유리 재료 과학 문헌에서 NLP 기반 지식 발굴
초록
본 논문은 무기 유리 분야의 논문 텍스트와 이미지 데이터를 자동으로 이해하고 정밀 지식을 추출하기 위해 자연어 처리(NLP)와 이미지 클러스터링 기법을 결합한 프레임워크를 제시한다. LDA를 이용해 초록을 주제별로 분류하고, 캡션 클러스터 플롯(CCP)으로 이미지와 플롯을 시각적으로 요약한다. 또한 화학 원소 정보를 결합한 ‘원소 지도’를 제공해 구성‑구조‑가공‑특성 데이터스페이스를 효율적으로 탐색한다.
상세 분석
이 연구는 재료 과학 특히 무기 유리 분야에서 축적된 방대한 비정형 데이터를 구조화하고 검색 가능하게 만드는 데 초점을 맞추었다. 먼저 저자들은 논문의 초록을 전처리한 뒤 잠재 디리클레 할당(LDA) 모델을 적용해 토픽을 자동 추출하였다. LDA는 단어-문서 행렬을 확률적 토픽 분포로 변환함으로써, 서로 다른 논문 간의 의미적 연관성을 정량화한다. 토픽 수는 퍼플렉시티와 코히런스 점수를 동시에 고려해 최적화했으며, 결과적으로 12개의 주요 토픽이 도출되었다. 각 토픽은 ‘유리 전이 온도’, ‘광학 특성’, ‘고온 가공’, ‘구조 모델링’ 등 무기 유리 연구의 핵심 영역을 반영한다.
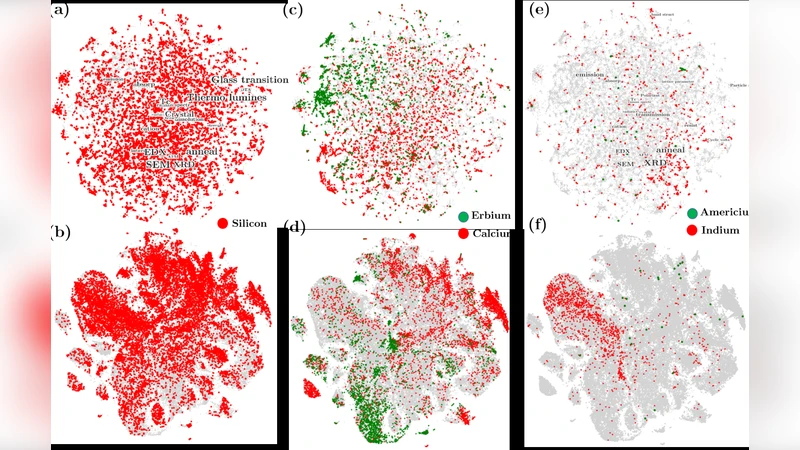
이미지 측면에서는 논문에 포함된 캡션 텍스트를 추출하고, TF‑IDF 기반 벡터화 후 K‑means 클러스터링을 수행하였다. 클러스터링 결과를 2‑차원 t‑SNE 혹은 UMAP으로 시각화한 것이 캡션 클러스터 플롯(CCP)이다. CCP는 동일한 실험적 맥락이나 데이터 유형(예: X‑ray 회절 패턴, 열분석 곡선, 현미경 사진)으로 묶인 이미지들을 한눈에 파악하게 해준다. 특히, 이미지와 캡션이 별도로 저장된 경우에도 텍스트 기반 클러스터링을 통해 이미지의 의미적 위치를 재구성할 수 있다.
핵심적인 혁신은 ‘원소 지도(Elemental map)’이다. 저자들은 각 논문의 텍스트와 캡션에서 화학 원소 기호를 정규 표현식으로 추출하고, 이를 LDA 토픽과 CCP 클러스터에 매핑한다. 결과적으로 특정 원소(예: Si, B, Al)가 주로 등장하는 토픽과 이미지 클러스터를 시각화함으로써, 원소‑주제‑이미지 간의 연관성을 직관적으로 보여준다. 이는 새로운 조성 설계나 가공 조건을 탐색할 때, 기존 문헌에서 어떤 원소 조합이 어떤 구조·특성과 연결되는지를 빠르게 파악할 수 있게 한다.
기술적 구현 측면에서는 Python 기반의 spaCy, gensim, scikit‑learn, matplotlib, seaborn 등을 활용했으며, 데이터 파이프라인은 텍스트 정제 → 토픽 모델링 → 캡션 벡터화 → 클러스터링 → 시각화 순으로 구성되었다. 또한, 웹 인터페이스를 통해 사용자는 키워드 검색, 토픽 필터링, 이미지 클러스터 탐색, 원소 지도 조회 등을 실시간으로 수행할 수 있다.
이 프레임워크는 무기 유리뿐 아니라 다른 재료 과학 분야에도 확장 가능하다. 핵심은 (1) 비정형 텍스트와 이미지 정보를 동일한 벡터 공간에 매핑하고, (2) 화학적 메타데이터와 결합해 다차원 탐색 지도를 생성한다는 점이다. 따라서 재료 설계자가 기존 문헌에서 숨겨진 지식을 효율적으로 발굴하고, 데이터‑구동형 재료 발견 파이프라인에 바로 통합할 수 있다.