다중요소 장거리 의존성 탐구: SPk 언어로 본 LDD 특성 분석
본 논문은 Strictly k‑Piecewise(SPk) 언어를 이용해 다양한 장거리 의존성(LDD) 특성을 가진 합성 데이터셋을 생성하고, 상호정보(mutual information)를 통해 LDD의 구조적 특성을 정량화한다. k값, 의존 거리, 어휘 규모, 금지 서열, 데이터 양이 LDD 특성에 미치는 영향을 실험적으로 분석하고, Transformer‑XL과 AWD‑LSTM 두 모델을 대상으로 다중요소(L > 2) 의존성을 학습할 때의 성능…
저자: Abhijit Mahalunkar, John D. Kelleher
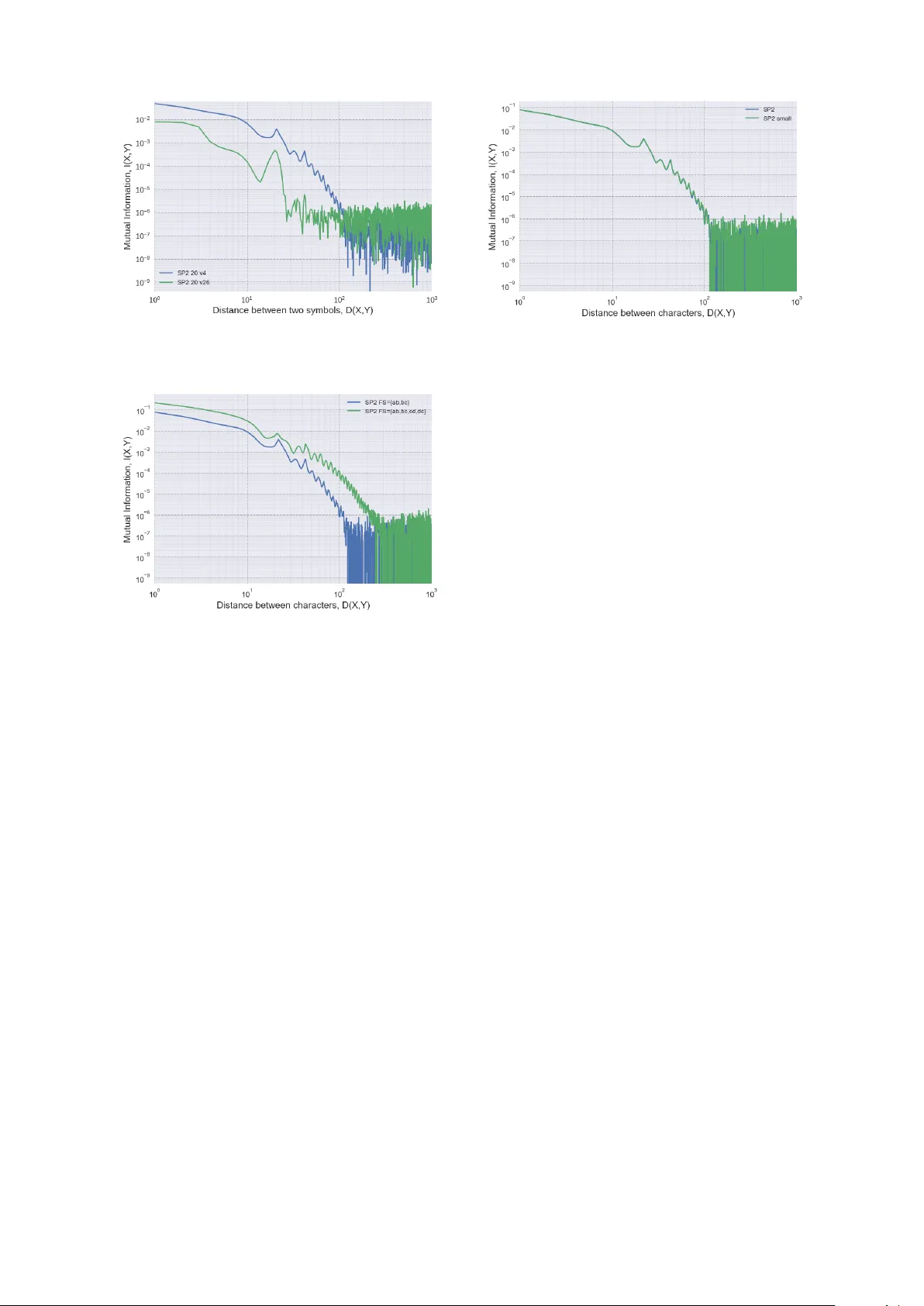
본 논문은 장거리 의존성(Long‑Distance Dependencies, LDD) 연구에 있어 기존 자연언어 코퍼스가 제공하는 제한된 통제력을 보완하고자, 형식언어 이론의 하위 클래스인 Strictly k‑Piecewise(SPk) 언어를 활용한 합성 데이터셋 생성 방법을 제안한다. SPk 언어는 알파벳 Σ와 허용되는 k‑subsequence 집합 G_SPk, 그리고 금지 서열(F)로 정의되며, k는 의존에 참여하는 요소의 수를 직접 지정한다. 예를 들어, k=2는 전통적인 두 요소 의존(주어‑동사 일치 등)을, k=4·16은 복합적인 체인형 의존을 모델링한다.
데이터셋 생성은 foma와 파이썬 스크립트를 이용해 문자열 길이와 어휘 규모, 금지 서열을 자유롭게 조절하면서 수행되었다. 각 데이터셋은 문자열들의 집합이며, 전체 토큰 수(|dataset|)는 문자열 길이와 개수의 합으로 정의된다.
LDD 특성 분석을 위해 저자는 상호정보(mutual information, MI)를 거리 D에 따라 계산하는 알고리즘을 설계하였다. 시퀀스 X와 Y를 각각 거리 D만큼 오프셋을 두고 슬라이딩 분할하고, 각 쌍 (X
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기