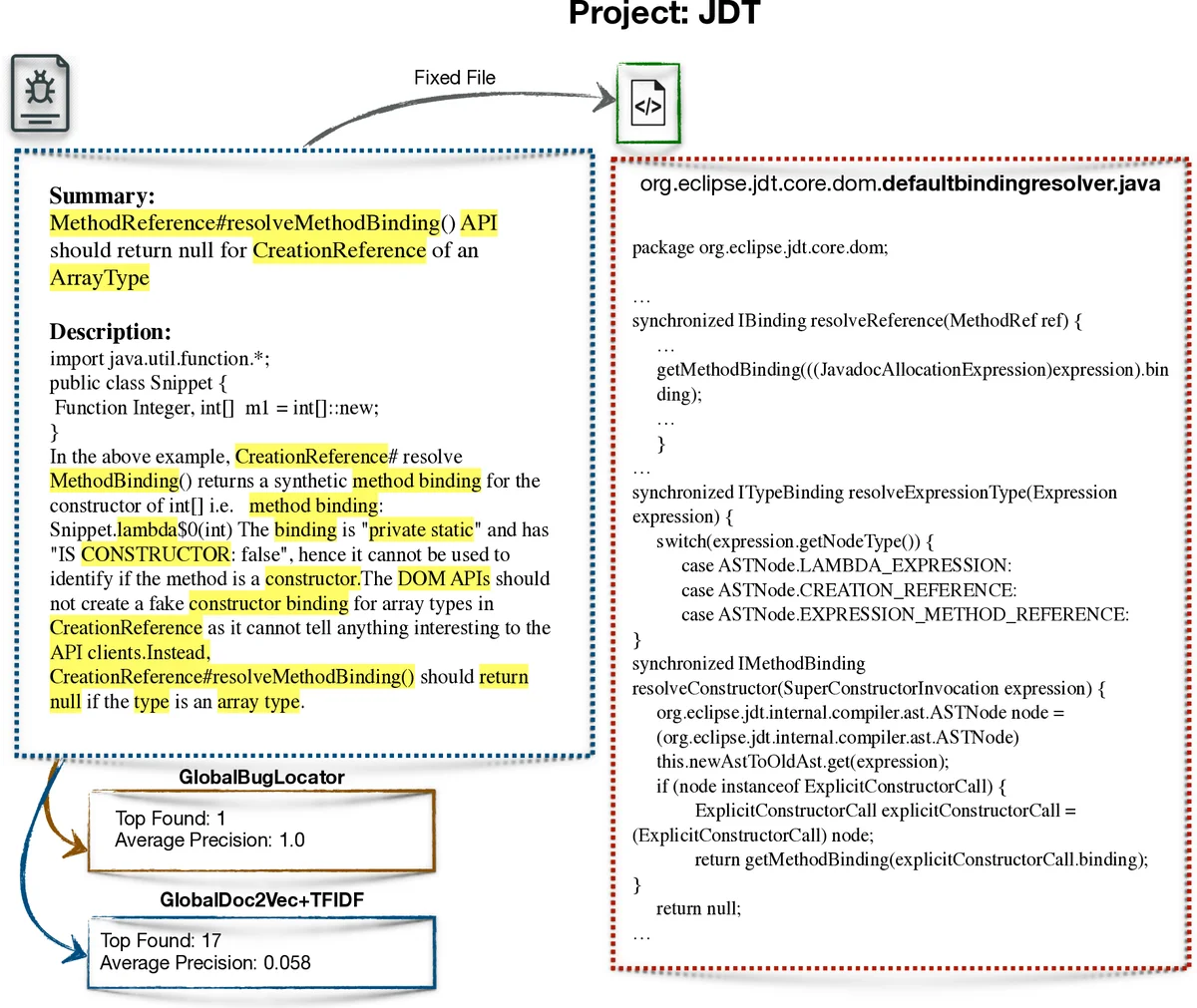
GloBug은 “전역 데이터(global data)”라는 새로운 학습 자원을 IR 기반 결함 위치 추정(IRFL) 영역에 도입한 점이 가장 큰 혁신이다. 기존 IRFL 기법들은 프로젝트 내부의 버그 보고서와 소스코드만을 활용해 TF‑IDF 혹은 유사한 벡터화 방식을 적용했으며, 데이터 양이 부족할 경우 IDF 가중치가 부정확해져 유사도 계산에 오류가 발생한다는 한계가 있었다. GloBug은 이 문제를 해결하기 위해 Bench4BL 벤치마크에 포함된 50여 개 오픈소스 프로젝트(총 51개 실험 프로젝트 중 50개를 학습, 1개를 테스트)에서 추출한 전체 어휘와 문서 빈도를 이용해 전역 IDF를 계산한다. 이렇게 구축된 전역 어휘 사전은 프로젝트마다 별도로 구축할 필요가 없으며, 새로운 버그가 보고될 때마다 동일한 전역 IDF를 재사용함으로써 런타임 오버헤드가 전혀 발생하지 않는다.
