무선 네트워크 자원 관리의 다중에이전트 딥 강화학습 기반 혁신
본 논문은 각 송신기(AP)에 딥 강화학습 에이전트를 탑재하여, 지연된 사용자 피드백과 인접 AP와의 관측 교환을 활용해 사용자 스케줄링과 전송 전력을 동시에 결정하는 분산형 자원 관리 프레임워크를 제안한다. 관측·행동 공간을 고정 크기로 설계해 학습된 에이전트를 다양한 규모의 네트워크에 그대로 적용할 수 있으며, 시뮬레이션 결과 중앙집중형 정보이론적 기준에 근접하거나 일부 경우 능가하는 성능을 보인다. 또한 훈련·시험 환경 불일치에도 강인함을…
저자: Navid Naderializadeh, Jaroslaw Sydir, Meryem Simsek
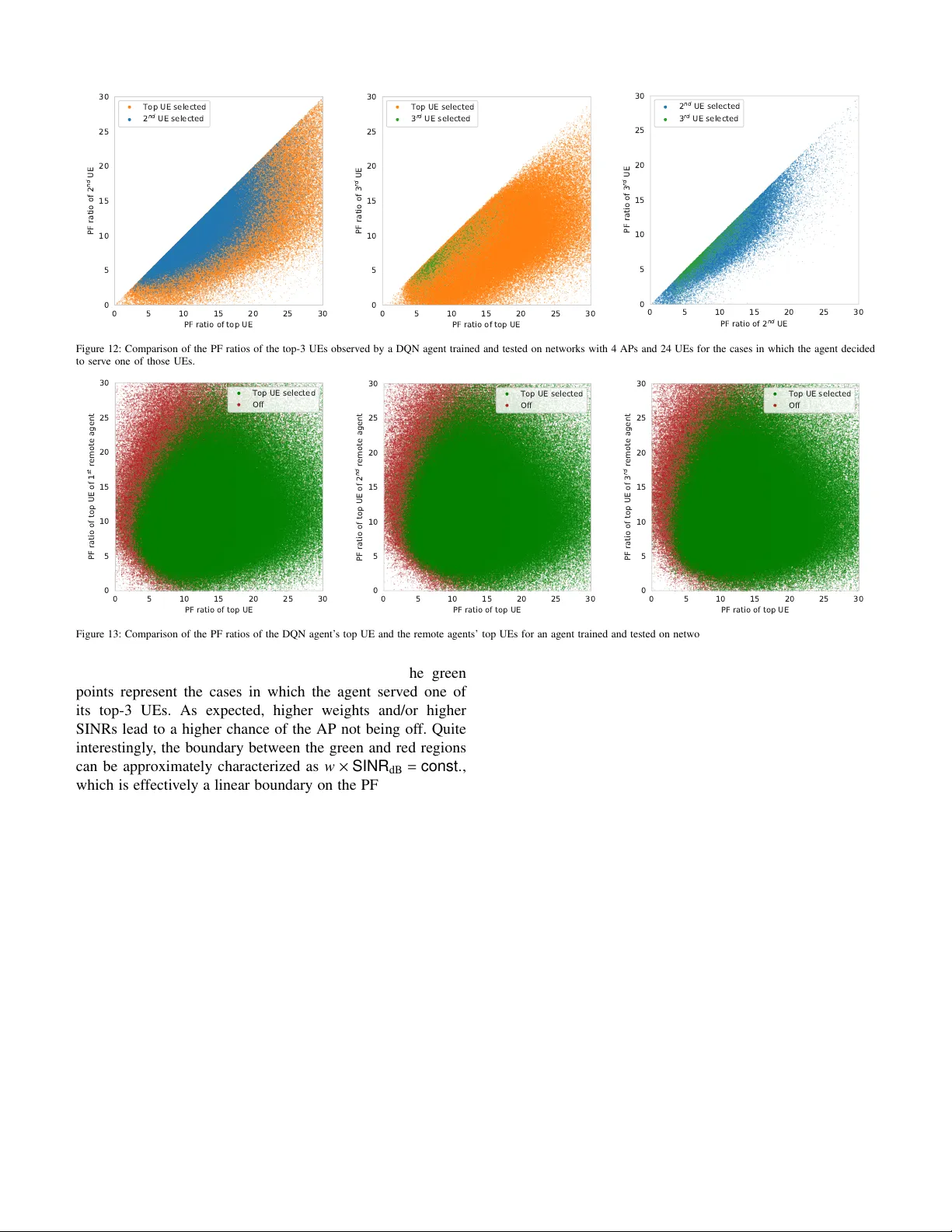
본 논문은 초밀집 5G·6G 네트워크에서 발생하는 자원 관리와 간섭 완화 문제를 해결하기 위해, 다중 에이전트 딥 강화학습(MARL) 기반의 분산형 프레임워크를 제안한다. 시스템 모델은 N개의 액세스 포인트(AP)와 K개의 사용자 장비(UE)로 구성되며, 각 AP는 고정된 사용자 풀 L_i를 보유한다. 매 스케줄링 슬롯 t마다 AP는 (i) 서비스할 UE j_i(t) 를 선택하고, (ii) 전송 전력 P_i(t) 를 결정한다. 전송 신호는 다중 AP 간 간섭을 포함하며, Shannon 용량식에 따라 각 UE의 순간 전송률 R_{j_i}(t) 가 계산된다. 목표는 전체 평균 스루풋(R_sum)과 5번째 백분위수(R_5%) 사이의 트레이드오프를 최적화하는 것이다.
전통적인 최적화 접근법은 비선형·조합적 특성으로 인해 계산 복잡도가 급격히 증가하고, 실시간 적용이 어렵다. 이에 저자는 각 AP에 딥 RL 에이전트를 부착하고, 중앙집중식 학습 후 분산 실행(Centralized Training & Distributed Execution, CTDE) 방식을 채택한다. 에이전트는 다음과 같은 관측을 이용한다. ① 연관 UE들의 채널 게인, 버퍼 상태, QoS 지표 등 M개의 피드백 f_{j,m}(t) 를 Δ_FB 간격마다 수집하고, δ_FB 지연 후 AP에 도착한다. ② 인접 AP와의 관측 교환을 δ_BH 지연 후 수행한다. 이러한 지연·언더샘플링된 피드백은 ‘percentile‑based normalization’ 기법을 통해 0~1 구간으로 정규화된다. 정규화는 사전 수집된 오프라인 데이터셋의 백분위수를 이용해 각 피드백 변수의 스케일을 동적으로 조정함으로써, 다양한 환경 변화에 대한 일반화 능력을 크게 향상시킨다.
행동 공간은 두 단계로 구성된다. 첫 번째 단계는 사용자 선택으로, 각 AP는 L_i 내에서 하나의 UE를 선택한다. 두 번째 단계는 전송 전력 선택으로, 연속적인 전력 레벨을
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기