머신러닝으로 예측하는 옥수수 수량과 질산염 손실
초록
본 연구는 APSIM 시뮬레이션 데이터를 활용해 사전 시즌에 옥수수 수량과 질소 손실을 예측할 수 있는 다섯 가지 머신러닝 메타모델을 평가하였다. 300만 개 이상의 유전자·환경·관리 조합을 학습한 결과, 랜덤 포레스트가 수량은 14 %의 상대적 RMSE, 질소 손실은 55 %의 RMSE로 가장 높은 정확도를 보였다. 학습 데이터 규모가 0.5 백만에서 1.8 백만으로 증가할 때 수량 예측 오차는 10‑40 % 감소했지만, 질소 손실 예측은 일관된 개선이 없었다. 변수 중요도 분석에서는 기상, 토양, 관리, 초기 조건이 모두 비슷한 비중을 차지했으며, 모델 앙상블은 약간의 성능 향상만 제공하였다.
상세 분석
이 논문은 기존 작물 시뮬레이션 모델인 APSIM이 제공하는 방대한 시뮬레이션 결과를 메타모델링하는 접근법을 제시한다. 먼저 5가지 대표적인 머신러닝 알고리즘—랜덤 포레스트(RF), 그래디언트 부스팅 머신(GBM), 서포트 벡터 머신(SVM), 인공신경망(ANN), 그리고 k‑최근접 이웃(k‑NN)—을 선택하고, 각각을 사전 시즌에 이용 가능한 입력 변수(기후 요인, 토양 물리·화학 특성, 파종·비료·관개 등 관리 정보, 초기 토양 질소·수분 상태)와 목표 변수(수량, 질산염 손실) 사이의 매핑 함수로 학습시켰다. 데이터는 3 백만 개 이상의 시나리오를 포함했으며, 이를 70 % 훈련·30 % 검증으로 분할하였다.
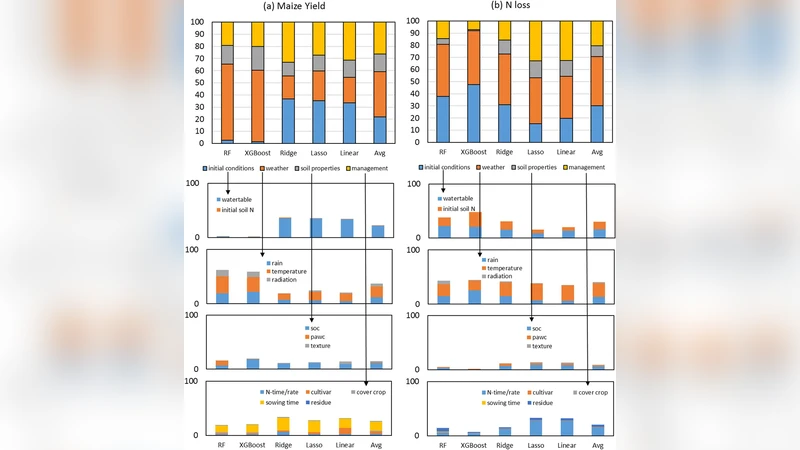
예측 정확도는 상대 RMSE(RRMSE)로 평가했으며, 수량에 대해서는 RF가 14 %의 RRMSE로 가장 우수했다. 이는 RF가 비선형 상호작용과 변수 중요도 추정에 강점이 있기 때문으로 해석된다. 반면 질소 손실은 전체적으로 높은 오차(최소 55 % RRMSE)와 변동성을 보였으며, 이는 질소 이동·손실 메커니즘이 복잡하고 시뮬레이션 자체의 불확실성이 크기 때문일 가능성이 있다.
데이터 규모에 대한 민감도 분석에서는 수량 예측이 데이터 양에 따라 명확히 개선되는 반면, 질소 손실은 데이터 증가에도 일관된 개선이 나타나지 않았다. 이는 질소 손실이 기상 변동성, 토양 미세구조, 미생물 활동 등 고차원 요인에 크게 의존하고, 현재 입력 변수만으로는 충분히 설명되지 않음을 시사한다.
변수 중요도는 각 모델별 SHAP 값과 평균 감소된 불순도 등을 이용해 정량화했으며, 결과는 기상(강수량, 온도), 토양(유기물 함량, 텍스처), 관리(비료 투입량, 파종 시기) 및 초기 토양 질소·수분 상태가 모두 비슷한 수준으로 기여한다는 점을 보여준다. 이는 사전 시즌에 어느 한 변수만을 강조하기보다 다변량 정보를 균형 있게 활용해야 함을 의미한다.
마지막으로 여러 모델을 평균하거나 가중합한 앙상블을 적용했을 때, 수량 예측에서는 평균 2‑3 % 정도의 추가 개선이 있었으며, 질소 손실에서는 거의 차이가 없었다. 이는 개별 모델 간 오류가 크게 상관관계가 낮지 않아 앙상블 효과가 제한적임을 나타낸다.
전체적으로 이 연구는 대규모 시뮬레이션 데이터를 활용한 메타모델링이 사전 시즌 의사결정 지원 도구로서 실용적 가능성을 보여주지만, 질소 손실과 같은 복합 환경 변수에 대해서는 추가적인 데이터(예: 현장 센서, 미생물 지표)와 모델 구조 개선이 필요함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기