직접 유사도(direct relevance)와 간접 유사도(indirect relevance) 두 단계 모두 전역 IDF를 적용한다. 직접 단계에서는 버그 보고서와 소스 파일을 전역 TF‑IDF 벡터로 변환한 뒤 코사인 유사도로 순위를 매긴다. 간접 단계에서는 기존 BugLocator와 동일하게 과거 버그와 현재 버그 간의 텍스트 유사도를 계산하고, 그 결과를 기반으로 연관된 소스 파일을 다시 평가한다. 두 단계의 점수를 선형 결합해 최종 순위를 산출한다.
두 번째 시도인 전역 Doc2Vec 임베딩은 Word2Vec의 문서 수준 확장판으로, 문서 전체를 하나의 고정 차원 벡터로 표현한다. 전역 코퍼스를 사용해 사전 학습했음에도 불구하고, 실험에서는 TF‑IDF 대비 MAP·MRR 모두에서 유의미한 개선을 보이지 못했다. 이는 결함 위치 추정에서 단어 수준의 정확한 가중치(IDF)보다 문맥적 의미를 포괄하는 임베딩이 반드시 우수한 성능을 보장하지 않으며, 특히 버그 보고서와 소스 코드 사이의 어휘 격차가 큰 경우 TF‑IDF가 여전히 강력한 베이스라인임을 시사한다.
성능 평가에서는 MRR(Mean Reciprocal Rank)와 MAP(Mean Average Precision) 두 지표를 사용했으며, 전역 TF‑IDF는 평균 6.6%·4.8% 향상을 기록했다. 특히 64%의 프로젝트에서 MRR이 14% 이상, 54%의 프로젝트에서 MAP이 14% 이상 개선되었다. 이는 동일한 전역 데이터가 다른 최신 IRFL 도구들(예: DNN‑based, LDA‑based 등)이 BugLocator 대비 보이는 개선 폭보다 크게 앞선다는 것을 의미한다.
또한, 전역 학습은 일회성 오프라인 작업으로, 새로운 프로젝트에 적용할 때 추가적인 학습 비용이 들지 않는다. 이는 기업이나 오픈소스 커뮤니티가 기존에 구축된 전역 모델을 그대로 재사용함으로써 비용 효율적으로 결함 위치 추정 정확도를 높일 수 있음을 보여준다.
위험 요소로는 전역 어휘에 포함된 프로젝트와 테스트 프로젝트 간 도메인 차이가 클 경우 IDF 가중치가 왜곡될 가능성이 있다. 논문에서는 이러한 위협을 최소화하기 위해 다양한 언어와 규모의 프로젝트를 포함했으며, 결과의 통계적 유의성을 검증하였다. 그러나 전역 모델이 특정 도메인(예: 임베디드, 과학 계산)에서는 오히려 성능 저하를 일으킬 수 있다는 점은 향후 연구에서 추가 검증이 필요하다.
요약하면, GloBug은 전역 데이터 기반 TF‑IDF 학습을 통해 기존 BugLocator를 실질적으로 강화했으며, 전역 임베딩은 현재 단계에서는 기대 이하이지만 향후 더 정교한 모델(예: Transformer 기반)과 결합한다면 새로운 가능성을 열 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기