온라인 카드 결제 사기 탐지를 위한 데이터 마이닝 최신 동향과 과제
초록
본 설문은 2009‑2020년 사이 발표된 45편의 논문을 분석해, 카드 결제 사기 탐지에 적용된 데이터 마이닝·머신러닝 기법을 비즈니스 영향, 행동 프로파일링, 개념 드리프트 대응, 클래스 불균형 처리 등 세 가지 핵심 과제로 분류한다. 비용 민감 학습, 거래‑가치 기반 손실 모델, 특성 선택 전략, 적응형 학습 프레임워크 등을 정리하고, 주요 분류 알고리즘의 성능을 비교한다.
상세 분석
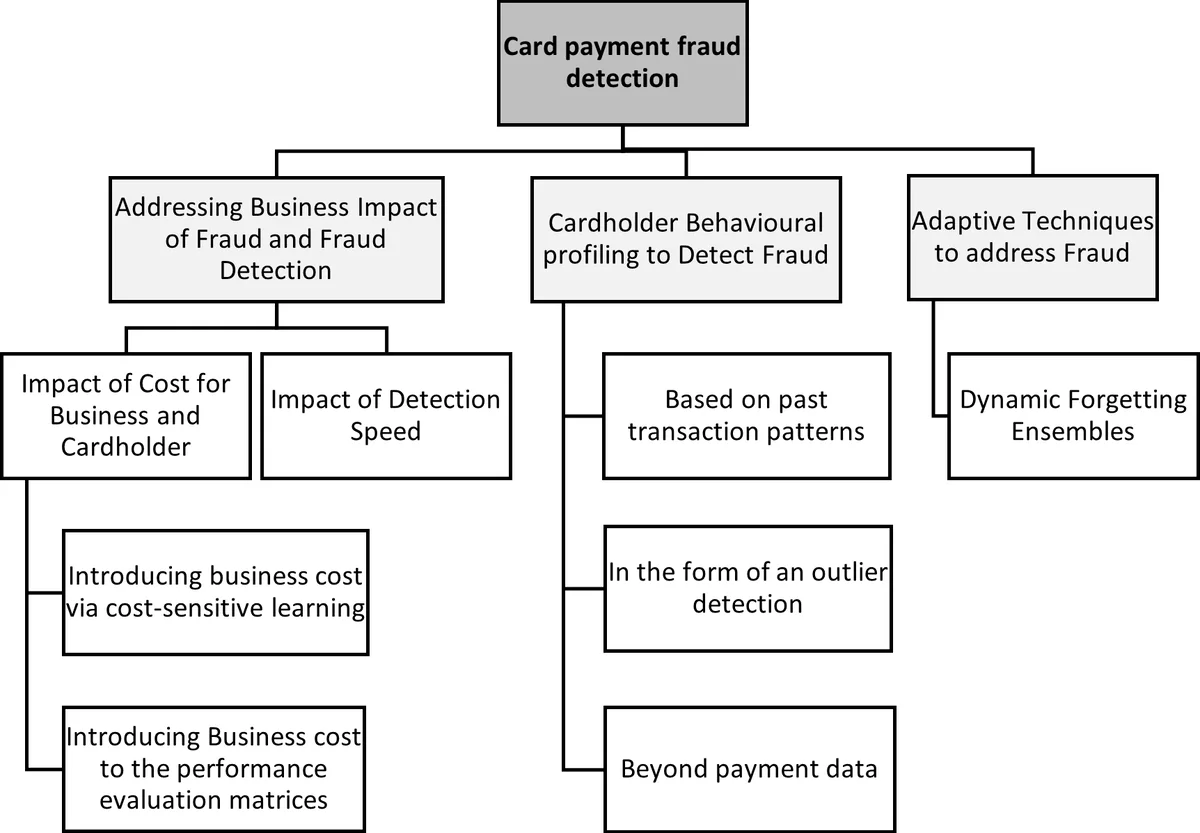
이 설문은 기존 연구가 사기 탐지를 단순 정확도 향상에만 초점을 맞추는 경향을 비판하고, 실제 운영 환경에서 발생하는 ‘비즈니스 비용’과 ‘실시간 지연’이라는 두 가지 핵심 제약을 명시적으로 모델링하도록 유도한다. 특히 비용 민감 학습(cost‑sensitive learning) 접근법을 상세히 검토한다. 연구자들은 거래 금액을 기반으로 오탐(False Positive)과 누락(False Negative)의 비용을 차등 부여하고, 이를 손실 함수에 통합해 모델을 학습한다. 예를 들어, Olowookere와 Adewale, Bahnsen 등은 트랜잭션 가치에 비례한 비용 행렬을 사용해 의사결정 트리와 베이지안 네트워크의 분할 기준을 조정하였다. 이러한 방법은 사기 탐지 시스템이 실제 금융기관이나 전자상거래 플랫폼에서 발생하는 금전적 손실을 최소화하도록 설계되었다는 점에서 실용적이다.
행동 프로파일링 측면에서는, 정상 거래의 행동 패턴을 먼저 모델링하고, 이를 기준으로 이상 행동을 탐지하는 ‘정상‑기반’ 접근이 강조된다. 연구자들은 시간대, 구매 금액 분포, 카트 이탈 비율, 장바구니 구성 등 다차원적인 특성을 추출하고, 차원 축소 기법(PCA, Autoencoder)이나 선택적 특성 중요도 평가를 통해 모델 복잡도를 낮추었다. 특히, 시계열 특성을 활용한 LSTM·GRU 기반 딥러닝 모델이 최근에 주목받고 있으며, 이는 사기 패턴이 시간에 따라 변동하는 ‘컨셉 드리프트(concept drift)’에 대응한다는 장점이 있다.
클래스 불균형 문제는 사기 거래가 전체의 0.1% 이하에 불과한 극단적인 상황에서 발생한다. 설문은 오버샘플링(SMOTE, ADASYN), 언더샘플링, 비용 민감 학습, 앙상블(Boosting, Bagging) 등 다양한 완화 기법을 비교한다. 특히, XGBoost와 LightGBM 같은 그래디언트 부스팅 모델이 불균형 데이터에서 높은 AUC와 Recall을 달성한다는 점을 강조한다.
분류 알고리즘 비교에서는 전통적인 로지스틱 회귀, 의사결정 트리, SVM에 더해, 랜덤 포레스트, Gradient Boosting, 딥러닝(MLP, CNN, RNN) 등 최신 기법들의 성능 차이를 정량적으로 제시한다. 대부분의 연구가 F1‑Score와 AUC를 주요 지표로 삼았으며, 실시간 처리 요구를 고려해 모델 추론 시간도 평가 대상에 포함시켰다.
마지막으로, 설문은 현재 연구가 ‘실시간 비용‑민감·적응형·불균형 처리’를 동시에 만족시키는 통합 프레임워크를 아직 제시하지 못했으며, 데이터 프라이버시(예: GDPR)와 설명 가능 인공지능(XAI) 요구가 증가하고 있음을 지적한다. 향후 연구는 연합 학습(Federated Learning)과 설명 가능한 모델을 결합해, 은행·결제 게이트웨이 간 데이터 공유 없이도 고성능 사기 탐지를 구현하는 방향을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기