시스템 건강 기반 다중에이전트 정책 그라디언트와 PPO 확장
본 논문은 다중 로봇 시스템에서 각 에이전트의 “건강”(degradation) 상태를 정의하고, 이를 신용 할당 기준으로 활용한 정책 그라디언트 기법을 제안한다. 건강‑인포메드 베이스라인을 PPO에 통합해 연속 제어와 부분 관측 환경에서 기존 MARL 방법보다 학습 효율과 최종 성능을 크게 향상시켰다.
저자: Ross E. Allen, Jayesh K. Gupta, Jaime Pena
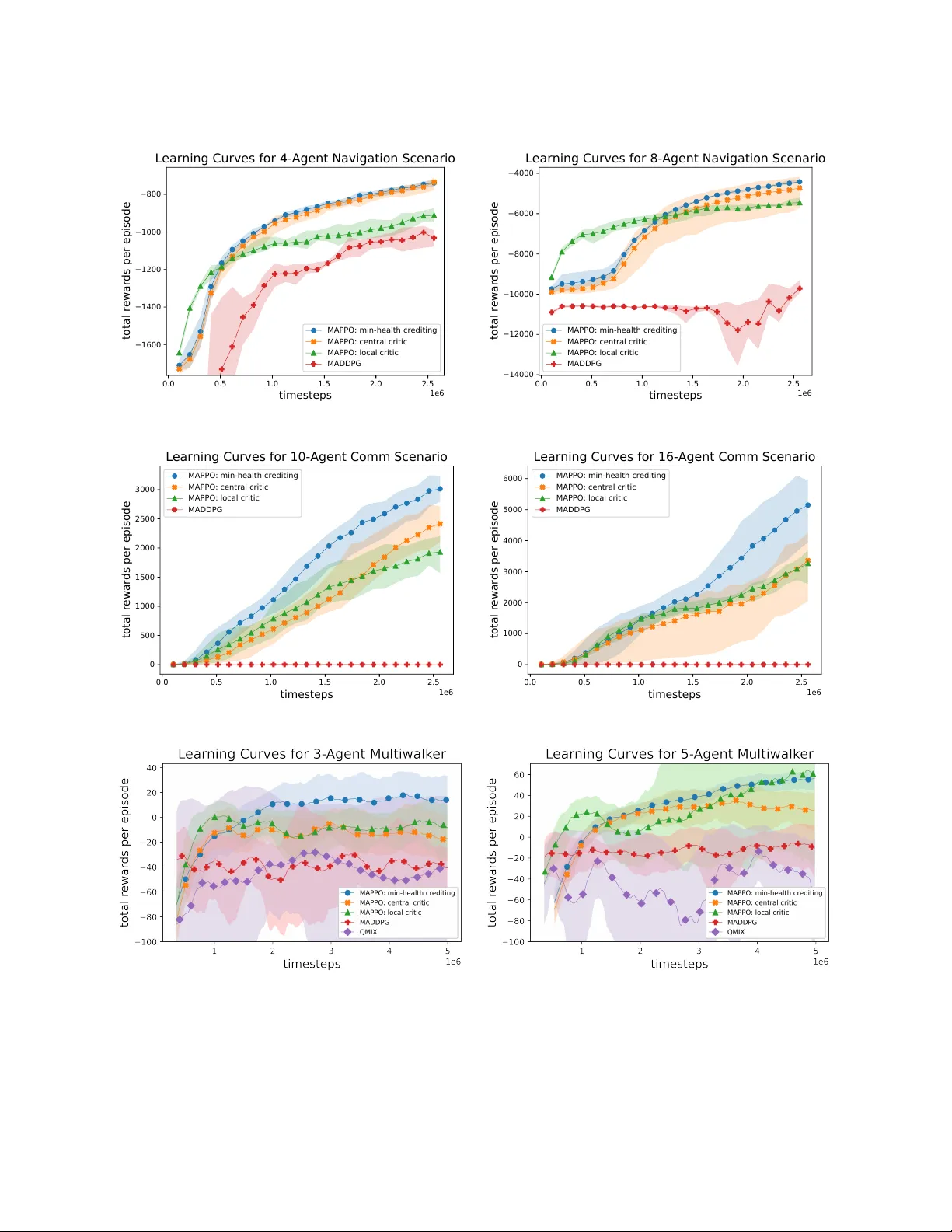
본 논문은 다중 로봇·다중 에이전트 시스템에서 에이전트 개별의 물리적·기능적 손상을 “시스템 건강”이라는 개념으로 정량화하고, 이를 강화학습의 신용 할당 메커니즘에 직접 통합함으로써 학습 효율을 크게 향상시키는 방법을 제시한다.
1. **서론 및 배경**
- 자동화·로봇 분야에서 “지루하고, 더럽고, 위험한(dull, dirty, dangerous)” 작업을 수행하는 다중 로봇 시스템은 개별 로봇의 센서·액추에이터 손상에 취약하다. 이러한 손상은 에이전트의 행동·관측 능력을 제한하며, 기존 MARL에서는 이러한 제약을 명시적으로 고려하지 못한다.
- 다중 에이전트 의사결정은 Dec‑POMDP로 모델링되며, 최적 정책 탐색은 NEXP‑complete 수준의 복잡도를 가진다. 따라서 근사적 방법으로 딥 RL이 활용되지만, 신용 할당 문제와 비정상성(non‑stationarity) 문제가 여전히 남아 있다.
2. **관련 연구**
- 기존 연구는 파라미터 공유, 중앙 집중식 학습·분산 실행, MADDPG, COMA, QMIX 등으로 신용 할당을 완화하려 했으며, 차이 보상(difference reward)인 WLU·AU를 제안했다. 그러나 대부분은 이산 행동 공간에 국한되거나 사전 모델링에 의존한다.
- 본 논문은 연속 행동·부분 관측 환경에서도 적용 가능한 차이 보상 기반 정책 그라디언트를 제시한다.
3. **시스템 건강 정의 및 성질**
- 시스템 상태 s를 (h, p)로 분해하고, h∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기