퍼뮤테이션 기반 군중 라벨링 모델: 최적 추정과 강인성
본 논문은 기존 Dawid‑Skene 모델을 일반화한 퍼뮤테이션 기반 군중 라벨링 모델을 제안하고, 작업자와 질문의 난이도 순서를 이용한 두 가지 효율적인 추정 알고리즘(WAN, OBI‑WAN)을 설계한다. 새로운 난이도 가중 손실을 정의하여 전역 최소극값(minimax) 위험을 로그 차수까지 정확하게 분석하고, 제안된 알고리즘이 이론적 최적 한계에 근접함을 비대칭적 비동형성 상황에서도 입증한다. 합성 및 실제 데이터 실험을 통해 이론적 결과를…
저자: Nihar B. Shah, Sivaraman Balakrishnan, Martin J. Wainwright
1. 서론 및 배경
최근 크라우드소싱 플랫폼의 확산으로 대규모 라벨링이 가능해졌지만, 라벨의 품질은 작업자의 전문성 차이와 질문 난이도 차이 때문에 크게 변동한다. 기존의 Dawid‑Skene 모델은 각 작업자가 모든 질문에 대해 동일한 정확도 q_i를 가진다고 가정하는 rank‑1 구조를 갖는다. 이는 질문마다 난이도가 다를 경우 현실을 반영하지 못한다. 따라서 저자들은 작업자와 질문 각각에 대한 숨은 순열을 도입해, 행·열 모두 비증가하도록 정렬된 확률 행렬 Q*를 가정하는 퍼뮤테이션 기반 모델을 제안한다.
2. 모델 정의
- n명의 작업자와 d개의 이진 질문이 존재한다.
- 정답 벡터 x*∈{−1,+1}^d.
- 관측 라벨 행렬 Y_{ij}∈{−1,0,+1}는 작업자 i가 질문 j에 답했을 확률 p_obs와 정확도 Q*_{ij}에 따라 생성된다.
- 퍼뮤테이션 기반 가정: 존재하는 순열 π* (작업자 능력)와 σ* (질문 난이도) 에 대해, i≺i' ⇒ Q*_{ij}≥Q*_{i'j}, j≺j' ⇒ Q*_{ij}≥Q*_{ij'}. 즉, 행·열 모두 비증가한다.
- C_Perm은 이러한 조건을 만족하는 모든 Q*의 집합, C_DS는 전통적인 Dawid‑Skene 형태(Q* = q_DS·1^T)를 의미한다.
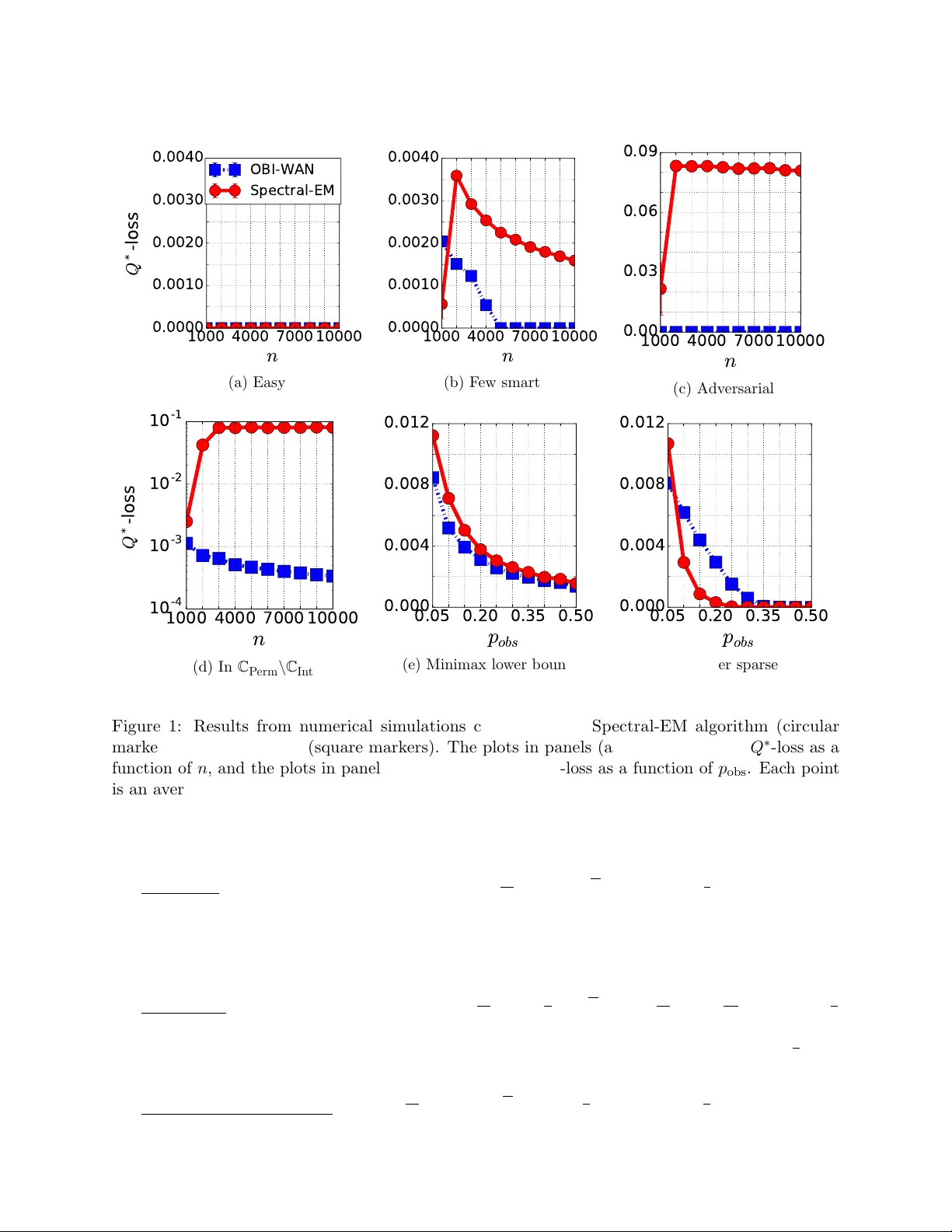
3. 손실 함수 및 최소극값 위험
전통적인 Hamming 손실은 모든 질문에 동일 가중치를 부여한다. 질문 난이도가 다르면 이는 부적절하므로, 저자들은 난이도 가중 손실 L_{Q*}를 정의한다.
L_{Q*}(b̂, x*) = (1/d) Σ_{j=1}^d 1{b̂_j≠x*_j}· (1/n) Σ_{i=1}^n (2Q*_{ij}−1)^2.
이는 각 질문의 “집합 지능”을 가중치로 사용한다. Q*_{ij}=1/2이면 해당 질문은 무작위 수준이므로 가중치가 0이 된다. 이 손실은 대칭성, 삼각 부등식,
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기