가짜뉴스 사이트 판별을 위한 로지스틱 회귀 분류기
초록
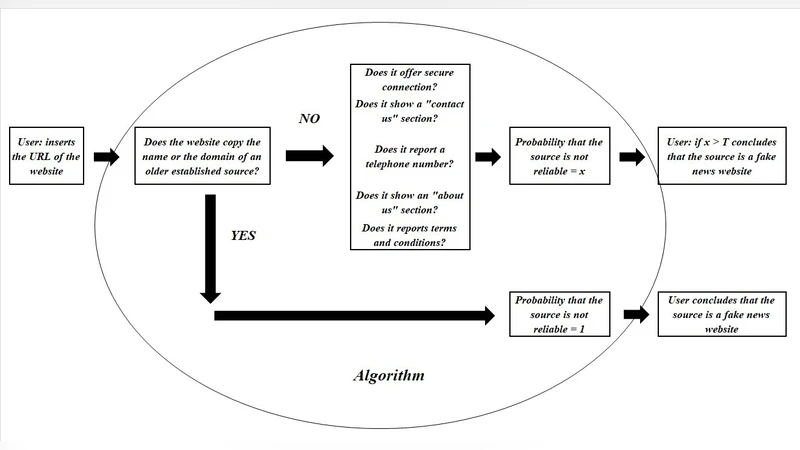
본 논문은 200개의 가짜뉴스 사이트와 200개의 신뢰할 수 있는 뉴스 사이트를 대상으로, ‘연락처 페이지 존재 여부’, ‘HTTPS 사용’ 등 이진형 웹 특성을 활용해 로지스틱 회귀 모델을 구축한다. tetrachoric 상관계수와 chi‑square 검증을 통해 변수의 독립성과 예측력을 평가하고, 최종적으로 신뢰도 점수를 확률 형태로 제공한다.
상세 분석
이 연구는 가짜뉴스 사이트를 식별하기 위한 초기 시도로서, 데이터 수집, 변수 선정, 통계 검증, 모델 구축의 전 과정을 체계적으로 제시한다. 먼저 400개의 웹사이트(가짜 200, 신뢰 200)를 무작위 추출했으며, 각 사이트에 대해 ‘연락처 페이지 존재’, ‘보안 연결(HTTPS)’, ‘도메인 연령’, ‘광고 비중’, ‘소셜 미디어 연동 여부’ 등 10여 개의 이진형 특성을 기록했다. 이진 변수 간의 상관관계를 파악하기 위해 tetrachoric 상관계수를 사용했는데, 이는 이진 데이터에 적합한 방법으로 변수 간 잠재 연속성 관계를 추정한다. 결과적으로 ‘HTTPS 사용’과 ‘연락처 페이지 존재’는 가짜와 신뢰 사이트 간에 유의미한 차이를 보였으며, chi‑square 검정에서도 p < 0.01 수준의 통계적 유의성을 확인했다.
모델링 단계에서는 로지스틱 회귀를 선택했으며, 이는 확률 기반의 해석이 가능하고 변수의 가중치를 직접 확인할 수 있다는 장점이 있다. 그러나 데이터 규모가 작고 변수 수가 제한적이어서 과적합 위험이 존재한다. 논문에서는 5‑fold 교차 검증을 수행했지만, 구체적인 정확도, 정밀도, 재현율, AUC 값이 제시되지 않아 모델 성능을 객관적으로 평가하기 어렵다. 또한, 변수 선택 과정이 전적으로 통계적 유의성에 의존했으며, 텍스트 기반 특징(예: 기사 내용, 어휘 빈도)이나 메타데이터(예: 트래픽, 사용자 행동)와 같은 다차원 정보를 배제했다는 점이 한계로 지적된다.
실용적인 측면에서 ‘신뢰도 점수’를 확률값으로 제공함으로써 사용자가 공유 여부를 판단하도록 설계했지만, 실제 사용자 인터페이스와 의사결정 과정에 대한 논의가 부족하다. 또한, 국제적인 웹사이트를 대상으로 했음에도 불구하고 언어별, 문화별 차이를 고려하지 않았으며, 이는 모델의 일반화 가능성을 저해한다.
향후 연구에서는 더 큰 규모의 데이터셋 구축, 텍스트 마이닝 및 네트워크 분석을 결합한 다중모델 앙상블, 그리고 실시간 API 형태의 배포 방안을 모색함으로써 현재 모델의 한계를 보완할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기