음성 기반 감정·우울증 인식을 위한 강건 딥 네트워크 EmoAudioNet
초록
본 논문은 음성 신호의 시간‑주파수 표현과 스펙트로그램 이미지를 동시에 활용하는 두 흐름(two‑stream) CNN 구조인 EmoAudioNet을 제안한다. RECOLA와 DAIC‑WOZ 데이터셋에서 arousal·valence 연속 감정 예측과 우울증(Depression) 분류·중증도 추정에 대해 기존 최첨단 방법들을 능가하거나 동등한 성능을 보이며, 특히 Pearson Correlation Coefficient와 RMSE/MAE 지표에서 우수함을 입증한다. 데이터 증강(노이즈 혼합·피치 변환)과 엔드‑투‑엔드 학습을 통해 모델의 일반화와 강건성을 강화하였다.
상세 분석
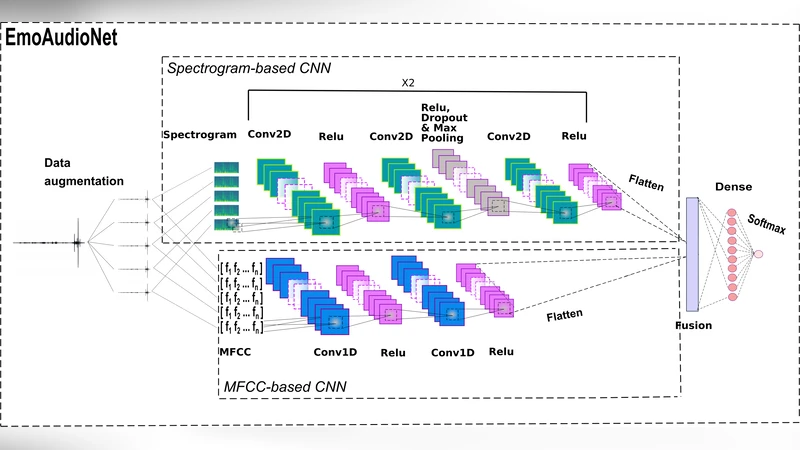
EmoAudioNet은 음성 신호를 두 가지 서로 보완적인 방식으로 처리한다. 첫 번째 흐름은 스펙트로그램 기반 CNN으로, 입력 음성을 256개의 짧은 구간으로 나누어 FFT를 수행하고, Hamming 윈도우를 적용한 후 1900×1200 색상 이미지로 변환한다. 이 이미지는 224×224 크기로 리사이즈되어 2D 컨볼루션 블록(Conv‑ReLU‑Conv‑ReLU‑Dropout‑MaxPool‑Conv‑ReLU) 두 개를 거쳐 1152 차원의 고수준 특징 벡터를 생성한다. 두 번째 흐름은 MFCC 기반 CNN이다. 음성을 2.5 초 프레임(500 ms 간격)으로 나누어 멜 스케일로 변환한 뒤 DCT를 적용해 177 차원의 cepstral 특징을 추출하고, 1D 컨볼루션(Conv‑ReLU‑Conv‑ReLU)으로 2816 차원의 특징 벡터를 만든다. 두 흐름의 출력은 단순 연결(concatenation) 후 완전 연결층에 입력되어 최종 클래스 확률을 산출한다.
학습 단계에서는 Adam 옵티마이저와 교차 엔트로피 손실을 사용하며, 배치마다 스펙트로그램과 MFCC 특징을 동시에 업데이트한다. 데이터 희소성을 극복하기 위해 두 가지 오디오 증강 기법을 적용한다. 첫 번째는 백색 잡음·환경 잡음을 α ∈ {0.01, 0.02, 0.03} 비율로 혼합하는 것이며, 두 번째는 피치를 0.5, 2, 5 세미톤씩 낮추는 피치 시프팅이다. 이러한 증강은 모델이 다양한 음성 변형에 대해 강건하도록 돕는다.
성능 평가에서는 RECOLA 데이터셋의 연속 감정(아로우절·밸런스) 예측에서 Pearson Correlation Coefficient(PCC)를 사용했고, DAIC‑WOZ에서는 우울증 이진 분류(F1‑score)와 중증도 회귀(RMSE, MAE)를 측정했다. 결과적으로 EmoAudioNet은 스펙트로그램 단일 CNN이나 MFCC 단일 CNN보다 높은 PCC(아로우절 ≈ 0.70, 밸런스 ≈ 0.78)와 낮은 RMSE/MAE를 기록했으며, 기존 최첨단 모델(Yang et al., Salekin et al.)과 비교했을 때 동일하거나 더 나은 성능을 보였다. 특히, 두 흐름을 결합함으로써 시간‑주파수 텍스처와 전통적인 음향 특징을 동시에 학습할 수 있어, 감정의 미세한 변화를 포착하고 우울증과 같은 정서 장애의 음성적 표식을 효과적으로 구분한다는 점이 핵심 인사이트다.
한계점으로는 모델 파라미터가 비교적 작지만, 스펙트로그램 이미지 생성 과정에서 메모리와 연산 비용이 크게 증가한다는 점이다. 또한, 데이터셋이 프랑스어와 영어에 국한돼 있어 다언어·다문화 환경에서의 일반화 검증이 필요하다. 향후 연구에서는 경량화된 시각‑음향 융합 모듈, 멀티‑모달(텍스트·영상) 통합, 그리고 실시간 스트리밍 적용을 목표로 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기