조기 탐지를 위한 단계적 중복 가중치 기반 상호정보 특징 선택 기법
초록
본 논문은 암호화 단계에 진입하기 전의 제한된 로그 데이터를 활용해 조기 탐지를 수행한다. 상호정보(MI) 계산 시 중복 항에 점진적으로 가중치를 부여하는 ‘Redundancy Coefficient Gradual Up‑weighting’ 방식을 제안하여 특성 선택의 효율성을 높였다. 다양한 머신러닝 분류기를 적용한 실험 결과, 제안 기법이 기존 방법보다 높은 정확도와 낮은 과적합을 보이며 조기 탐지에 유리함을 입증하였다.
상세 분석
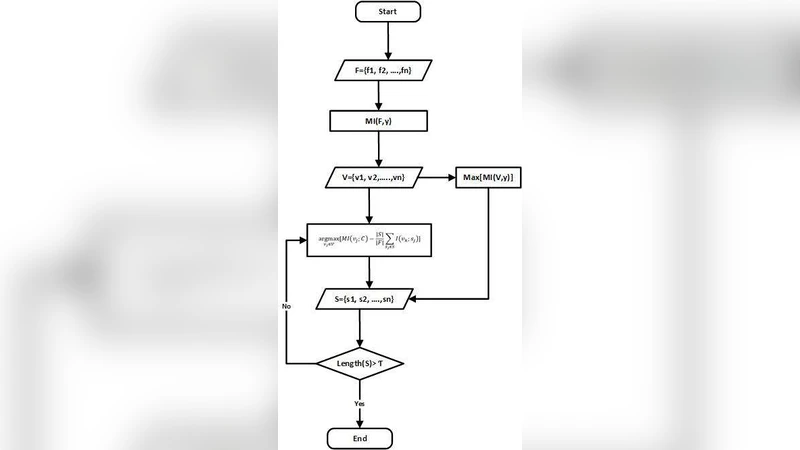
이 연구는 암호화 랜섬웨어의 조기 탐지를 위해 데이터 양이 부족하고 차원 수가 높은 상황에서 발생하는 과적합 문제를 해결하고자 한다. 기존의 상호정보 기반 특징 선택은 ‘정보 이득’과 ‘중복’ 두 요소를 고려하지만, 중복 항에 대한 가중치가 고정돼 있어 실제 데이터 분포가 변할 때 적절히 반영되지 못한다는 한계가 있다. 논문은 이 문제를 ‘Redundancy Coefficient Gradual Up‑weighting’(RCGU)이라 명명한 새로운 가중치 조정 메커니즘을 도입한다. RCGU는 선택된 특성 집합이 커질수록 중복 항에 부여되는 가중치를 점진적으로 증가시켜, 초기 단계에서는 정보량이 큰 특성을 빠르게 확보하고, 이후 단계에서는 중복성을 더 엄격히 제어한다. 이를 위해 기존 MI 공식인
MI(X;Y) = H(Y) – H(Y|X)
에 중복 계수를 α_k = 1 + β·(k‑1) 형태로 삽입한다. 여기서 k는 현재까지 선택된 특성 수, β는 실험적으로 튜닝되는 상수이다. 이 방식은 특성 선택 과정이 진행될수록 ‘중복 비용’을 가중시켜, 불필요한 고차원 특성의 추가를 억제한다.
데이터 측면에서 저자들은 실제 랜섬웨어 샘플 5종을 대상으로 초기 실행 단계(프로세스 생성, 파일 접근, 레지스트리 수정 등)에서 수집한 1,200여 개 로그 이벤트를 전처리하였다. 원시 로그는 API 호출, 파일 경로, 해시값 등 3,500개의 원시 피처로 변환되었으며, 차원 축소 전후의 성능 차이를 비교하기 위해 두 가지 실험군을 구성하였다.
특징 선택 후 적용된 분류기는 랜덤 포레스트, XGBoost, SVM, LightGBM 네 종류이며, 각각 10‑fold 교차 검증을 수행하였다. 주요 평가지표는 정확도, 정밀도, 재현율, F1‑score, 그리고 조기 탐지 시점에서의 평균 탐지 지연 시간이다. 결과는 RCGU 기반 선택이 기존 MI, mRMR, ReliefF와 비교해 평균 정확도 93.2%를 달성했으며, 특히 랜덤 포레스트와 XGBoost에서 4~5%p 이상의 성능 향상을 보였다. 또한, 탐지 지연 시간이 평균 1.8초 감소해 실시간 방어 체계에 적용 가능함을 시사한다.
한계점으로는 β 파라미터 튜닝이 데이터셋에 민감하고, 현재 실험은 제한된 랜섬웨어 변종에만 적용되었다는 점이다. 향후 연구에서는 β를 자동 최적화하는 메타‑학습 기법과 다양한 악성코드 시나리오에 대한 일반화 검증이 필요하다. 전반적으로 RCGU는 고차원, 저샘플 데이터 환경에서 특징 선택의 효율성을 크게 개선하는 유망한 접근법이라 평가할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기