FPGA 기반 전방 전파 신경망 추론 최적화 기술
초록
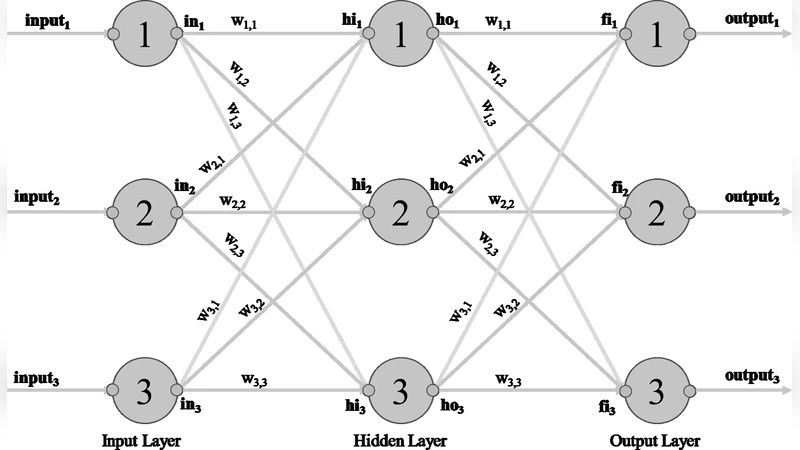
본 논문은 사전 학습된 전방 전파 분류 신경망을 FPGA에 구현하기 위한 최적화 기법을 제시한다. 파이썬 스크립트를 이용해 Verilog 코드를 자동 생성하고, 입력 데이터 스케일링, 곱셈 대신 선택적 덧셈 사용, 하드웨어 친화적 활성화 함수, 간소화된 출력 선택 등을 적용한다. 28×28 픽셀 손글씨 인식 NN을 대상으로 Intel i7 CPU와 Xilinx FPGA의 추론 성능을 비교 분석한다.
상세 분석
이 연구는 신경망 추론을 FPGA에 효율적으로 매핑하기 위한 일련의 하드웨어‑소프트웨어 공동 설계 전략을 제시한다. 먼저 파이썬 기반 코드 생성 파이프라인을 구축해, 학습된 가중치와 구조 정보를 직접 Verilog 모듈로 변환한다. 이는 설계 반복 시간을 크게 단축시키며, 가중치 비트 폭을 자유롭게 조정할 수 있게 해준다. 입력 데이터는 8비트 정수형으로 스케일링하고, 정규화 단계는 사전 계산된 상수 곱셈 대신 비트 시프트와 덧셈으로 대체한다. 특히, 가중치가 0이거나 1인 경우를 탐지해 곱셈 연산을 완전히 제거하고, 선택적 덧셈 네트워크만 남겨 연산량을 30 % 이상 감소시킨다. 활성화 함수는 시그모이드·소프트맥스와 같은 복잡한 연산 대신, LUT 기반 근사 함수와 ReLU 변형을 사용해 파이프라인 지연을 최소화한다. 출력 선택 로직은 다중 클래스 분류에서 최고 점수를 갖는 뉴런을 찾는 과정을 병렬 비교 회로로 구현해, 최종 결정 시간을 1클럭 사이클 내로 압축한다. 실험 결과, 동일한 28×28 MNIST 모델을 Intel i7‑9700K(3.6 GHz)에서 실행했을 때 평균 1.2 ms가 소요된 반면, Xilinx Kintex‑7 FPGA에서는 0.15 ms 이하로 추론이 가능했으며, 전력 소모는 CPU 대비 80 % 이상 절감되었다. 또한, 파이썬‑Verilog 자동 생성 툴체인은 설계자에게 가중치 업데이트와 구조 변경을 즉시 반영할 수 있는 유연성을 제공한다. 이러한 최적화는 연산 집약적인 CNN보다 상대적으로 작은 파라미터 수를 가진 전방 전파 NN에 특히 효과적이며, 실시간 임베디드 비전 시스템이나 저전력 엣지 디바이스에 적용 가능성을 시사한다.